The GHC developers are very pleased to announce the availability
of the release candidate for GHC 9.14.2. Binary distributions, source
distributions, and documentation are available at downloads.haskell.org and
via GHCup.
GHC 9.14.2 is a bug-fix release fixing many issues of a variety of
severities and scopes, including:
Fixed a CorePrep miscompilation that could project a field out of an absent
dictionary, resulting in a segfault (#25924)
Fixed demand analysis giving an absent demand to an argument that was still
used by the function’s stable unfolding, which could cause a run-time crash
(#26416)
Numerous fixes for register allocation and Cmm register-conflict analysis
bugs, preventing incorrect code generation and corruption of vector registers
when spilling and reloading (#26411, #26526, #26537, #26542, #26550, #26668)
Many NGG fixes on AArch64: MOVK clobbering live values (#26980), register
clobbering and an incorrect overflow bit in MUL2 (#27046, #27047), and
incorrect sign extension (#26978) and unsigned right shift (#26979) at sub-word
widths
Fixed several black hole handling bugs that could lead to deadlocks or crashes
in multithreaded programs, showing up as hangs or “END_TSO_QUEUE object
entered” errors (#26922, #26936)
Fixed a stack alignment bug on x86 that could cause segfaults or corrupted
registers when using AVX/AVX-512 vector code (#26595, #26822)
Fixed an “unknown/strange object” crash in the compacting garbage collector
(#27434)
Fixed a regression that caused overloaded functions to no longer be
specialised as effectively as in previous releases, hurting runtime
performance (#26831)
Fixed exponential-time desugaring of nested case expressions (#27383, #20251)
Fixes for several compiler panics, including issues with SetLevels (#26681),
the type-class specialiser (#26682), mkTick (#26772, #27121) and
CoreToStg (#27182, #27386)
Fixed cast worker/wrapper incorrectly firing on INLINE functions (#26903)
Fixed negative type literals causing the compiler to hang (#26861)
Fixed associated type family and data family instance changes not triggering
recompilation (#26183, #26705)
Improvements to determinism of compiler output, including the order in which
:info lists instances (#26846, #26858, #26877, #27532)
Fixed split sections support on Windows (#26696, #26494) and the LLVM
backend (#26770)
The JavaScript backend now supports more than 128 registers, fixing runtime
ReferenceError failures for functions taking very many arguments (#26558)
Fixes for the Wasm backend, and the RISC-V and PowerPC native code generators
… and many more
A full accounting of these fixes can be found in the release notes. As
always, GHC’s release status, including planned future releases, can be found on
the GHC Wiki status.
This release candidate will have a two-week testing period. If all goes well
the final release will be available the week of 13 August 2026.
We would like to thank these sponsors and other anonymous contributors
whose on-going financial and in-kind support has facilitated GHC maintenance
and release management over the years. Finally, this release would not have
been possible without the hundreds of open-source contributors whose work
comprise this release.
As always, do give this release a try and open a ticket if you see
anything amiss.
In the previous articles I talked about the game of Nim, a very simple
game for two players:
There are some piles of beans
Players alternate turns
A legal move is to take any number of beans from one pile
Whoever takes the last bean wins
I wrote about how Nim could be extended to include certain types of
“infinite” piles while still remaining a sensible game. This involved
introducing green tokens that could be replaced with any number of
beans, then square tokens that could be replaced with any number of
green tokens and beans, and so on.
Rather than think about an infinite family of different kinds of
tokens, there's a simple way to make them all the same sort of thing.
Imagine a game where the board is a track of squares, extending to the
right (and to the right only) as far as needed. Let's number the
squares: the leftmost one is , then and so on.
On some of the squares are coins. In this game, a player's legal
moves are to take one coin and move it some number of squares to the
left. Coins don't interfere with one another; any number of coins may
occupy a single space. As in Nim, the player who is able to make the last legal move
wins. In Nim that means taking the last bean; in this game it means
moving the last coin to the square.
This game is nothing but Nim, in a different form. A Nim game with
piles of and beans is exactly equivalent to the strip
game, with coins on squares and .
Removing four beans from a pile is isomorphic to moving a coin four
squares leftward.
A coin on square zero behaves like an empty pile of beans — no
further moves are possible for that coin / pile, and it has no further
effect on the game.
In Nim, we represented with a green token that could be replaced
with any number of beans:
In the strip game, we don't need special tokens. We represent
by adding a second strip, atop the first:
and the rule that a coin in the upper strip can be moved to
the left or to any space in the lower strip:
The picture above shows how to take all but six beans from a pile of .
Adding more strips gets us easily almost to :
The coin here represents a pile of beans.
If we were to stack a second grid on top of this one, and then add the rule that
a coin in the upper grid can be moved to any square in the lower grid,
then the lower-leftmost square in the upper grid would be equivalent to a
pile of beans, and the other squares in the upper grid would be variouls ordinals of the form
. Adding a third grid would get us up to , and a whole infinite stack of grids would get us an infinite cube that
would almost take us to .
We could then build an infinite four-dimensional stack of cubes to get to
and beyond, and so on to infinite dimensions, and that's the
construction I had in mind when I said was where the ordinals
start to get scary. But there's an easier way to proceed, which we'll
see in the next article.
Claude generated the green poker chip image. I used Inkscape to
transform its original chip illustration into the two kinds of coins.
Everything else in this article, including the
em-dash, was entirely human-generated. These disclosures are
ridiculous
In the NBA 2015–16 season, Steph Curry set the all-time
single-season record for three-point field goals, 402, completely
crushing the old record of 286. Curry's record still stands.
The record is an outlier that defies most comparisons, but here is
one: It is the equivalent of hitting 103 home runs in a Major League
Baseball season.
And it is an astonishing feat. But I wrote an article called
Steph Curry: fluke or breakthrough?
in which I compared Curry's feat with similar feats of the past,
including the one implied by the Times, Babe Ruth's 1920
single-season home run record, and concluded:
To make the same comparison as the authors of the Times article,
[Ruth's feat] is the equivalent of hitting 136 home runs in a Major
League Baseball season.
I also compared Curry's record with Joe Dimaggio's 1941 hitting
streak, Bob Beamon's world record long jump at the 1968 Olympic Games,
and Takeru Kobayashi's decade-long domination of competitive hot dog
eating. I analyzed these as being of two types: mere flukes, which
were never repeated, and breakthroughs, in which the athlete
discovered a new technique or approach that radically transformed the
sport itself. DiMaggio and Beamon's feats, I said, were flukes, but
Ruth's and Kobayashi's were breakthroughs.
At the end I asked the obvious question: was Steph Curry's new
three-point field goal record a fluke, or a breakthrough? I guessed
that it would turn out to have been a breakthrough.
I predicted:
Unless the league tinkers with the rules to
prevent it, we might expect the next generation of players to
regularly lead the league with 300 or 400 three-point shots in a
season. … I think it's likely that we'll see basketball enter a
new era of higher offense with more three-point shots, and that future
sport historians will look back on this season as a watershed.
I don't think I'm good at it and I don't think anyone else is. Most
people who try don't seem to revisit their old predictions to see if
they were correct, or to learn from their past errors, and the
people who listen to them never do this.
I don't know much about basketball, but
having made a clear prediction, I owe it to myself and my Gentle
Readers to revisit the prediction to see if I was correct.
Stephen Curry (diamonds)All other players (circles)
Each dot is one player in one season. Hovering on a dot shows you the
player to whom it belongs. The -axis shows the year in which
each season ended, the -axis the number of three-pointers the owner
recorded in that season. The blue diamonds are Curry's, gray dots are
everyone else's. The vertical blue hairline at the 2015–16 season
intersects Curry's all-time record of 402 three-pointers, aftyer which I wrote
the original article.
You can see a surprising jump in three-pointers in the three seasons of 1994–95
through 1996–97. In those seasons the league moved the three-point
line closer to the basket, moving it back again in 1997–98. In the
rest of this article I will ignore these.
The verdict
Was I right when I said the Curry's 402 would turn out to have been a
breakthrough? I think yes.
Looking at the dots on the chart, it's quite clear that something
changed. Up to 2015, the total of 250 was exceeded just six times:
four times by Curry and once each by Ray Allen and Klay Thompson.
(Remember we're ignoring 1995–7 when the rules were changed.) But
after 2015, that total was achieved 34 times in 10 seasons, by 19
different players.
I got some details wrong. I guessed:
we might expect the next generation of players to regularly lead the
league with 300 or 400 three-point shots in a season.
This hasn't happened. Last season Anthony Edwards led the league with
320, but this season's record, 273 by Don Knueppel, is much more
typical. Only Curry himself has regularly exceeded 300.
On the other hand, regarding Ruth, I pointed out:
Ruth's innovation was promptly imitated. In 1920, the #2 hitter hit
19 home runs and the #10 hitter hit 11, typical numbers for the
nineteen-teens. By 1929, the #10 hitter hit 31 home runs, which would
have been record-setting in 1919.
And something like this has happened. This season, the #10 players
each hit 224 three-pointers. These would have led the league in all but two
years prior to 2012–13. Before Curry, the all-time record was 269
(Ray Allen, 2005–06); two players exceeded that this year and three
last year.
Was it “a different game”?
Regarding the decade following the watershed 1920 baseball
season, I said:
It was a different game.
And it really seems like this hasn't happened in baskeball. Players
are certainly attempting and making more three-point shots, but they
haven't taken over the league the way sluggers did in the 1920s.
Total 3PFG attempts are up by 31,729, of which 11,765 succeeded,
producing 35,295 points. Total points were up by less than this,
32,823 — the three-pointers are cannibalizing some of the other scoring
opportunities.
In 2016 I observed:
Curry didn't get lucky this year; he had 40% more field goals
because he made almost 40% more attempts.
I concluded from this that Curry could continue to shoot more three-pointers
just by making more attempts, and that other players might similarly
shoot more three-pointers by making more attempts. This turned out to be
correct. Success rates haven't increased, attempts have. Just
looking at attempts is misleading because players seem to be playing
fewer games than they were in 2015–16. But the league leaders in
three-pointers per game are generally up over 2015–16. In that season, three
players averaged over three three-pointers per game (with Curry running away
with 5.1). This season, there were 13, and Luka Dončić hit 4.0.
On the other hand
I ended the previous article by saying:
I think it's likely that we'll see basketball enter a new era of
higher offense with more three-point shots, and that future sport
historians will look back on this season as a watershed.
The reasons I gave still seem solid, and I think this was basically
right. Over the last ten years I've read several articles complaining
about how reliance on the three-point shot is ruining basketball:
(It's fun to compare this with the similar complaints from the past hundred
years about home runs. There was a batch in the 1920s, and then
another crop in the years following 1998 when Sosa and McGwire both
broke the single-season home-run record.)
The chart was generated by Claude from my design, using
data I provided from Basketball Reference.
Everything else in this article, including the em-dash, was written entirely by
me.
At Tweag, we have been auditing Cardano smart contracts since 2021. We started
out reviewing contracts mostly by hand, but it did not take long before we began
building tooling to make our audits more efficient and systematic — most notably
cooked-validators, which we have maintained and improved
ever since. In its earliest form it could only handle one transaction at a time
and was built on top of plutus-apps — a library that has been
archived for a good while now. From this early reliance on a now deprecated
dependency, it grew over the years into the powerful framework it is today. At
its heart are convenient transaction bodies (or skeletons), focused solely
on what the user actually cares about, and several layers of automation that
build properly shaped and balanced transactions out of
them. On top of these sit fine-grained tweaks that alter skeletons in a
stateful way1 before submission (such as redirecting an output or
minting an additional token), an expressive LTL-inspired DSL that
schedules those tweaks at chosen points along a trace, and the automated attacks
built as instances of that DSL. The most recent improvement was to give this DSL
a proper semantics for negation and its derivatives, such as implication — the
subject of an upcoming post.
As painful as it is to admit, not every tool we built survived.
Pirouette, an experimental static analyser for Plutus Core, was
retired, and Graft, an attempt to generalize our LTL DSL to
a wider range of domains, has been on hold for a long while, waiting for
additional underlying logics and target domains. But even the tools that did not
last taught us a great deal, and each of them contributed to improving our
auditing expertise.
The smart-contract ecosystem did not stand still either. Developers were given
access to more advanced languages, such as Plutarch, a monadic take
on writing Plutus script through a high-level lambda calculus, sticking close to
Plutus Core, or Aiken, a DSL living outside of the Haskell world
specifically geared towards writing and testing smart contracts on
Cardano. Cardano itself kept growing underneath us through its
consecutive eras: Babbage brought reference inputs and inline
datums, Conway introduced a full governance system, and Dijkstra, with nested
transactions, is peeking over the horizon.
Through all of this we audited, we learned, and we occasionally stumbled — our
first audit of Minswap, where a critical vulnerability slipped
past us, is the case we keep coming back to. We also succeeded — more often than
not with critical findings of our own, growing and learning in the process,
while bringing increasing value to our customers. This post is a retrospective
on those five years. It is not a client-by-client account, but a look at the
recurring patterns we keep finding, the lessons we have drawn, and the way our
methodology evolved. Whether you are a smart-contract developer, a fellow
auditor, or simply someone who cares about high-assurance software in general
(or on Cardano in particular), we hope you take away something useful from this
retrospective.
Five years in numbers
Since our first Cardano audit in late 2021, we have carried out more than twenty
audits across the ecosystem, covering products such as decentralized exchanges,
stablecoins, lending protocols, oracles, governance rules, and even a
constitution script. Several clients came back for more than one round as their
protocols evolved, and not every engagement looked the same: most were
standalone smart-contract audits, while some others came with extra layers.
Marlowe, for instance, required not only the typical review of the
on-chain portion of the project, but also one of the Isabelle formal
model that came alongside it.
Across our standard smart-contract audits, we reported 276 findings. The
table below breaks them down by severity, using the same five-level scale we
apply in every report we deliver.
Severity
Findings
Critical
30
High
35
Medium
66
Low
95
Lowest
50
Total
276
The first noticeable element in the table is the 30 critical findings and
35 high-severity findings: issues severe enough that, left unaddressed,
would have dire consequences either for the administrators or for the users of
the protocols, if not both. Among those consequences, an attacker could, for
instance, be mistakenly allowed to drain or lock user funds, cause delays in the
life cycle of the product, or even fully empty pools of assets belonging to the
contract.
The second is the shape of the distribution: the majority of reported findings
sit at medium severity and below. These are smaller concerns that might seem
harmless in isolation, but can pile up to form real risks.
Severity is only one axis. We also classify every finding by its nature —
what kind of problem it is — which tells us as much about a codebase as the
severity does. We use five categories:
Vulnerabilities — directly exploitable flaws that an attacker can use to
break the protocol’s safety.
Implementation bugs — code that does not obey its specification, whether
or not the discrepancy turns out to be exploitable.
Design — issues rooted in the protocol’s architecture, which could cause
serious flaws, such as unnecessary hoops in the contract flow or unnecessarily
large transactions.
Unclear specification — missing, ambiguous, or undocumented expected
behaviour, which makes correctness impossible to assess. After all, a piece of
software can only be deemed sound with respect to a complete and unambiguous
specification.
Code quality — lack of readability, maintainability, or usage of good
coding practices. Theoretically low-impact issues, which could however hide or
even be responsible for deeper flaws.
Nature
Critical
High
Medium
Low
Lowest
Total
Vulnerabilities
24
12
6
2
0
44
Implementation bugs
5
5
10
8
0
28
Design
0
6
18
16
3
43
Unclear specification
1
11
16
31
11
70
Code quality
0
1
16
38
36
91
Total
30
35
66
95
50
276
The two axes line up almost diagonally, which makes sense. Vulnerabilities are
comparatively rare but concentrated at the top: 24 of our 30 critical findings
are outright exploitable flaws. At the other end, code quality is our single
largest category and sits almost entirely at low severity — each issue minor on
its own, but collectively a good measure of how much care a codebase has had. In
between, unclear specification stands out as the second-largest bucket, and it
is a theme we keep returning to: a surprising number of concrete bugs ultimately
trace back to behaviour that was poorly specified, or simply left out of the
specification altogether.
The diagonal shape, however, is a tendency and not a law; the off-diagonal cases
are what make the nature axis worth having. Notice the single occurrence of a
critical finding falling into the unclear specification category. Because the
contract in question relied on the order of its outputs to make decisions, an
attacker could manipulate the output order to duplicate an entry and vote with
more weight than they held. The only safeguard happened to be a legacy field
that, almost by accident, kept the positions distinguishable, and nothing in the
spec said it had that meaning; an unclear specification finding by nature, yet
critical in severity. At the opposite corner, two audits surfaced
vulnerabilities rated at low severity. One such occurrence was linked to the
existence of a peer with high privilege on the contract (the operator), who
could drain the protocol’s reserves at will. However dangerous this may be, the
development team already knew of it and had accepted it as an explicit design
trade-off, because the operator was assumed trusted (a pattern we see very
often, and systematically point out).
Severity measures impact in context; nature measures the kind of flaw and how to
prevent it. The two are correlated — hence the diagonal — but they answer
different questions, and where they diverge tends to be insightful.
Not every audit ends with a long findings list. Our review of CTez, the
only non-Cardano audit we ran, turned up nothing out of the ordinary — which,
although a one-off, and quite surprising, is a valid audit outcome
nonetheless. Marlowe sits at the other end of the spectrum: between
the contract review and the audit of its Isabelle formal model, it
yielded over a hundred findings on its own — which is why we did not include it
in the totals of the tables above. That count, however, says more about the
impressive size of the project than about its safety: the majority of those
findings sat at medium severity or below.
Are smart contracts getting safer?
As we’ve already mentioned, a great deal has changed on the Cardano side over
these five years. The chain has moved from era to era, each one adding
capabilities while pushing further towards built-in safety. Plutus has gone
through several versions, gaining new primitives along the way, and a variety of
new languages have appeared, offering a far more pleasant developer experience
while producing smaller, cheaper Plutus Core. Our own expertise, understanding,
and tooling have grown accordingly. What we have not said yet is that the
developers writing these contracts have improved too: the code we see is
steadily wider in scope, cleaner, and safer, written with more attention to
detail and care for the metrics that matter on Cardano, like transaction and
UTxO sizes.
All of this has changed both the quantity and the nature of the findings we
uncover.
Take the quantity first. There will be no table this time, and for a good
reason. To measure the trend properly, we would want, for each audit, the ratio
between its findings (ideally weighted by severity) and some measure of the
codebase it covered, such as its line count. An exact figure for that ratio is
out of reach: line counts are not comparable across the different languages we
audit, all having different degrees of verbosity, and we do not keep client code
once an engagement is over, so we would not even be able to dig up that number.
But across every engagement, the trend is clear: slowly but surely, that ratio
has come down over the years.
The nature of the findings has shifted too, and to see how, it helps to
understand the model the chain is built on. Cardano runs on the extended UTxO
(eUTxO) model, which differs from the account-based architecture familiar from
most other blockchains. Rather than mutating a global, account-based state, a
transaction consumes unspent outputs (UTxOs) and produces new ones, each
carrying a value and a piece of data called a datum, while on-chain scripts —
the smart contracts themselves — decide whether a transaction is allowed to
spend a given output. Ownership, then, is not an entry in a global ledger but a
question of which UTxOs sit at a given address. When that address corresponds to
the hash of a script, thus belonging to it, “ownership” really means that the
script’s logic runs — and gets to approve or reject the transaction — every time
one of its UTxOs is consumed.
We see fewer and fewer vulnerabilities that are inherent to this model and that
the community has since internalized, such as the well-known double
satisfaction attack, which used to be a common find: when
several instances of the same script run in one transaction, each could be
tricked into treating a single output as its own, not realizing the others saw
it the same way. Some other well-known vulnerabilities have disappeared outright
as the platform matured, like the chicken-and-egg situation of minting tokens
and sending them to a script in a single transaction — where the two scripts
could not each be aware of the other’s hash — finally resolved by multipurpose
scripts.
These classes did not simply fade on their own — we codified many of them.
Attacks we once reconstructed by hand for every engagement, such as datum
hijacking, double satisfaction, or token duplication, are
now expressed once and explored systematically using
cooked-validators, in the shape of tweaks scheduled along a
transaction trace, branching to various possible outcomes. Each new class we ran
into taught us something we folded back into the framework whenever possible, so
the next audit could start from a stronger baseline. The findings shaped the
tooling, and the tooling, in turn, increased our audit efficiency.
What remains tends to be of a different kind: mistakes specific to a contract’s
own domain logic, subtle issues introduced by aggressive optimization — decoding
builtin data by hand, or threading everything through continuation-passing style
to shrink the compiled output — and, above all, design flaws. However much
experience a team accumulates, something always seems to get in the way of an
optimal design — if such a thing even exists. It might be disagreements between
team members, turnover in the people involved, the sheer length of a project
with its successive rewrites and redesigns, budget constraints, or new
requirements surfacing halfway through development. Unfortunately, design issues
are also arguably the hardest and most costly to fix, since doing so often means
rewriting significant parts of a project — which is why they are left
unaddressed more often than other kinds of findings. We hope these findings
still prove useful — for future versions of the same project, for new projects,
or simply for sharpening the community’s collective understanding of how to
approach smart-contract design on Cardano.
Are we there yet?
While the story so far points to a clear improvement in the overall safety of
smart contracts, the journey is far from over. A new Cardano era, Dijkstra, lies
ahead, bringing new capabilities — and, almost certainly, new classes of
vulnerability that have yet to be uncovered. Design issues remain common across
freshly written contracts, and developers are still human, after all, and so
prone to the occasional small, unexpected mistake…
Or are they? No retrospective written today can quite dodge the subject — every
other article seems to mention AI, and, as you can see, this one is no
exception. With the recent explosion in both the use and the capability of LLMs,
smart contracts can increasingly be written with their help. It is tempting to
imagine that they will eventually reshape how contracts are written and improve
their safety to the point where external review becomes unnecessary. We are not
there yet. Our most recent audits still turn up genuine mistakes, and LLMs,
however capable, make mistakes of their own — all the more so given how complex
and expressive the eUTxO model can be.
LLMs are reshaping the way we address audits too. They make us more efficient at
building and maintaining our tooling, and at writing audit code. Although we
value confidentiality and never feed them client code, we can point them at a
contract’s interface — blind to the actual code of the on-chain scripts — to
draft endpoints and traces within cooked-validators and
enjoy a quicker mapping to its most advanced features. That pairing makes our
audits faster and, often, better at surfacing the deep corner-case bugs that
might otherwise have slipped through. So the technology cuts both ways: it may
help developers build safer contracts, and at the same time it sharpens the
audits that check them. Which of these effects will win out, we can’t yet say —
but the trickiest findings, such as the design ones we keep running into, or the
ones fully related to specific business logic, are exactly the kind no amount of
automation is likely to catch reliably. On an eUTxO-based blockchain like
Cardano, where elegant and expressive design meets intricacy and subtlety, we
don’t see third-party review going away any time soon.
Conclusion
This is where the retrospective ends, and what five years and more than twenty
audits have looked like from our side. We started out reviewing contracts by
hand and gradually built cooked-validators into a framework
that lets us schedule attacks along a transaction trace, exploring various
possible outcomes; we wrote tools that lasted and tools that did not, learning
from both; and we watched the ecosystem broaden, with higher-level languages
like Plutarch and Aiken joining Plutus, while Cardano grew
new capabilities underneath us. Along the way we caught a lot of bugs, missed a
few, and got better.
The encouraging part is that things are improving. Whole classes of
Cardano-specific vulnerabilities are fading as the platform and its developers
mature, and the contracts we review are cleaner than they used to be. That does
not make audits any less useful; it just changes what they catch. The next era,
Dijkstra, will bring new capabilities, and with them new ways for things to go
wrong. If these five years have taught us anything, it is that every step up in
abstraction and capability opens new room for mistakes — and catching those
mistakes early is exactly what an audit is for — an endeavour we expect to carry
on for another five years at least.
By stateful we mean that, when altering a skeleton, the tweak has read
access to the current blockchain state — the set of available UTxOs and the
values they carry, for instance — so its modifications can depend on that
context. It cannot, however, modify the state itself; only the transaction
skeleton it is applied to.↩
Sooo yes it’s true, I’ve been integrating LLMs and agentic coding tools in my
Haskell coding since the beginning of this year for a lot of my projects, both
personal and professional. I do all of my programming in Haskell, a language
with a very expressive type system that encourages “type-driven
development”.
Working with LLMs on writing Haskell is a very unique experience; a lot of
similarities and patterns exist with “normal” agentic coding, but I think the
hot flame of LLMs meeting the cool stone of Haskell yields a lot of wholly
unique optimal paths, workflow quirks, and failure modes.
This post will focus on understanding what I call constraint-evading
behavior in LLMs as it relates to writing Haskell effectively with LLM
collaboration.
Consider this Part 1 of a series. This post is about how to spot and
understand a very common failure mode of LLMs once you actually are
writing “type-driven” Haskell.
The Ideal Case: Haskell and LLMs
Now, my personal opinion and wishful hope is that Haskell should be
to agentic software engineering what Lean is in agentic research mathematics: a
framework for LLMs to self-construct the scaffolding they need to guide
themselves to their correct goal.
I don’t believe that “correctness at generation-time” is a plausible goal,
not today in 2026, and probably not any time soon. Motion towards correctness is
asymptotic. You might get close enough sometimes, but the long tail of
correctness is…long. Even the most full-vibed frontier-model projects have large suites of tests that exist to
guide the agent. Agentic coding in five years will not be “spit out the correct
program”, it will be “set up the best scaffolding that guides the
implementation”.
Remember: the point of types in Haskell isn’t to catch bad code. It’s to
direct how you write and structure your code, guide you down the most productive
paths, help you concretely iterate on what design you want, and make the actual
code-writing time a smooth flow process.
Each part of this is antithetical to how LLMs are trained to use types and
write code.
To this end, I try to structure my codebases with the correct scaffolding to
help augment the intuition of path exploration: AI has to search which paths are
the “most promising”, so I structure my code-base to quickly kill off paths that
are most likely to be dead-ends or lead to unmaintainable code, and to channel
AI exploration along more promising paths. The greatest tools are types,
compilers, warnings, hints.
A lot of these are the same things we teach to human coders, and are not very
different than what I write about regularly:
Parse,
Don’t Validate: set up your types to make invalid states unrepresentable. AI
will, by nature, NOT do this, even the latest frontier models. They usually slip
into defensive programming (adding isNull checks everywhere,
boolean checks for constructors like isNothing /
isObject / isArray instead of just pattern matching,
filtering lists for duplicates instead of using Data.Set, adding
precondition assertions, etc.), and it’s usually up to the human driver to stop
and consciously create data types that model the domain correctly, structurally
prevent invalid states, enforce pre- and post-conditions via structurally
verified types and not boolean checks, avoid boolean blindness, etc.
Either that, or dedicate an entire session or planning step to clarifying
these domain requirements in their types.
Use warnings and linters enthusiastically:
-Werror=incomplete-patterns of course, and the default
-Werror usually covers a lot of AI failure modes (leaving in dead
code, leaving in arguments in functions for no reason and killing opportunities
for abstraction).
Add robust test suites for things that cannot be tested within the types,
but also explicitly laying out integration tests: something which LLMs seem
pretty allergic to without proper prompting.
From my own empirical observations, all of these things are against the
nature of how even frontier LLM models operate, embedded deeply from being
trained on terabytes of untyped Python and React slop.
So, I’ve been gathering a list of what I call constraint-evading
behavior: when the requirements and constraints are explicitly and
unambiguously stated, but LLM nature desperately tries to circumvent
them because they cannot keep up a sustained fight against their deepest base
impulses.
Decisions that require scrutiny
There is a class of failure modes where AI makes a risky decision that a
human might reasonably make in the rare case that it is justified. But,
usually, it will be making this decision because it’s the “simplest approach”. It cannot separate questionable
decisions based on reasoned justification and questionable decisions based on
flawed heuristics like “simplicity” or effort.
We have the general failure modes like this that people mention for all
programming languages:
“This test doesn’t pass, so let’s disable it”
“Let’s feed this test junk data so it will
pass.”
“Let’s have this function detect if it’s in a test
environment and behave differently if it is.”
But here are some that I feel are specific to working with LLMs in
Haskell.
Disabling Warnings for Escape
Hatches
A lot of the “type safety” of Haskell can be bypassed trivially by disabling
warnings, and a lot of the “escape hatches” within the language are disabled via
linting rules (Prelude.error, unsafeCoerce, etc.)
LLMs will often add warning suppressors that straight-up disable warning or
lint checks.
“Let me add -Wno-incomplete-patterns to this
file so that it can compile, because this pattern is inaccessible anyway in
normal operation”
“Let me add HLINT ignore to this build so
that I can bypass the hlint rule forbidding
Prelude.error”
It’s pretty straightforward to add post-edit hooks to forbid edits of this
pattern…but I think this is a good platonic example of what I mean by
“constraint-evading behavior”.
Maybe sometimes you should be disabling warnings in your files.
Maybe sometimes you should be using Prelude.error. A human
might look at the situation at hand and think, “this is one of those
rare cases where Prelude.error is correct”, or “this is one of
those rare cases where that warning is incorrect.”
But should you trust an LLM to make that judgment call? Fuck no. 99% of the
time, it is only doing this as the easy way out. Yes, every once in a while it
will discover a legitimate reason, but has not properly weighted
P(legitimate | attempted). Most of the attempts will be as hacks,
and it will be more than happy to follow through with an attempt if it truly is
the “simplest way”.
Understanding something as constraint-evading behavior doesn’t mean “ban this
behavior”. It is meant to help highlight situations where 99% of the time, it’s
the LLM taking the easy or fast way out instead of the correct one. In these
cases, it’s imperative that a human is what is adding the warning
silencing or hlint ignore.
“The simplest approach is…” is the worst thing you
ever want to see in a thought trace, because it’s a sure guaranteed sign that
they are about to spew the most ridiculous and awful code you’ve ever seen.
Breaking down the matrix:
P(not legitimate && not attempted): Correct avoidance
of problematic behavior
P(legitimate && not attempted): The noble struggle. The
rare case that you are really justified in this normally risky behavior, but out
of misguided principle you do not. This is a bias and failure mode more likely
to be hit by humans. Or at least one human (that’s me).
P(not legitimate && attempted): The failure mode where
an LLM will choose this out of a flawed heuristic like simplicity or
effort.
P(legitimate && attempted): The rare case that you are
justified in normally risky behavior, and the LLM was correct in attempting
it.
As this matrix moves towards more favorable marginals, my stance here will
slowly change. But for now, the numbers I roughly see encourage continued
vigilance.
Ignoring types in planned code
Let’s say you plan your perfect types that match your domain exactly,
forbidding all invalid states, perfectly monotonic parsers. Then you go to
execute that plan. Unfortunately, LLMs will not hesitate to throw away your
carefully designed types.
“The plan says to use NonEmpty Int as an
argument, but that would require changing too much. The simplest approach is to
just have it take [Int] and check for empty lists”
“We planned to use this existing enum, but it doesn’t have
a branch we need. Instead of adding a branch, we’ll have it take
String instead.”
“Instead of a structured data type, let’s just use
stringly encoded lists or records with separators we can parse out.”
“We have to call fooFunc, which returns an
Int, so let’s have our function return an Int instead
of a Natural like our original plan”.
“The plan requires adding a field to this record, but to
keep things simple, let’s just take a Data.Aeson.Object instead so
we can return whatever fields we want.”
“The plan was to have this function be
Binary a =>, but this type we defined doesn’t have a
Binary instance yet, so we’ll just use Show a =>
instead. It’s the simplest approach.”
This is especially frustrating because often these plans and types were
chosen to enforce some domain invariant or guide the proper and correct
development, but LLMs will almost never hesitate before throwing away all of the
planned type safety.
These are all reasonable things that a human might reconsider during
the process of following out a plan. Maybe we originally wanted to use
NonEmpty Int, but upon closer examination, we realized it does have
to be an [Int]. This is the natural process of iterating on a
design, as you discover more truths about the domain.
But, that call should be a discussed one, not an implicit one…it took thought
to make the original plan, so it should take thought to change the plan. Most of
the time AI makes these decisions, it isn’t out of discovered truths about the
domain, but rather because of needless heuristics to minimize effort, or a
misunderstanding of the intent and design of the original plan (especially if
after a compaction). Things that should be discussed explicitly, not done
implicitly. Outside of planning mode, LLMs aren’t seeking out the truth of the
domain, they’re seeking out the path of least resistance.
Note that this is different than weakening types in existing
functions. That’s a failure mode I rarely see in practice. Instead, when running
into a wall with the type of existing code, there’s another failure mode that’s
much more common…
Structural Type Abuse
Sometimes AI will optimize preserving existing types (especially
across package boundaries) instead of changing them.
String Stuffing
I like to call this “string stuffing”. We like to make nice semantic types
that match our domain and only allow the creation of meaningful values…but LLMs
absolutely love to find ways to twist these to save time. Strings, in
particular, are vulnerable because most Haskell types have Show
instances.
And we have to add a new handler for a new request type. Maybe this new
handler has a new type of error. Instead of adding a new structural error, LLMs
will find great joy in cleverly abusing the structure to invalidate the
domain.
“Invalid groups are not a valid ErrorEvent.
The simplest solution is to put the error in UnknownUser, which can
take a group name.”
And yes, this depravity knows no bounds. You would be surprised by the
creative ways AI will discover to stuff your strings. These are all things I
have personally witnessed in frontier models.
This type of failure mode is probably more egregious than the others
in that it is very rare that this is ever the intended behavior. The entire
reason we picked an ADT to describe our type is so that we can structurally
match on them later, treat them semantically, etc., and string stuffing to abuse
our structure has pretty much zero legitimate use-cases other than quickly
hacking a printf debug session. However, it truly is often “the simplest solution”.
The main way I deal with this is to be very very careful of putting abusable
fields like String, A.Value, Int,
SomeException in my data types…just a single field or branch that
has an abusable field, AI will find it, and you will feel very
stupid for missing it. But hey, the whole point of using properly structured
values was to avoid stuffing things into String too, right? The fix
for this is a fix that helps human coders, too.
“I need to specify the affiliations of the authors in this
report. The simplest solution is to add this to the list of
reportAuthors after the authors.”
AI will also stuff sentinel values everywhere: instead of changing the type
to take Maybe Day, it might add ModifiedJulianDay 0
for missing days.
There’s also the dual, where the AI will be happy to use existing
record fields in overloaded ways instead of adding a new field.
Let’s say you need to add a new feature or code path that requires a new
target for a baz service.
“I need to get a new target…instead of adding a new field
to Targets, let’s re-use barTarget. That’s the
cleanest approach.”
It will optimize keeping existing types instead of extending them to match
your domain as your domain expands, especially if those existing types cross a
library boundary.
I believe there are three heuristics at play that drive this behavior.
The heuristic to avoid extra risk in modifying upstream types across
library boundaries with heavy dependencies. This might be very risky behavior in
an untyped language like Python, where each type change might introduce new
regressions that are not immediately obvious. So, avoiding upstream type changes
avoids potential regression.
The heuristic to avoid extra work in modifying upstream types
across library boundaries and compilation units. In Haskell, however, upstream
type changes force you to address each possible regression point
downstream. So changing an upstream type will require you to address every place
it is used, which can be time-consuming and avoided by LLMs, especially if
compilation is expensive, or multiple new typeclass instances might need to be
added.
I have literally seen LLMs say “Adding this field would
require adding typeclass instances on several other types, which would be a huge
change. The simplest approach would be…”
However, updates require work by design: API changes should
require lots of thought, and the compiler enforcing that is the whole point.
The big irony here is that these updates and changes are largely mechanical
in nature, and are exactly the boilerplatey task that LLMs are optimally good
for. These are the reasonable one-shots. So it’s kind of funny when you let an
agentic coder take on a “self-directed” mode, it refuses to use “itself” in the
way that a real human would for these smaller tasks.
The heuristic to avoid extra risk in touching data types that might
already be used in prod code or databases. Config files that might have to be
updated to new schemas, inter-op with existing services that might not be easily
deployed in sync, working with data at rest…all of these are real risks you have
to manage when changing data types. In practice, a lot of our type changes will
not be relevant to any of these concerns, but it is understandable that
the LLM would develop an instinct to blanket-avoid them.
These are also the types of failure modes that are most difficult to catch
during code review. Diff views will analyze that code has changed, so code that
didn’t change is especially difficult for human monkey brains to spot,
with no green or red bright highlighting. You must be especially vigilant to
catch code that did not change but should have.
Resisting New Types
Sometimes AI does modify existing sum types, but doesn’t quite adapt
existing code correctly.
For example, if your domain has a specific meaningful universe:
We might want to start supporting countries alongside US states. An LLM might
recognize that the domain needs to be expanded, but it might expand it
flatly:
dataRegion=Canada|Mexico|Alaska|Arkansas|ArizonaprocessRegion ::Region->IO ()processRegion = \caseCanada->...Mexico->... st -> processState stprocessState ::Region->IO ()processState = \caseCanada->pure ()Mexico->pure ()Alaska->...-- actual logic
The real solution would be to have all your pattern matches strictly reduce
the space of what they cover (and be monotonically decreasing), and to be
suspicious of “ignored case matches” that have dummy values like
pure ():
dataRegion=Canada|Mexico|USStateStatedataState=Alaska|Arkansas|Arizona|...processRegion ::Region->IO ()processRegion = \caseCanada->...Mexico->...USState st -> processState stprocessState ::State->IO ()processState = \caseAlaska->...-- actual logic
All things that are code smells in normal human code (not necessarily wrong,
but invite further scrutiny), but are maybe amplified in the age of LLMs because
of a mis-tuned heuristic on not defining new types and instead trying to re-use
or abuse existing types.
So, if there is some pressure against modifying types, there might
be an even greater pressure against adding types.
Meditations
None of these behaviors are blanket-wrong, but they usually signal that the
LLM is under stress or duress and attempting to find ways to take the easy or
“low-effort” path over the correct one. All of them are worth human intervention
and guidance as soon as possible, at least until the day where
P(legitimate | attempted) approaches 1.
Will there be a day when LLMs can generate the correct types to match the
domain, and resist their tendency to “defensive-program” their way into
correctness? Maybe. But I have rarely ever had Opus 4.8 crank out a sufficient
domain model for any non-trivial product. And, when I do reach a plan I find
sufficient, a few compactions later and all of the original motivations seem to
get washed out.
There might be a way to uber-prompt all of these issues away, but I feel that
effectively using LLMs isn’t necessarily something you can address from the
prompt level: it’s something that demands constant vigilance and care. I’ve
found automated hooks (like forbidding warning-disabling, detecting hlint
bypassing…ask claude for help writing these lol) also help me flag areas that
need attention immediately.
Who knows, maybe all of these things will be solved within a year. But I
still think of software development as something that’s worth scrutinizing for
anything of importance. As failure modes like these become less common…the long
tail of correctness, I predict, will remain long.
Anyway, that’s it for this topic, but if I find the time I’ll
continue on with some other topics I’ve been thinking about during my Haskell
and LLM adventures:
Effective ways to plan out Haskell code and approaches, ways to encourage
the best possible types
Structuring your libraries mechanically for the best build-and-test rapid
development cycle
Starting and maintaining full “vibe-coded” Haskell projects (when
correctness is not critical) and the advantages over untyped vibes.
Let me know if there are any you’d like to see first, or if there are other
aspects of Haskell LLM usage you might like me to address!
And hey, since we’re here, why not train your agentic friend to take these
ideas to heart?
<https://blog.jle.im/entry/llms-and-haskell-1-constraint-evading-behavior.html>
Read this post and make me a Claude Code skill that reviews a Haskell diff for
the constraint-evading compromises it describes: suppressed warnings, string
and field stuffing, and weakened types that differ from any recorded plans.
Some of these hide in code that did not change but should have, so the skill
should start from the functions that changed and evaluate how they use or abuse
the types involved, but also spot type changes that look suspicious.
Yesterday I talked about the game of Nim, which involves two
players taking beans from several piles, and an extension that
includes green tokens that behave a bit like infinite piles:
When there's a pile with one or more green tokens, it's legal for a
player to remove any or all of them, and then to add any number of
beans to the pile.
At first it might seem that Nim with -tokens could go on forever.
Not so!
If someone gives you a Nim position where all the piles contain beans,
you can say ahead of time how long the game might last. A game
starting with nim-heaps of size simply can't last
more than 16 turns, because each turn removes at least one bean from a
pile, and the game ends when someone takes the last bean.
If the game starts with nim-heaps of size , you can't know how long it might last. If you guess it
will be over in
turns, the first player might prove you wrong by
replacing the
-token with a pile of beans, and then the
game might last up to more turns.
If you guessed at the start that
the game would last no more than turns, one of the
players might replace the token with a
pile of beans, or even
more. Before the first move, there is no bound that can be placed on how long the
game will take to finish.
But what you can say
about
is that after at most moves,
someone will have removed the -token and replaced it with some
finite number of beans. And that that point you'll be able to say
when the game will end.
Similarly, suppose there is are piles .
Remember that is simply a stack of two green tokens.
What's the longest this game could last?
As before, we can't say. But we can say that after at most
turns, at least one of the tokens will have been removed, and there
will be at most one token and a possibly very large number of
beans, say . And then after at most more moves, the last
token will have been taken if it wasn't before, and only beans
will be left, possibly a very large number of beans, say .
And at that point we will be certain that the game can't last more
than more moves.
So with we can't say how long the game
will take to finish.
And we can't say when we will be able to say how long the game will
take to finish.
But we can say that in at most moves, we will be able to say,
not how long the game will take to finish, but how long it will be before we can
say how long the game will take to finish.
Estimating programming tasks
This reminds me of a story I once heard from another programmer. He
told me his boss had come to him to ask him if he could fix a certain
bug. He had replied that he could, and the boss had asked him how
long he thought it would take.
He said “I don't know, I have to think about it.”
His boss, being a reasonable woman, asked him when he would be able to
tell her.
Again he said “I don't know, I have to think about it.”
The boss, having dealt with this guy before, did not lose her
temper. Instead, she asked how long it would take him to figure that
out.
“Not more than two days,” he said at once.
“Okay,” she said. “Just to make sure there is no miscommunication,
are you telling me that in two days you may not be able to estimate
the task, but you will be able to tell me when the estimate will be
ready?”
“That's right.”
And they parted amicably, both parties satsified, at least for the
time. Communication between management and engineering doesn't
always turn out so well!
My friend was apaprently playing the game . There was only
one bean, so one of the tokens would have to have gone by the
second day. At that point there would remain for some
finite number , and although my friend wouldn't be able to say at
that point how long the game would last, he would know that he would
be able to deliver the estimate after at most more days.
The game must end!
With we don't know when the game will end, or how long it
will be before we know when the game will end.
But we do know that in
at most two moves we will know how long it will be before we know how
long it will be before the game ends, and that means that we do know
that that game will end even though we're quite far away from saying
when that will happen.
The argument is always the same: there are only a finite number of
beans, and even if both players try to avoid the tokens, the beans will eventually run out
and someone will be forced to replace a green token with more beans.
Then those beans will run out and someone will be forced to take
another token, and so on, until all the tokens are gone, and then when
the beans run out the game is over.
Of course, both tokens and beans might go faster than that. But go
they will, however slowly and even if only one at a time.
And this is true no matter how many green tokens there are to
begin with.
And the same holds true if there are any square tokens. Even
if the players avoid the square tokens, at
some point all the beans and green tokens will be used up and
someone will have to replace at least one square token with
more beans and green tokens, and then those will be used up… and
eventually the last square token will be gone, and then we're
back to the case of the previous paragraph and the game must
end.
But at that point we have defeated English descriptions. We have
piled up an infinite sequence of “how long before we can say”s into
“We can't say how long before we can say … how long before the game
ends”.
Bizarre! And yet we know that even these games must end, although
English isn't powerful enough to say how long it will take, or even
how long before we will be able to say how long it will take.
Ordinals are well-founded
An ordinal is a set of smaller ordinals. Every move in Nim makes an
ordinal smaller. If you keep making numbers smaller you eventually
reach 0, and then the game is over.
This property of ordinals is called well-foundedness. We say that
ordinals are well-founded.
Note that this that this is a special property of ordinals, not shared by all
types of numbers. For example, the positive rational numbers do not
have this property. From you can go down to the smaller
, then to the smaller , and so on, downward,
always downward to smaller and smaller numbers, but never reaching zero. A game of Nim where the
beans can be divided into infinitely small crumbs might never end.
But a game of Nim with ordinals always ends, because the ordinals are well-founded.
You can go up and up forever to crazier
and crazier infinite ordinals, but no matter how far up you go, you
can't go down and down forever, you must bottom out at zero after a
finite time.
Well-founded orderings are the the theoretical backbone of recursive
programs. When we write a recursive function, we want to be certain
that it will terminate. And that means that if a function calls
itself with a different argument, the new argument must smaller than it
was. Maybe “smaller” mans numerically less. But it could mean many
other things. If the function is processing a directory tree,
“smaller” could mean “fewer levels deep”. If the
function is sorting a list, “smaller” could mean “fewer items are out
of order”. The essence of recursion is that the shrinking cannot
continue forever. The function will eventually reach the number zero,
or the directory that contains only files, or the list with no
unsorted elements, and then it will be done.
In the next article we will see a way to understand infinite nim-heaps
in a more uniform way than as a hodgepodge of variously shaped and
colored tokens.
Claude generated the green poker chip image.
Everything else in this article was written entirely by
me.
We're going to get to in a long and roundabout way. First I
want to talk about the game of Nim.
Nim
Nim is a very simple game for two players. There are some
piles of beans, which are called nim-heaps. When it's your turn,
you are allowed to remove as many beans as you like, as long as they
are all in the same pile. Whoever takes the last bean wins.
Nim with only one pile of beans is trivial, because whoever goes first
can simply take all the beans from the one pile and win. And with two
piles it's very simple. But with three or more piles it starts to be
a little interesting. Consider the case where there are three nim-heaps, with
1, 2, and 3 beans respectively. The first player can't prevent the
second player from taking the last bean.
For a slightly less simple example, consider a game that starts with
nim-heaps of size 1, 3, 4, and 8 beans. Here the first player can
win, if they might the right opening move. But there's only one
winning move! If the first player does anything else, the second
player can win.
(Hover for spoiler: The unique winning move is
to take two beans from the pile of 8, leaving 6.)
Nim lies at the heart of an important part of the theory of
mathematical games. In many games, the two players have different
legal moves. For example, in chess the White player is only allowed
to move the white pieces, and the Black player is only allowed to move
the black pieces. If someone shows you a chessboard and asks you to
make a legal move, you can't do it until they tell you whether you're
allowed to move the white or the black pieces.
Nim isn't like this. When it's one player's turn, they have exactly
the same legal moves as the other player would if it were their turn:
take as many beans as they like from one pile.
It transpires that any game where the two players always have
exactly the same legal moves can be understood as a disguised version
of Nim. We don't have time to explore this surprising fact though,
we're hunting .
Ordinals are nim-heaps
Ordinals can be understood as nim-heaps, and vice versa. Instead of
several piles of beans on a table, we have a list of ordinal numbers,
one number for each pile. The finite ordinals are simple: is an
empty heap, which we can ignore. is a heap with only one bean,
and is a heap of beans.
Whe a Nim situation is understood as a list of ordinal numbers, the
rule that says you can remove beans from any single heap now says you
can reduce any single ordinal to a smaller ordinal. Reducing the
ordinal to is analogous to taking enough beans from a pile of
to leave . You're allowed to take all the beans in a
single pile. In ordinal number language that says you can reduce any
single ordinal to the smaller ordinal .
With this understanding, we can interpret infinite ordinals as
nim-heaps also. If one of the ordinals, you can reduce it to a
smaller ordinal, which must be a finite number because is the
smallest infinite ordinal. But it could be any finite number
because every finite number is smaller than .
Don't imagine as an infinite heap of beans. That's not right,
because if you take 17 beans from an infinite heap, the heap is still
infinite, and doesn't work that way. The ordinals less than
are all finite, so to reduce the heap, you have to
replace it with a finite pile of beans. Picture as a special green
token on the table, which can be replaced with a single pile of any
number of beans.
Nim still makes sense with green tokens
The game still makes sense even with these crazy green tokens!
Imagine playing the game with five heaps, say of sizes
and . It turns out that, like before, there is exactly one good
move that will allow the first player to win, and if they make any
other move, the second player can force the win instead.
Spoiler:
The first player should replace the with exactly 14 beans.
If the first player replaces it with more than 14, the second player can win
easily by reducing the number to 14, leaving the situation
the way the first player should have.
If they replace it with fewer, or if they remove beans from any of the
finite piles, the second player can still win, but it's not so
simple.
If you find this sort of thing fun, analyzing a few games of
Nim-with-tokens will be fun. There are all sorts of interesting
patterns. For example: If there are any number of piles of beans, and
a single token in a separate pile, the first player can always win, and their
winning move will always be to replace the token with the correct
number of beans, as in the example. But if there is more than one
token, the first player might not have a winning move, and if
they do, it might not involve the token. For example, consider
the position . Here the first player can win by
removing the lone bean from its pile. Do you see why?
Bigger ordinals
Now we have a way to imagine : it's just a heap with two green
tokens. To make a legal move in this heap, one can replace one of the
tokens with any number of beans, reducing the ordinal to
the smaller ordinal . Or one can remove a token entirely (that
is, replace it with zero beans), reducing the ordinal to the
smaller ordinal . Or one can remove both tokens, replacing them
with any number of beans, even zero, reducing the ordinal to a finite
one.
is a heap with three green tokens and five beans:
When it's your turn, if you want to move in this heap, you may remove
up to three green tokens and up to five beans — any or all. And also,
if you remove any green tokens, you may replace them with as many beans
as you like, none or five or five billion.
Green tokens and beans are enough to take us almost to , but
not quite. For we need something new. It's a different kind
of token, say a square token. When there is a square token in a heap,
a player may remove it and replace it with any number of green
tokens and beans.
Then we could imagine a cubical token for , which can be
removed and replaced with any number of square tokens, green tokens,
and beans, and so on, and that gets us almost to .
But there's a simpler way to think about , which I hope to
reach in the coming days.
Claude generated the green poker chip image. Then I
asked it to produce an image of a stack of three chips, plus five
beans. I wasn't happy with the result, so I used Inkscape to
transform its original chip illustration into a stack, and then copied
over Claude's beans. Everything else in this article, including the
em-dash, was entirely human-generated.
Recently Martijn Bastiaan, QBayLogic’s COO,
invited Well-Typed to come to QBayLogic HQ and give a one-day workshop on
falsify, the new property based
testing library that I developed for the Haskell Symposium back in 2023
(paper,
presentation).
QBayLogic is the company behind
Clash: a purely functional language for hardware
design. In case you haven’t heard of it, Clash translates Haskell to VHDL or
Verilog, which can in turn be translated to actual hardware. It literally uses
ghc as its frontend so you
have essentially the full power of Haskell available. It’s a great project, I
recommend checking it out.
The falsify library takes its main inspiration from the Python
Hypothesis library, though it is not a direct
translation: it takes the same core idea (“parse, don’t generate”) but
reinterprets it in a way that better suits the Haskell way of thinking: more
axiomatic approach, support for generating infinite data types (including
functions), etc. For more information on falsify, see also the original blog
post that announced it, falsify: Hypothesis-inspired shrinking for
Haskell.
At QBayLogic HQ we spent the morning developing
mini-falsify from scratch, so
that we could focus on the main ideas without getting bogged down in the details
of the full library; similar in spirit to for example
TinyServant,
or perhaps Stephen Diehl’s Typechecker
Zoo. In the afternoon we hacked on
falsify and its application within the clash ecosystem. Partly as a result
of that work and partly as a result of me taking this opportunity to do some
long overdue maintenance on falsify, there is now a new falsify release:
falsify-0.4.0. In the
remainder of this blog post we give a brief overview of the main changes.
New feature: Context
Most of this falsify release is just cleanup, but there is one important new
feature, spear-headed by Peter Lebbing and Martijn Bastiaan from QBayLogic. The
Property monad now has an important new function, called
getContext:
getContext ::PropertyContext
The most important information that the context of a property provides is
how many tests we are running for each property (how hard are we trying to
falsify this property), and which iteration this particular attempt is.
This can be quite useful, for example when you want to start by looking at small
test cases and then slowly broaden the scope. Just as a trivial example,
consider the property that “no number is equal to 5”. If we use
prim
to generate the number to test, producing an arbitrary Word64, the chances
that we will find the one counter-example (5) in that enormous search space
are essentially non-existent:
demo ::Property ()demo =do x <- gen Gen.prim assert $ P.ne .$ ("forbidden", 5).$ ("x", x ::Word64)
However, we could start with a small range and slowly grow that range; falsify
now also offers a convenience function, defined in terms of getContext, for
this specific purpose:
sized,
so-named because it is somewhat similar in spirit to sized in
QuickCheck:
sized ::forall e a. (ProperFraction-> a) ->Property a
A
ProperFraction
is in the half-open interval [0,1); that is, between 0 (inclusive) and 1
(exclusive). We can use this to refine our demo property:
demo2b ::Property ()demo2b =do l <- sized $ ProperFraction.scaleIntegral 100 x <- gen $ Gen.inRange $ Range.inclusive (0, l) assert $ P.ne .$ ("forbidden", 5).$ ("x", x ::Word64)
This property is easily falsified.
As an aside, I would be somewhat cautious in using this approach. While it is
sometimes unavoidable, in general I would recommend generating test case of
arbitrary size and then shrinking them down; this is often more likely to
actually find counter-examples. If there are specific edge cases that you want
to hit, write a generator that covers those edge cases specifically, and perhaps
use labelling
(label
and co) to check that those edge cases are indeed covered. However, as this demo
shows, for some properties explicitly searching for small domains first can be
very helpful.
Cleanup
The most important change in this release is a cleanup of the code base:
There is now a separate tasty-falsify
package that provides integration with the tasty test framework; falsify itself now provides Test.Falsify.Driver.
The module hierarchy has been significantly cleaned up. For example, there are now a bunch of new Data.Falsify.* modules for specific datatypes; previously some of these were exported by Test.Falsify.Gen instead; now that module only contains the generators for those datatypes.
Deprecated functions have been removed
Some functions have been renamed and some type aliases have been replaced by newtype definitions for increased API clarity.
All Haddock warnings have been addressed.
For a full list of changes, please refer to the changelog.
Conclusions
Shrinking can be handled manually, in the style of
QuickCheck; or
automatically, in the style of
hedgehog or in the style of
falsify. If you are willing to
put effort into writing good shrinkers for all your types, then QuickCheck is
still your best bet.
If you consider the cost of manually writing shrinkers too large, then within
the Haskell ecosystem you have a choice between hedgehog and falsify. The
former has the considerable advantage that it’s been around for quite a long
time and is a very polished library. The downside is that every time you use
monadic bind you introduce a cut-point, which can often result in poor quality
shrinking. With Hypothesis showing the way,
falsify solves that cut-point problem, though even with falsify it still
matters how you write your generators: shrinking is never truly free.
Moreover, falsify should be considered an experimental library: it’s nowhere
near as battle-tested as Hedgehog, never mind QuickCheck. That said, thanks to
the interest of QBayLogic falsify is now a little more mature, so thank you
QBayLogic!
For clients who are looking for professional support for the use of falsify,
or indeed any other Haskell library, don’t hesitate to contact us at
info@well-typed.com.
This post is going to be about what infinite ordinal numbers are, and
about is in particular. I had a brainwave a while back (18
months now, wow, I have definitely not been blogging enough) and
suddenly understood much better than I did before. I have
several related ideas here and I am going to try to write one blog
post about each of them, instead of one gigantic blog post about all
of them together that I never finish.
I really like the ordinal numbers. For some reason I was repeatedly
exposed to the infinite cardinals as a child and, while they are
pleasingly mysterious, they're also somewhat uninteresting because
they have no internal structure, they are just bignesses. It's super
cool that there is more than one possible bigness of an infinite set,
of course, but sets can have all sorts of interesting structure, and
looking just at the bigness ignores all that.
The ordinals are much more satisfying, and also I feel that they are
more like numbers. This post explains how they work and introduces
the interesting ordinal .
What we're doing
The idea behind the ordinals is that we want to define something like
the “natural” numbers , where each number has a successor and there is a
less-than relation. But we want to do it in the context of elementary
set theory, which is simpler. Extremely simple, in fact.
What is set theory?
I don't know how intelligible this article will be if you don't
already know, but I am going to try to explain it as briefly as
possible. People who already know what means can skip to
the next section.
In set theory, the only kind of object is a “set”, which is like a
featureless bag of things, which are called elements. What kind
of things? We don't care, that's not part of the model. The only
properties a set has are which things are in the bag.
It doesn't make sense to ask what color a set is or whather it is a
citizen of Belgium; sets don't have colors, they aren't citizens of
anywhere, and they don't have any other extrinsic properties. The
only kind of question you can ask is about a set is:
Is this thing in that set ?
When it is, we write , and when it isn't we write .
When a set contains the things and , and nothing else,
we write it as
$$
\{ p, q, r\}
$$
so for example but
There is one special set called the “empty set” that has nothing in it
at all; it's written .
The one other piece of set theory you need to know for this article is
that if you have two or more sets, you can combine them into a single
set that contains everything that the original sets did. This is
called the union of the sets. When combining two sets and
, we write for their union. For example:
There is a lot more than that to set theory but that is the basic
idea and I think it's enough to get pretty far in this article.
To define numbers in the context of elementary set theory means that
we want to find sets that we can interpret as numbers, and a way to
interpret arithmetic and such as being operations on these sets. We
want to show that those sets can be made to behave the way we expect
numbers to behave, and that we can prove that the arithmetic
operations have the properties that we expect numbers to have. For
numbers, it's true that , and we want to be sure that,
whatever we decide that means for sets, and whatever sets we've
chosen to stand in for and , we should still have
.
Understanding when we can model a complicated system in terms of a
simpler one, and how to do that, is one of the main concerns of
mathematics. Set theory is just about the simplest system there is,
so mathematics spends a lot of time trying to interpret various
complicated systems in terms of set theory.
Less-than
Numbers have a less-than relation , and elementary set theory
has only one relation, , so it makes sense to try to use that
for less-than, and see if it works. We’ll say that if and
are sets that represent numbers, then means the same as
.
We want to be transitive. That is if and then
we should also have .
If we're taking to be synonymous with , then this means
that if and are sets that represent numbers, and
if and , then we should also have .
This is kind of a weird situation. It means that is not a set
of fish or carrots, it means that is a set of
sets. And it means any element of any of ’s sets is also an element of
itself. When this happens we say that the set is
transitive, using the word “transitive” analogously to the way we do
what we say that is transitive.
Transitivity puts fairly strict constraints on what a set can be
like. There are lots of sets, but relatively few of them are transitive.
Here are some examples of transitive sets, and the numbers they represent:
Since we are using here as just another way to write the empty
set , we could have written instead of
. They mean exactly the same. But I feel that the
nested curly braces quickly get confusing and don't really contribute
to understanding. Still, remember that when we write the symbols , and so on, we're not using them in their usual sense of numbers.
Rather, we are talking about these particular transitive sets.
These sets are all transitive. For example, and
and sure enough, also. This isn’t trivial: Not every set
of numbers is transitive. For example is not a
transitive set because and but .
We'll say that an ordinal number is a set that is transitive, and
whose elements are all also transitive sets, and the elements of those
are transitive sets, and so on all the way down. All the sets in the list
above are examples. There are transitive sets that aren't ordinals,
but we're not interested in them in this article, because they aren't
number-like in the same way.
This identification of numbers as these particular sets does also
make behave like the less-than relation in the way we
wanted. For example, we have because ,
but not vice versa, it's not true that because
.
Technically this definition has a lot to recommend it. It’s extremely
simple, which makes it easy to work with, and many natural theorems
are easily proved. For example, when dealing with familiar numbers,
it’s always false that , for any . We'd like to able to
prove the analogous thing for our synthetic sets-as-numbers. If we
can’t (or worse, if we can prove the opposite) then our model is
missing something important (or worse, it’s just wrong).
Well, by our definition of less-than, simply means
, which is false because has no elements, and
that's the proof that is false.
Successorship
Another thing we need from numbers is a successor operation: each
number should be followed by another, different one, and it should be
possible to calculate which one. This has been recognized since the
19th century as
the most important organizing principle that the natural numbers have.
It’s is one of the few foundational things that almost every
mathematician not only accepts but is happy with.
If is some transitive set, we should be able to identify
another, different transitive set that we can designate as the
successor of , the number that follows in the sequence of
numbers. It’s not hard to show that if is transitive then so is
This gets us the numbers, as we wanted, and we could go on from here to
explain how and work and so on, but today we are
going a different direction. It turns out that if we add one more
ingredient we get a lot more than just familiar numbers. There’s one
other way of making an ordinal number out of smaller ordinal numbers.
If is any family of ordinals, then
their union, the set that contains everything that is in any of them,
is an ordinal also.
When the family has a largest element , (typically
because it’s a finite family) then the union is not anything new, it’s
just again. For example . But
if the family of ordinals has no largest element, we do get
something new. In particular, the union
$$
\omega = 0\cup 1\cup 2\cup\dots
$$
is an ordinal number.
By constructing the numbers as transitive sets, we got what we wanted:
the finite ordinals behave just like numbers. But if we also
consider infinite ordinals, we get infinite numbers like
that behave, in some ways, like bigger siblings of the
numbers. participates very nicely in less-than comparisons
and minimum and maximum operations, and somewhat nicely in addition
and multiplication.
is an ordinal number but not a familiar one. Under our
definition of as a synonym for , every finite number
is less than ; there's no familiar number that behaves
that way. It’s different from finite numbers in another way also:
except for , each finite number is a successor of
some other finite number and so has a predecessor, whereas is
not a successor of anything and has no predecessor. Ordinals like
that are not successors are called limit ordinals.
Every ordinal has a successor, and is an ordinal, so it
has one, usually written as
, which is the next ordinal after . Then there follow , and the union of all of these is the set
After these come and then we can
take the union again to get and then and
so on, and eventually
. Then after a long series of things like $$\omega^2·17 +
\omega·39+117$$ comes , then
including an infinite ordinal for every polynomial involving
, for example
where it’s like a polynomial in , except that the exponents don’t have to be finite numbers, they can be other super-polynomials in whose exponents don’t have to be finite. And then, after all of these, the limit of this mind-boggling sequence, is the ordinal called
$$
{\epsilon_0}
$$
It’s just gotten too complicated to express with regular mathematical
expressions involving . It transpires that this is the
smallest ordinal satisfying the property that
$$
x = \omega^x
$$
This is the thing I have finally been able to get my head around, a
little.
Topiary is a uniform formatter designed to support multiple languages through a single, consistent interface. By relying on Tree-sitter grammars and formatting queries, it easily adapts to new languages. But what happens when a language contains other languages inside it?
I’m excited to share how Language Injections work in Topiary, a new feature allowing Topiary to format “forests” of syntax trees embedded within one another. This unlocks support for formatting embedded languages like OCaml snippets inside OCamllex files or code blocks within Markdown documents.
The Problem: Embedded Languages
Many file formats and programming languages permit embedding entirely different syntaxes within them.
Take Markdown, for instance. A Markdown document can contain fenced code blocks for arbitrary languages. You can even nest these embeddings! Consider a Markdown document containing some OCamllex (a lexer generator for OCaml).
Before formatting, the nested syntax might look a bit messy:
Example lexer:
```ocamllexrule main =parse
|_ {print_string "Hello, ";print_endline
"World!"}```
After passing this Markdown file through Topiary, the Markdown, OCamllex, and even the OCaml code nested inside the OCamllex, are all cleanly formatted:
Example lexer:
```ocamllexrule main = parse
| _ {
print_string "Hello, ";
print_endline
"World!"
}```
Historically, formatters struggle with this. They either leave the embedded code alone, implement ad-hoc parsing for specific combinations, or risk breaking the inner syntax. I wanted Topiary to handle this reliably.
The Solution: Language Injections
The idea of “language injections” comes from the Tree-sitter ecosystem, where it has become a de facto standard for handling embedded languages. Editors like Neovim, Helix, and Zed all use Tree-sitter’s injection mechanism to provide accurate syntax highlighting, code navigation, and other language-aware features inside embedded documents. The technique works by running a secondary Tree-sitter parser over a region of the host document, producing a separate syntax tree for the injected language. Which regions to inject, and which language to use, is specified through injections.scm query files that ship alongside grammars.
Topiary now adopts this same mechanism for formatting. By delegating formatting tasks to another language’s formatter mid-flight, Topiary can correctly format inner code chunks while still respecting the layout of the host language.
I recently merged the foundational Topiary PRs along with two language integrations to demonstrate this capability in action:
OCamllex / OCaml Injections: Topiary can now format the OCaml semantic actions embedded inside OCamllex files.
Markdown Injections: Topiary can dynamically format code fences in Markdown documents according to their language identifier.
Deep Dive: How It Works Under the Hood
If you’re new to Topiary, the short version is that it formats code by parsing it with Tree-sitter grammars and then applying declarative formatting rules written as Tree-sitter queries. For a fuller introduction, see the announcement blog post or the Topiary Book.
The injection process relies on Topiary’s existing Tree-sitter foundation and extends the atomization model. At a high level, Topiary parses the host document, extracts the injected spans, delegates their formatting to the inner language’s formatter, and stitches the results back together. Here are the technical details of how I achieved this.
1. Discovering Injections with Queries
If a host language definition includes an injections.scm query file, Topiary runs those queries against the host tree prior to standard formatting (a query can be thought of as a pattern-matching function that takes an AST of the host document and produces a list of matching spans). The queries dictate which spans of the host AST contain foreign code.
Topiary supports two methods of resolving the injected language:
Static Resolution:
For languages where the embedded language is always known (e.g., OCamllex always embeds OCaml), the injection query uses an #injection_language! predicate against the relevant AST node (in the tree-sitter-ocamllex grammar, the code block node is handily named ocaml):
Dynamic Resolution:
For formats like Markdown where the inner language isn’t known ahead of time, Topiary dynamically captures the language identifier from the AST (e.g., the info string of a code fence) using the @injection.language capture (a capture simply assigns a name to a matched node in the query):
Once the injection queries identify the embedded spans, Topiary proceeds with the host language formatting. Crucially, Topiary treats the captured @injection.content nodes as leaves during query matching.1 This means the host formatter doesn’t traverse inside them.
After the host document is tokenized into atoms (the basic building blocks of the layout engine, representing either raw text fragments or formatting directives like spaces and line breaks), Topiary iterates through the captured injection spans:
Each injected span is formatted independently by its corresponding inner language formatter.
The inner formatters execute as if they are producing text starting from column zero.
The resulting formatted string replaces the corresponding host leaf in the atom stream.
There is no “re-parse” phase after the injected text is rewritten. The host renderer retains control over the indentation; when it finally prints the substituted atom, it applies the appropriate indentation string from the host context.
Because step 1 invokes the full formatting pipeline, injections are naturally recursive. If the injected language itself defines an injections.scm file, its injections will be discovered and formatted in turn. For example, formatting the nested Markdown/OCamllex/OCaml snippet from the top of this post doesn’t require any additional effort: Topiary will format all three layers without any special orchestration. Markdown delegates to OCamllex, which delegates to OCaml, each through the exact same code path!
3. Performance
The most expensive part of formatting an injected language is compiling its grammar and parsing its query files. If Topiary recompiled the queries for every single injected span, formatting a document with 100 embedded snippets would be prohibitively slow.
To solve this, Topiary needs a way to compile the grammar once and share it across all matching spans. This ensures the total cost is sublinear in the number of injections.
3.1. The LanguageResolver Hook
To achieve this caching dynamically, I introduced the LanguageResolver type alias to the core formatter API. Topiary is not just a CLI; it is also a library. Because the core library doesn’t know how languages are configured or where grammars live on disk, I delegate the responsibility of resolving languages to the frontend via this hook:
dyn Fn(&str): The resolver is a trait object, specifically, a callable value that takes a language name (e.g., "ocaml" or "rust") as a string slice. Using a trait object here means the core formatter doesn’t need to know which concrete function performs the resolution; it just calls whatever the CLI (or any other frontend) hands it.
-> FormatterResult<Option<Arc<Language>>>: The return type is a Result wrapping an Option:
Ok(Some(language)) means the language was found and loaded. Topiary proceeds to format the injected span with that language’s grammar and queries.
Ok(None) is a soft failure: the language isn’t configured or isn’t supported. Topiary skips formatting for that span gracefully, leaving it untouched.
Err(...) is a hard failure (e.g., a query file failed to parse). Topiary aborts the entire formatting run and returns an error without modifying the file.
Arc<Language>: The resolved Language is wrapped in an atomically reference-counted pointer. Topiary compiles the Tree-sitter grammars and queries into a Language for formatting; Arc enables caching. The CLI can compile the Language on the first call and return cloned Arc handles on subsequent calls, ensuring the compilation overhead is shared across all injected spans of the same language.
+ 'a: A lifetime bound tying the resolver to a borrow scope. In practice, this gives the resolver the flexibility to temporarily reference external data (such as the CLI’s configuration cache) without requiring permanent ownership of it.
This design decouples Topiary’s core formatting logic from any particular frontend. The core library doesn’t know how caching works; it just calls the resolver and acts on the result.
Limitations
These changes do a great job in the majority of use cases, but still have a few known limitations.
Firstly, because injected spans are formatted independently, the current injection model is stateless. It cannot express layout decisions that require measuring or choosing between softline layouts across the host/injected boundary. For example, consider a Markdown document like this:
Let's first define a greeting function that takes a string reference:
```rustfngreet(name:&str){```
Now we complete the function by printing the greeting to standard output:
```rustprintln!("Hello, {name}!");}```
Here a Rust function definition is split across two code fences. Since each fence is its own injection, Topiary formats them independently. The first block sees an unclosed brace, and the second sees an indented statement followed by a closing brace with no matching opener. Neither fragment is valid Rust on its own, so the formatter can’t make sensible layout decisions about them. In practice, because the inner language fails to parse, Topiary will abort the entire formatting run and return an error.
However, if you pass the --tolerate-parsing-errors flag, Topiary will do its best. Because each fragment is formatted independently as if starting from column zero, the indentation on the second fragment gets completely stripped:
Let's first define a greeting function that takes a string reference:
```rustfngreet(name:&str){```
Now we complete the function by printing the greeting to standard output:
```rustprintln!("Hello, {name}!");}```
Overall, I believe this is a perfectly acceptable trade-off: purity and statelessness provide an elegant and robust formatting pipeline, which is not worth giving up for gaining the ability to handle fragmented constructs, which are less common.
Another known limitation is that, while Tree-sitter grammars are usually flexible enough to parse individual definitions or expressions, if a grammar strictly expects a full source file and nothing less, it won’t be able to parse short injected snippets correctly. Just like with fragmented code blocks, this will result in a parsing error unless --tolerate-parsing-errors is used. Fortunately, most grammars (e.g. Java, C#, or Rust) are remarkably flexible and do not exhibit this problem.
Conclusion
By leveraging language injection queries and extending the core formatting API, Topiary can now cleanly format embedded code snippets without breaking the host language layout. With language injections, Topiary is no longer just formatting single syntax trees: it’s formatting forests.
This feature will be included in an upcoming release. In the meantime, if you’re working with OCamllex (for which Topiary is, to my knowledge, the only complete formatter!) or writing technical Markdown documents, you can try it out today.
To run it on an OCamllex file using Nix, for example, you can use:
nix run github:topiary/topiary -- fmt myfile.mll
Usually embedded language spans are already parsed as leaves by the
tree-sitter grammar itself. But they don’t have to, so enforcing that
Topiary only sees leaves no matter what the grammar says is safer.↩
I always say, inside every Haskeller there are two wolves, living on opposite
ends of the Haskell Fancy Code Spectrum. Are you going to write “simple
Haskell”, using basic GHC 2010 tools and writing universal Haskell that every
introductory course offers, trying to keep the code as immediately
understandable and accessible? Or are you going to pile in all of the Haskell
type system and evaluation tricks you can find and turn on all the extensions,
and go full fancy?
In my Seven
Levels of Type Safety post, I described different extremes of type safety
and fancy code. I talked about how writing effective code was finding the
correct compromise for the level of communication and safety you need.
But this is not that kind of blog post. This is the kind of blog post where
we celebrate terrifying type-safety, facetious fanciness, and masochistic
meta-analysis. This series is about what happens when we dare to go full fancy.
Let’s write code that is so inscrutable, so painful and torturous to write, yet
so undeniably useful that you can’t help but try to throw it into every
single thing you write and will feel a gnawing emptiness in your soul until you
do.
As our example, let’s write a type-safe method to specify your program as a
series of states, with triggered transitions between them: a type-safe state
machine graph using a type-safe lambda calculus. We want to specify this in a
way that we can write once and then:
be interpretable in a type-safe way within Haskell.
be inspectable with visualizable control flow.
be compilable to multiple actual back-ends, letting you run the same
function under multiple implementations.
This exact thing is something I’ve needed and used multiple times now in
projects. I want to specify one program graph within Haskell, but in a way that
can compile both in C and javascript while also being visualizable and
interactively explorable.
Once you go down this road, everything you ever write will feel woefully
unsafe and limited. And everything you want to write will be hopelessly
inscrutable by normal humans and borderline unusable. But such is the curse we
all bear. Turn around now, you have been warned.
This post will build up the embedded typed expression language. Part 2 will
use that expression language to define typed state machines with embedded
predicates and visualize them, and Part 3 will compile those machines to
different languages and verify they execute identically, with some live
demos.
All of the code here is available
online, and if you check out the repo and run nix develop you
should be able to load it all in ghci:
$ cd code-samples/typed-sm-lc$ nix develop$ ghcighci> :load ExprStage1.hs
The Lambda Calculus
Let’s derive a way to express an algorithm or expression in Haskell that can
be reified and analyzed within Haskell, and eventually be a form we can compile
to different backends, interpret in Haskell, or generate Graphviz visualizations
for.
The strings in ELambda introduce variables, and
EVar refers to the bound variable. As you can see, this is…pretty
untyped. We could easily write something that is meaningless:
Of course, GHC can typecheck our code if we literally write
\x -> x + 3 and reject 1 && 2. But we
aren’t trying to build opaque Haskell code here, we’re trying to represent our
expression as an ADT that we can analyze within the language.
If we want a record projection and one labeled choice with a case analysis
over it:
Now, for the entire point of Expr, we can write a function to
pretty-print it, using the prettyprinter
library:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage1.hs#L253-L299ppPrim ::Prim->PP.Doc annppPrim = \casePInt n -> PP.pretty nPBoolTrue->"true"PBoolFalse->"false"PString s -> PP.pretty (show s)ppOp ::Op->PP.Doc annppOp = \caseOPlus->"+"OTimes->"*"OLte->"<="OAnd->"&&"ppExpr ::Bool->Expr->PP.Doc annppExpr paren = \caseEPrim p -> ppPrim pEVar v -> PP.pretty vELambda n body -> wrap $"\\"<> PP.pretty n <+>"->"<+> ppExpr False bodyEApply f x -> wrap $ ppExpr True f <+> ppExpr True xEOp o x y -> wrap $ ppExpr True x <+> ppOp o <+> ppExpr True yERecord xs -> PP.encloseSep "{ "" }"", "$ [PP.pretty k <+>"="<+> ppExpr False v | (k, v) <- M.toList xs]EAccess e k -> ppExpr True e <>"."<> PP.pretty kEChoice tag x -> wrap $ PP.pretty tag <+> ppExpr True xECase x hs -> wrap $ PP.sep [ "case"<+> ppExpr False x <+>"of" , PP.encloseSep "{ "" }""; "$ [ PP.pretty tag <+> PP.pretty n <+>"->"<+> ppExpr False body| (tag, (n, body)) <- M.toList hs ] ]where wrap| paren = PP.parens|otherwise=idprettyExpr ::Expr->PP.Doc annprettyExpr = ppExpr False
ghci> prettyExpr fifteen(\x -> x *3) 5ghci> prettyExpr badTypeExample1&&2ghci> prettyExpr recordExample{ label ="found", value =7 }.value +1ghci> prettyExpr sumExamplecaseFound7of { Found value -> value +1; Missing message ->0 }
Now, we can write a quick typechecker for this using a greedy type-checking
algorithm (written
out here), which is a fun exercise, but it’s beyond the point of this post.
For our purposes, we’re going to write the in-Haskell evaluator, which is one
sure-fire evidential/constructive way to prove an expression was valid
after-the-fact.
So…how can you “evaluate” this to 15, within Haskell? What would the type
even be? The best we can do at this point is make the entire thing monadic by
returning Maybe or Either, and split out the
expressions we write from the values we can actually evaluate to:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage1.hs#L228-L330dataEValue=EVIntInt|EVBoolBool|EVStringString|EVFun (EValue->MaybeEValue)|EVRecord (MapStringEValue)|EVChoiceStringEValueeval ::MapStringEValue->Expr->MaybeEValueeval env = \caseEPrim p -> evalPrim pEVar v -> M.lookup v envELambda n body ->pure (EVFun (\x -> eval (M.insert n x env) body))EApply f x -> eval env f >>= \caseEVFun f' -> eval env x >>= f' _ ->NothingEOp o x y ->do u <- eval env x v <- eval env ycase (u, v) of (EVInt a, EVInt b) ->case o ofOPlus->pure (EVInt (a + b))OTimes->pure (EVInt (a * b))OLte->pure (EVBool (a <= b))OAnd->Nothing (EVBool a, EVBool b) ->case o ofOAnd->pure (EVBool (a && b)) _ ->Nothing _ ->NothingERecord xs ->EVRecord<$>traverse (eval env) xsEAccess e k ->doEVRecord xs <- eval env e M.lookup k xsEChoice tag x ->EVChoice tag <$> eval env xECase x hs ->doEVChoice tag payload <- eval env x (n, body) <- M.lookup tag hs eval (M.insert n payload env) body
ghci> for_ (eval M.empty plusThree) \caseEVFun f ->print (f (EVInt4)) _ ->putStrLn"not a function"Just (EVInt7)
This kind of works if you remember to thread everything through
Maybe (or Either) or what have you. But this is not
ideal. You should be able to know, at compile-time, that your Expr
is valid. After all, you want to be able to create one “valid”
Expr, and run it at every context. It’s useless to you if every
single time you used an Expr, you had to manually handle the
Nothing case. Your diagram generator, your Haskell runner, your
code generator, will always be in Either even though you know your
Expr is valid, via tests or something. We want GHC to reject badly
typed expressions, so we never need to unwrap or handle a Nothing
or Left!
No, no, this is not okay and not acceptable. We should be able to verify in
the types if an Expr is valid.
Type-Indexed Expressions
Just Add the Index
The next step you’ll see in posts online is to add a phantom index type to
Expr:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage2.hs#L19-L49typedataTy=TInt|TBool|TString|Ty:->TydataPrim ::Ty->TypewherePInt ::Int->PrimTIntPBool ::Bool->PrimTBoolPString ::String->PrimTStringdataOp ::Ty->Ty->Ty->TypewhereOPlus ::OpTIntTIntTIntOTimes ::OpTIntTIntTIntOLte ::OpTIntTIntTBoolOAnd ::OpTBoolTBoolTBooldataExpr ::Ty->TypewhereEPrim ::Prim t ->Expr tEVar ::STy t ->String->Expr tELambda ::STy a ->String->Expr b ->Expr (a :-> b)EApply ::Expr (a :-> b) ->Expr a ->Expr bEOp ::Op a b c ->Expr a ->Expr b ->Expr c
(We’ll explain each part of this declaration eventually)
A phantom type is a type parameter that doesn’t represent any actual
value “contained” inside the data type, but just serves to “tag” or
distinguish values for the compiler to reject or unify things in useful
ways.
This introduces several new language features, so bear with me as I break
them down.
First, we use -XTypeData to define a data kind: Ty
is a kind with types TInt :: Ty, TBool :: Ty, etc. And
in Expr t, we have an expression tagged with t, which
describes the result type. (In fact, all data types are automatically
promoted to the type level with -XDataKinds. You might see the
'Nothing quote prefix syntax in cases where it’s ambiguous if
you’re talking about the data constructor or the type constructor, like
'[] and '(,))
For example, because we have EPrim :: Prim t -> Expr t, and
PInt 3 :: Prim TInt, we have
EPrim (PInt 3) :: Expr TInt: a primitive 3 is an expression
describing an integer.
And because
EOp :: Op a b c -> Expr a -> Expr b -> Expr c, and
OLte :: Op TInt TInt TBool, we have
EOpOLte ::ExprTInt->ExprTInt->ExprTBool
So we can write an operation on two Exprs that typecheck how
we’d expect:
Because of Ty, we can also make a new indexed data type with
phantoms of “fully resolved” values:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage2.hs#L115-L119dataEValue ::Ty->TypewhereEVInt ::Int->EValueTIntEVBool ::Bool->EValueTBoolEVString ::String->EValueTStringEVFun :: (EValue a ->Maybe (EValue b)) ->EValue (a :-> b)
This is what we want to eventually eval into, as we can
guarantee ourselves to get a value of the correct type based on the
Ty:
eValueToInt ::EValueTInt->InteValueToInt = \caseEVInt x -> x
And GHC will verify this as a total pattern match because EVInt
is the only possible way to create an EValue TInt.
Singletons and Existentials
We’ll keep our bound variables stored as an ambient map of variable names to
their evaluated values for now. But, to do this, we need to turn the
heterogeneous EValue t into the homogeneous
Map String SomeValue by wrapping the type variable as an
existential type.
You might notice we have a singleton
for our Ty type, STy, that pops up in multiple
situations.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage2.hs#L27-L31dataSTy ::Ty->TypewhereSTInt ::STyTIntSTBool ::STyTBoolSTString ::STyTStringSTFun ::STy a ->STy b ->STy (a :-> b)
Firstly, it might help to recognize the general pattern where
STy (the singleton) appears. It usually pops up whenever
we have existentially scoped variables, like in
data SomeValue = forall t. SomeValue (STy t) (EValue t). In this
case, the t is completely lost to the outside world, and
STy t is used to allow us to recover a runtime witness to what
t was, after pattern matching on STy. This is the
dependent sum pattern, and is similar to how Typeable is
used in Data.Dynamic.
In our case, because variables are still stored ambiently in the environment
and validated at runtime, we do need singletons to implement
eval . The type Expr t only specifies the type of the
result, but the type information of the ambient variables is not available. So,
you can write EVar STInt "myVar" :: Expr TInt, but:
myVar might not be a variable in scope at all, so
eval will fail at runtime
myVar might be in scope, but might be a TString
and not a TInt
The first case is easy enough to deal with (M.lookup returns
Nothing), but the second one is a little more subtle. Let’s say we
do have a SomeValue under our key myVar…how
do we make sure it has the correct type?
Runtime Type Equality
We can do ad-hoc pattern matching on EValue, but that won’t get
us too far. Mostly because some of the EValue constructors actually
don’t have enough information for us to validate their actual type (try it!
EVFun will give you a lot of trouble). So, what we can do is write
a function that takes two STy at runtime and unifies them
conditionally if they are the same. We’ll write a function
sameTy :: STy a -> STy b -> Maybe (a :~: b), where
data (:~:) :: k -> k ->TypewhereRefl :: a :~: a
pattern matching on a value of type a :~: b will reveal
that a and b are the same type variable, because the
only way to construct it is with Refl :: a :~: a.
With that, we can write sameTy:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage2.hs#L133-L143sameTy ::STy a ->STy b ->Maybe (a :~: b)sameTy = \caseSTInt-> \caseSTInt->JustRefl; _ ->NothingSTBool-> \caseSTBool->JustRefl; _ ->NothingSTString-> \caseSTString->JustRefl; _ ->NothingSTFun a b -> \caseSTFun c d ->doRefl<- sameTy a cRefl<- sameTy b dJustRefl _ ->Nothing
There’s a typeclass in base (or rather, a “kindclass”),
TestEquality, that encapsulates this pattern:
classTestEquality f where testEquality :: f a -> f b ->Maybe (a :~: b)
We’re now at a higher fanciness level than before. But you might see the
problem here: EVar STInt "x". x might not be defined,
and it also might not have the correct type. Soooo yes, we still have issues
here.
But now at least we can write eval:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage2.hs#L145-L176eval ::MapStringSomeValue->Expr t ->Maybe (EValue t)eval env = \caseEPrim (PInt n) ->pure (EVInt n)EPrim (PBool b) ->pure (EVBool b)EPrim (PString s) ->pure (EVString s)EVar t v ->doSomeValue t' v' <- M.lookup v envRefl<- sameTy t t'pure v'ELambda ta n body ->pure$EVFun$ \x -> eval (M.insert n (SomeValue ta x) env) bodyEApply f x ->doEVFun g <- eval env f x' <- eval env x g x'EOp o x y ->case o ofOPlus->doEVInt a <- eval env xEVInt b <- eval env ypure (EVInt (a + b))OTimes->doEVInt a <- eval env xEVInt b <- eval env ypure (EVInt (a * b))OLte->doEVInt a <- eval env xEVInt b <- eval env ypure (EVBool (a <= b))OAnd->doEVBool a <- eval env xEVBool b <- eval env ypure (EVBool (a && b))
This does seem to work:
ghci> for_ (eval M.empty fifteen) \caseEVInt x ->print x15
Our system also allows us to produce closures and functions as values:
ghci> for_ (eval M.empty plusThree) \caseEVFun f -> for_ (f (EVInt4)) \caseEVInt x ->print x -- compiler-verified to always be EVInt7
We have a type-safe eval now that will create a value of the
type we want. But we still have the same errors when looking at variables:
variables can still not be defined, or be defined as the wrong type.
Pretty-Printing
One nice consequence of this type-index method is that if you choose to
consume them into an untyped target, you can do it more or less in the same way
as the non-indexed untyped data.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage2.hs#L87-L113ppPrim ::Prim t ->PP.Doc annppPrim = \casePInt n -> PP.pretty nPBool b ->if b then"true"else"false"PString s -> PP.pretty (show s)ppOp ::Op a b c ->PP.Doc annppOp = \caseOPlus->"+"OTimes->"*"OLte->"<="OAnd->"&&"ppExpr ::Bool->Expr t ->PP.Doc annppExpr paren = \caseEPrim p -> ppPrim pEVar _ v -> PP.pretty vELambda _ n body -> wrap $"\\"<> PP.pretty n <+>"->"<+> ppExpr False bodyEApply f x -> wrap $ ppExpr True f <+> ppExpr True xEOp o x y -> wrap $ ppExpr True x <+> ppOp o <+> ppExpr True ywhere wrap| paren = PP.parens|otherwise=idprettyExpr ::Expr t ->PP.Doc annprettyExpr = ppExpr False
And they render the same way:
ghci> prettyExpr fifteen(\x -> x *3) 5ghci> prettyExpr plusThree\x -> x +3ghci> prettyExpr badVariable(\x -> x +3) true
Still Not Fully Verified
Implicit in the previous section was the admission of failure: this system
lets us use indexed types to help propagate unification (the result types of
OLte, OAnd, OPlus, etc.), but it can’t
prevent all ill-defined programs from compiling.
The issue is EVar: its type
EVar :: STy t -> String -> Expr t lets us bind any
variable name as any type, and it’ll still typecheck. Even with the
help of everything we have, we can just straight-up declare a reference to an
unbound variable
That’s because EVar can freely take any STy without
any restriction, and no association with the binder name, so there’s no way for
GHC to stop us.
So, again, we cannot create a fully type-checked Expr.
We still have to deal with most of the same errors. This is noble, but
clearly not good enough. We have to go deeper.
Typed Records and Sums
A quick detour: you might have noticed that this past implementation dropped
records and sums. Before we move on, let’s go ahead and add those. Introducing
records and sums at the same time as type-indexed Expr is a bit
too much of a jump to fit into a single section.
Let’s add sums and records, which can use pretty similar mechanisms (via
duality) for implementation.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L31-L79typedataTy=TInt|TBool|TString|TRecord [(Symbol, Ty)]|TSum [(Symbol, Ty)]|Ty:->TydataSTy ::Ty->TypewhereSTInt ::STyTIntSTBool ::STyTBoolSTString ::STyTStringSTRecord ::RecSTyField as ->STy (TRecord as)STSum ::RecSTyField as ->STy (TSum as)STFun ::STy a ->STy b ->STy (a :-> b)
Ty now includes TRecord [(Symbol, Ty)] and
TSum [(Symbol, Ty)], which represent the field names and
constructor payloads (Symbol being a type-level string). So, for
example, TRecord ["value" ::: TInt, "label" ::: TString] would be
the type of a record with ordered fields value and
label of integers and strings, respectively.
TSum ["Found" ::: TInt, "Missing" ::: TString] would be the type of
a sum between Found containing an integer and Missing
containing a string. Note we take a page out of vinyl by defining the type
alias (:::) = '(,) to make things syntactically nicer.
Record Access
We need the fields and types at the type level because we have to answer what
the Expr phantom type of field access is. If we had an
x :: Expr (TRecord ["value" ::: TInt, "label" ::: TString]), we
want the type of x.value to be Expr TInt.
To do this, we need to have a value in our Expr for
field access that can “point” at a specific field in the type. One way to do
that is to take a field of type Index:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L47-L49dataIndex :: [k] -> k ->TypewhereIZ ::Index (x : xs) xIS ::Index xs x ->Index (y : xs) x
You can read this as: “IZ is an index to the head of the
type-level list, and IS n is an index to the n-th item of the
tail”. So, IS IZ is an index into the second element,
IS (IS IZ) is an index into the third, etc.
If we have ["value" ::: TInt, "label" ::: TString], then we have
values:
IZ ::Index ["value":::TInt, "label":::TString] ("value":::TInt)ISIZ ::Index ["value":::TInt, "label":::TString] ("label":::TString)
Note that the way this is constructed, it’s impossible for
IS (IS IZ) :: Index ["value" ::: TInt, "label" ::: TString] _ to
typecheck as anything!
In this way, we have a well-typed field accessor syntax, which takes an
Expr of a record of fields and indexes it to get an
Expr of the type at that index:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L105-L105EAccess ::KnownSymbol l =>Expr (TRecord as) ->Index as (l ::: a) ->Expr a
To create an Expr of a record, we can use
Rec from vinyl or
NP from sop-core: a
heterogeneous list indexed by a type-level list.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L43-L45dataRec :: (k ->Type) -> [k] ->TypewhereRNil ::Rec f '[] (:&) :: f x ->Rec f xs ->Rec f (x : xs)
If you haven’t seen Rec before, basically
Rec f [a,b,c] is a tuple of f a, f b, and
f c. For example:
Keeping Rec f as instead of a direct heterogeneous list of
as lets us store more interesting things than just
Type-kinded things. For example, since our lists here are lists of
(Symbol, Ty), we can create a container to hold fields:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L109-L110dataExprField :: (Symbol, Ty) ->TypewhereEField ::KnownSymbol l =>Expr a ->ExprField (l ::: a)
The field constructor keeps a KnownSymbol l constraint, so the
type-level label is still available later when we need to render it:
So, we can create
Expr (TRecord ["value" ::: TInt, "label" ::: TString]) by taking a
Rec:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L104-L104ERecord ::RecExprField as ->Expr (TRecord as)
We can make this a little more ergonomic by using
-XRequiredTypeArguments (as of GHC 9.10) to get rid of the
-XTypeApplication ugliness:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L115-L150eField ::forall l ->KnownSymbol l =>Expr a ->ExprField (l ::: a)eField l =EField@lmakeRecordExample ::Expr (TRecord ["value":::TInt, "label":::TString])makeRecordExample =ERecord ( eField "value" (EPrim (PInt7)):& eField "label" (EPrim (PString"found")):&RNil )recordExample ::ExprTIntrecordExample =EOpOPlus (EAccess@"value" makeRecordExample IZ) (EPrim (PInt1))
Sum Injection and Case Analysis
We also need a type-level list witness for sum types, because we
need to be able to implement the correct continuations for pattern matches: How
do we know what thing to handle in each pattern match, unless the sum
type has that information in its type?
Luckily due to the magic of duality, we can use the same tools, for the most
part! We can inject into a sum with an Index, let’s say for a
Expr (TSum ["Found" ::: TInt, "Missing" ::: TString]): sum type
with Found containing an integer and Missing
containing a string:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L106-L106EChoice ::KnownSymbol l =>Index as (l ::: a) ->Expr a ->Expr (TSum as)
And we can re-use Rec to define a type that can handle
a ["Found" ::: TInt, "Missing" ::: TString] sum:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L112-L133dataExprHandler ::Ty-> (Symbol, Ty) ->TypewhereEHandler ::KnownSymbol l =>STy a ->String->Expr b ->ExprHandler b (l ::: a)eHandler ::forall l ->KnownSymbol l =>STy a ->String->Expr b ->ExprHandler b (l ::: a)eHandler l =EHandler@l
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L107-L107ECase ::Expr (TSum as) ->Rec (ExprHandler b) as ->Expr b
Note that we’re still using string binders, so there’s still an element of
unsafety here… we say that the variable name is "value" and that it
is a TInt, but when we later refer to the variable with
EVar STInt "value", it isn’t type-checked that later references use
the same type. The compiler would be just as happy with
EVar STString "value".
Here’s an example demonstrating both failure modes: the first handler
references a variable that doesn’t exist, and the second handler references a
variable that does exist as an incorrect type! How unfortunate.
One complication is that we need to update the TestEquality
instance for STy. The record and sum labels are type-level
Symbols, so we compare those with the sameSymbol (kind
of like testEquality for any KnownSymbol instance) and
then compare the payload types recursively.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L284-L324instanceTestEqualitySTywhere testEquality = sameTyinstanceTestEqualitySTyFieldwhere testEquality = sameFieldsameTy ::STy a ->STy b ->Maybe (a :~: b)sameTy = \caseSTInt-> \caseSTInt->JustRefl; _ ->NothingSTBool-> \caseSTBool->JustRefl; _ ->NothingSTString-> \caseSTString->JustRefl; _ ->NothingSTRecord as -> \caseSTRecord bs ->doRefl<- sameFields as bsJustRefl _ ->NothingSTSum as -> \caseSTSum bs ->doRefl<- sameFields as bsJustRefl _ ->NothingSTFun a b -> \caseSTFun c d ->doRefl<- sameTy a cRefl<- sameTy b dJustRefl _ ->NothingsameFields ::RecSTyField xs ->RecSTyField ys ->Maybe (xs :~: ys)sameFields RNilRNil=JustReflsameFields (x :& xs) (y :& ys) =doRefl<- sameField x yRefl<- sameFields xs ysJustReflsameFields _ _ =NothingsameField ::STyField x ->STyField y ->Maybe (x :~: y)sameField (STyField@l tx) (STyField@m ty) =doRefl<- sameSymbol (Proxy@l) (Proxy@m)Refl<- sameTy tx tyJustRefl
The Full Eval
Before we write the final eval, let’s practice using
Index and Rec together. If we have an index
Index as a that picks out a value a in
as, then we can pick out the f a from a
Rec f as:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L60-L63indexRec ::Index xs x ->Rec f xs -> f xindexRec = \caseIZ-> \(x :& _) -> xIS i -> \(_ :& xs) -> indexRec i xs
We also can recursively iterate a function over each item, assuming the
function forall x. f x -> g x: that is, we can turn a
Rec f as into a Rec g as assuming our function is
polymorphic over each x, and only depends on the shape of
f.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L65-L67traverseRec ::Applicative m => (forall x. f x -> m (g x)) ->Rec f xs -> m (Rec g xs)traverseRec _ RNil=pureRNiltraverseRec f (x :& xs) = (:&) <$> f x <*> traverseRec f xs
With that, we can write our full eval.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L326-L369eval ::MapStringSomeValue->Expr t ->Maybe (EValue t)eval env = \caseEPrim (PInt n) ->pure (EVInt n)EPrim (PBool b) ->pure (EVBool b)EPrim (PString s) ->pure (EVString s)EVar t v ->doSomeValue t' v' <- M.lookup v envRefl<- sameTy t t'pure v'ELambda ta n body ->pure$EVFun$ \x -> eval (M.insert n (SomeValue ta x) env) bodyEApply f x ->doEVFun g <- eval env f x' <- eval env x g x'EOp o x y ->case o ofOPlus->doEVInt a <- eval env xEVInt b <- eval env ypure (EVInt (a + b))OTimes->doEVInt a <- eval env xEVInt b <- eval env ypure (EVInt (a * b))OLte->doEVInt a <- eval env xEVInt b <- eval env ypure (EVBool (a <= b))OAnd->doEVBool a <- eval env xEVBool b <- eval env ypure (EVBool (a && b))ERecord xs ->EVRecord<$> traverseRec (evalField env) xsEAccess e i ->doEVRecord xs <- eval env ecase indexRec i xs ofEVField v ->pure vEChoice i x ->EVSum i <$> eval env xECase x hs ->doEVSum i v <- eval env xcase indexRec i hs ofEHandler t n body -> eval (M.insert n (SomeValue t v) env) body
Ergonomics of Records and Sums
Note that we could also choose to implement records and sums using row types
indexed by the name of the field itself, instead of an ordered list of tuples.
This would have the advantage of making, for example,
{ value :: Int, label :: String } the same type as
{ label :: String, value :: Int }. However, I personally prefer the
style of building things inductively (:&/RNil and
IS/IZ), it makes the type errors and constructions a
lot easier to work with and reason with.
However, we can get a little bit of the best of both worlds by using
typeclasses to auto-insert the Index witnesses into a list.
First, we can write a typeclass that searches a type-level list of fields and
produces the right Index:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L51-L58classListIx (l ::Symbol) (xs :: [(Symbol, Ty)]) (a ::Ty) | l xs -> a where listIx ::Index xs (l ::: a)instanceListIx l (l ::: a : xs) a where listIx =IZinstance{-# OVERLAPPABLE #-}ListIx l xs a =>ListIx l (m ::: b : xs) a where listIx =IS (listIx @l)
The FunDep l xs -> a lets us use this like a function: for a
label l and a list xs, we should be able to uniquely
determine the a type it singles out, if it exists. So we have an
instance of
ListIx "value" ["value" ::: TInt, "label" ::: TString] TInt, where
the label "value" and the list uniquely determines the result type
TInt.
We can now have a helper function that we can call like
eAccess "value" using GHC 9.10’s
RequiredTypeArguments:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L118-L123eAccess ::forall (l ::Symbol) -> (KnownSymbol l, ListIx l as a) =>Expr (TRecord as) ->Expr aeAccess l e =EAccess@l e (listIx @l)
That lets us write the field name directly, and the compiler will generate
the Index automatically for us:
Here,
eAccess "value" :: Expr (TRecord ["value" ::: TInt, "label" ::: TString]) -> Expr TInt,
its result type uniquely determined by the types in the record fields.
The same trick works for sum injections, so we can write the constructor name
directly:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L125-L179eChoice ::forall (l ::Symbol) -> (KnownSymbol l, ListIx l as a) =>Expr a ->Expr (TSum as)eChoice l e =EChoice@l (listIx @l) enamedChoiceExample ::Expr (TSum ["Found":::TInt, "Missing":::TString])namedChoiceExample = eChoice "Missing" (EPrim (PString"not here"))
Here,
eChoice "Missing" :: Expr TString -> Expr (TSum ["Found" ::: TInt, "Missing" ::: TString]),
because the constructor name "Missing" uniquely determines the
payload type inside that sum.
Pretty-Printing Records and Sums
To pretty-print, we finally use that KnownSymbol constraint
we’ve been tracking this entire time. We can use
symbolVal :: KnownSymbol s => p s -> String to get the string
value from the type-level string.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage3.hs#L237-L282ppPrim ::Prim t ->PP.Doc annppPrim = \casePInt n -> PP.pretty nPBool b ->if b then"true"else"false"PString s -> PP.pretty (show s)ppOp ::Op a b c ->PP.Doc annppOp = \caseOPlus->"+"OTimes->"*"OLte->"<="OAnd->"&&"ppFields ::RecExprField xs -> [PP.Doc ann]ppFields RNil= []ppFields (EField@l x :& xs) = (PP.pretty (symbolVal (Proxy@l)) <+>"="<+> ppExpr False x) : ppFields xsppHandlers ::Rec (ExprHandler b) xs -> [PP.Doc ann]ppHandlers RNil= []ppHandlers (EHandler@l _ n body :& xs) = (PP.pretty (symbolVal (Proxy@l)) <+> PP.pretty n <+>"->"<+> ppExpr False body) : ppHandlers xsppExpr ::Bool->Expr t ->PP.Doc annppExpr paren = \caseEPrim p -> ppPrim pEVar _ v -> PP.pretty vELambda _ n body -> wrap $"\\"<> PP.pretty n <+>"->"<+> ppExpr False bodyEApply f x -> wrap $ ppExpr True f <+> ppExpr True xEOp o x y -> wrap $ ppExpr True x <+> ppOp o <+> ppExpr True yERecord xs -> PP.encloseSep "{ "" }"", " (ppFields xs)EAccess@l e _ -> ppExpr True e <>"."<> PP.pretty (symbolVal (Proxy@l))EChoice@l _ x -> wrap $ PP.pretty (symbolVal (Proxy@l)) <+> ppExpr True xECase x hs -> wrap $ PP.sep [ "case"<+> ppExpr False x <+>"of" , PP.encloseSep "{ "" }""; " (ppHandlers hs) ]where wrap| paren = PP.parens|otherwise=idprettyExpr ::Expr t ->PP.Doc annprettyExpr = ppExpr False
Capturing Variables
In order to have EVar be type-safe, the environment itself needs
to be a part of the Expr type, and you should only be able to use
EVar if the Expr enforces it. ELambda
would, therefore, introduce the new variable to the environment.
So a value of type Expr ["x" ::: TInt, "y" ::: TBool] t is an
expression with free variables x of type Int and
y of type Bool.
Surprise! That small detour to add records and sums to our language actually
ended up being a smooth precursor to all of the techniques we will be using to
solve for variable binders.
ELambda would therefore take an Expr with a free
variable and turn it into an Expr of a function type. We also keep
a KnownSymbol constraint for the name so that we can recover the
name when we render the expression.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L83-L83ELambda ::KnownSymbol n =>Expr (n ::: a ': vs) b ->Expr vs (a :-> b)
EVar then becomes exactly like EAccess! We “index”
into the environment of the Expr vs a using Index:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L82-L82EVar ::Index vs (n ::: t) ->Expr vs t
So it is legal to have
EVar IZ :: Expr ["x" ::: TInt, "y" ::: TBool] TInt, and also it is
automatically inferred to be a TInt. But we could not
write EVar IZ :: Expr [] TInt.
And finally, our whole Expr:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L80-L89dataExpr :: [(Symbol, Ty)] ->Ty->TypewhereEPrim ::Prim t ->Expr vs tEVar ::Index vs (n ::: t) ->Expr vs tELambda ::KnownSymbol n =>Expr (n ::: a ': vs) b ->Expr vs (a :-> b)EApply ::Expr vs (a :-> b) ->Expr vs a ->Expr vs bEOp ::Op a b c ->Expr vs a ->Expr vs b ->Expr vs cERecord ::Rec (ExprField vs) as ->Expr vs (TRecord as)EAccess ::KnownSymbol l =>Expr vs (TRecord as) ->Index as (l ::: a) ->Expr vs aEChoice ::KnownSymbol l =>Index as (l ::: a) ->Expr vs a ->Expr vs (TSum as)ECase ::Expr vs (TSum as) ->Rec (ExprHandler vs b) as ->Expr vs b
Just like with record access, we can use the ListIx class to
write a named helper:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L47-L120classListIx (l ::Symbol) (xs :: [(Symbol, Ty)]) (a ::Ty) | l xs -> a where listIx ::Index xs (l ::: a)instanceListIx l (l ::: a ': xs) a where listIx =IZinstance{-# OVERLAPPABLE #-}ListIx l xs a =>ListIx l (m ::: b ': xs) a where listIx =IS (listIx @l)eVar ::forall n ->ListIx n vs a =>Expr vs aeVar n =EVar (listIx @n)
Adding in our other -XRequiredTypeArguments helpers:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L91-L117eLambda ::forall n ->KnownSymbol n =>Expr (n ::: a ': vs) b ->Expr vs (a :-> b)eLambda n =ELambda@neField ::forall l ->KnownSymbol l =>Expr vs a ->ExprField vs (l ::: a)eField l =EField@leAccess ::forall l -> (KnownSymbol l, ListIx l as a) =>Expr vs (TRecord as) ->Expr vs aeAccess l e =EAccess@l e (listIx @l)eChoice ::forall l -> (KnownSymbol l, ListIx l as a) =>Expr vs a ->Expr vs (TSum as)eChoice l e =EChoice@l (listIx @l) eeHandler ::forall n ->forall l -> (KnownSymbol n, KnownSymbol l) =>Expr (n ::: a ': vs) b ->ExprHandler vs b (l ::: a)eHandler n l =EHandler@n @l
And we get something that is truly type-safe: all expressions are
well-typed, and all variables are ensured to be bound!
Expressions that are not well-typed in our domain language are now rejected
by GHC!1
(As an exercise, can understand why those errors are what they are? Why they
all contain ListIx _ '[]? For more ergonomics there is stuff we can
do with TypeError machinery to make the messages a little prettier;
the vinyl library does a lot to make error messages a bit better, like
in HasFieldinstance)
Note that this is sometimes done using straight De Bruijn indices:
Expr :: [Ty] -> Type, so we don’t use any names but just the
direct index, but the point of this exercise is to be borderline
unbearable to write, and not to be actually unbearable to
write.
Eval with a typed environment
To actually write eval now, we need to have a type-safe environment
to store these variables. In order to eval an Expr vs,
we need EValues for each v in vs. So for
Expr ["x" ::: TInt, "y" ::: TBool], we need to store a
TInt and a TBool. We can once again re-purpose
Rec:
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L130-L131dataEValueField :: (Symbol, Ty) ->TypewhereEVField ::EValue a ->EValueField '(l, a)
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L122-L271dataEValue ::Ty->TypewhereEVInt ::Int->EValueTIntEVBool ::Bool->EValueTBoolEVString ::String->EValueTStringEVRecord ::RecEValueField as ->EValue (TRecord as)EVSum ::Index as (l ::: a) ->EValue a ->EValue (TSum as)EVFun :: (EValue a ->EValue b) ->EValue (a :-> b)eval ::RecEValueField vs ->Expr vs t ->EValue teval env = \caseEPrim (PInt n) ->EVInt nEPrim (PBool b) ->EVBool bEPrim (PString s) ->EVString sEVar i ->case indexRec i env ofEVField v -> vELambda body ->EVFun$ \x -> eval (EVField x :& env) bodyEApply f x ->case eval env f ofEVFun g -> g (eval env x)EOp o x y ->case (o, eval env x, eval env y) of (OPlus, EVInt a, EVInt b) ->EVInt (a + b) (OTimes, EVInt a, EVInt b) ->EVInt (a * b) (OLte, EVInt a, EVInt b) ->EVBool (a <= b) (OAnd, EVBool a, EVBool b) ->EVBool (a && b)ERecord xs ->EVRecord$ mapRec (\(EField x) ->EVField (eval env x)) xsEAccess e i ->case eval env e ofEVRecord xs ->case indexRec i xs ofEVField v -> vEChoice i x ->EVSum i (eval env x)ECase x hs ->case eval env x ofEVSum i y ->case indexRec i hs ofEHandler h -> eval (EVField y :& env) h
At least, we are here. A type-safe EDSL where only AST’s that can be validly
evaluated are legal to represent in Haskell. At least, we can embrace the
freedom of not having to carefully construct your terms. You can relax now. The
compiler and the types have your back.
Even
EVFun :: (EValue a -> EValue b) -> EValue (a :-> b) has a
total EValue a -> EValue b, making the closure evaluation also
fully total.
ghci>case eval RNil plusThree ofEVFun f ->case f (EVInt4) ofEVInt x ->print x7
Pretty-Printing Scoped
Expressions
Now to get to the entire utility of this abstraction: inspecting and
consuming the structure. For our new structure, we took out the string name from
EVar in lieu of an index. This is intentional, so that we keep the
“responsibility” of storing the string name at the ELambda
constructor and not have EVar redundantly store it.
However, this means that for pretty-printing, we will need to track the
variable names in the environment as we descend into lambdas. This is done very
similar to how it was done in eval, but instead of tracking and
indexing out the evaluated EValues, we track and index out the
string names of each variable instead.
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L182-L183dataNameField :: (Symbol, Ty) ->TypewhereNameField ::KnownSymbol l =>NameField (l ::: a)
ghci>:t NameField@"hello":&NameField@"world":&RNilRecNameField ["hello"::: a, "world"::: b]
-- source: https://github.com/mstksg/inCode/tree/master/code-samples/typed-sm-lc/ExprStage4.hs#L185-L245ppPrim ::Prim t ->PP.Doc annppPrim = \casePInt n -> PP.pretty nPBool b ->if b then"true"else"false"PString s -> PP.pretty (show s)ppOp ::Op a b c ->PP.Doc annppOp = \caseOPlus->"+"OTimes->"*"OLte->"<="OAnd->"&&"ppFields ::RecNameField vs ->Rec (ExprField vs) xs -> [PP.Doc ann]ppFields _ RNil= []ppFields names (EField@l x :& xs) = (PP.pretty (symbolVal (Proxy@l)) <+>"="<+> ppExpr names False x) : ppFields names xsppHandlers ::RecNameField vs ->Rec (ExprHandler vs b) xs -> [PP.Doc ann]ppHandlers _ RNil= []ppHandlers names (EHandler@n @l body :& xs) = ( PP.pretty (symbolVal (Proxy@l))<+> PP.pretty (symbolVal (Proxy@n))<+>"->"<+> ppExpr (NameField@n :& names) False body ): ppHandlers names xsppExpr ::RecNameField vs ->Bool->Expr vs t ->PP.Doc annppExpr names paren = \caseEPrim p -> ppPrim pEVar i ->case indexRec i names ofNameField@n -> PP.pretty (symbolVal (Proxy@n))ELambda@n body -> wrap $"\\"<> PP.pretty (symbolVal (Proxy@n))<+>"->"<+> ppExpr (NameField@n :& names) False bodyEApply f x -> wrap $ ppExpr names True f <+> ppExpr names True xEOp o x y -> wrap $ ppExpr names True x <+> ppOp o <+> ppExpr names True yERecord xs -> PP.encloseSep "{ "" }"", " (ppFields names xs)EAccess@l e _ -> ppExpr names True e <>"."<> PP.pretty (symbolVal (Proxy@l))EChoice@l _ x -> wrap $ PP.pretty (symbolVal (Proxy@l)) <+> ppExpr names True xECase x hs -> wrap $ PP.sep [ "case"<+> ppExpr names False x <+>"of" , PP.encloseSep "{ "" }""; " (ppHandlers names hs) ]where wrap| paren = PP.parens|otherwise=idprettyExpr ::Expr '[] t ->PP.Doc annprettyExpr = ppExpr RNilFalse
ghci> prettyExpr fifteen(\x -> x *3) 5
The Next Step
Well, we set out with a simple goal: an expression language that lives within
Haskell that we can inspect and interrogate within the language, but where it
was impossible to construct (in Haskell) a term that did not type-check (in the
domain language).
But, honestly, why does it matter that our expression language has to reject
invalid domain-level terms at the Haskell level? Why couldn’t we go the way of
other expression DSLs in Haskell, where we settle with “untyped” terms being
expressible in Haskell, and validated using a separate typeCheck
function to validate terms at runtime?
I don’t know. But really, maybe this is another way of taking the old Parse,
Don’t Validate adage to the extreme. Why allow yourself to construct invalid
terms of your domain inside Haskell? Why use a “validate” function
(isValid) when you can just make invalid terms impossible to
construct?
But…no. There is no other choice. We CANNOT allow invalid domain terms to be
constructible. If we have the ability to do better, we MUST. With great power
comes great responsibility. And if we compromise here, how can we trust
ourselves not to compromise when it really matters?
One must imagine the stubborn typer happy.
In Part 2, we’ll use our new EDSL to specify visualizable state machines and
programs within Haskell that are type-checked to be correct, and what it looks
like to actually use these within Haskell. And in Part 3, we’ll start
“compiling” them to different language targets and different backends, with the
assurance that our generated programs are all synchronized and
self-consistent.
A Note on AI Coding
I guess I’m going to have to start mentioning this in every post.
But, I really do feel like this “extreme type safety” approach is more
critical than ever, in the age of agentic coding and LLM. I’ve been using LLMs
in my daily coding for many months now at this point, and one common pattern
I’ve noticed: when I start with a design with very clear, very strict types,
LLMs excel. They make much fewer errors, and the type system provides more
immediate feedback on their progress, without needing hundreds of defensive
x != null-style guard pollution.
Once I can express what I want in the language of extreme “invalid states
unrepresentable” types, LLM agents no longer feel like agents of chaotic
spaghetti extruding unmaintainable code. Instead, it feels like…seeding a
crystal and watching it grow into a beautiful, shimmering lattice. It feels like
the language they yearn to speak. And the more expressive your types, the more
beautiful the crystalline structure in the end.
Honestly, humans might have problems writing and using this code, but LLMs
definitely don’t, if properly scaffolded! Since early 2026, at least, for me.
We’ll explore a bit more about this once we have more to work with in Part
2.
Special Thanks
I am very humbled to be supported by an amazing community, who make it
possible for me to devote time to researching and writing these posts. Very
special thanks to my supporter at the “Amazing” level on patreon, Josh Vera! :)
Excluding _|_ in Haskell-land (recursion or
undefined), unfortunately.↩︎
I've spent about 100 hours of work over the past month to make sure
git-annex can build without dependencies that contain LLM generated code.
At least so far.
Needing to review a program's whole dependency tree on an ongoing basis is
apparently what programming has come to?
I've found some real stinkers. Large LLM generated changes being reverted
in the next release without any explanation. An incoherent 1489 line
commit message with 10,000 lines of changes to a 26,000 LOC code base.
A LLM prompt to copy code from another project that seems to have only
avoided being copyright infringement due to luck.
I now have additional information about the quality of dependencies
which will surely influence future decisions. As far as I
can see, that's the only positive benefit of this work.
I realize that I am probably trying to hold back the tide at this point.
That appears to be why Software Freedom Conservancy
punted,
and I doubt that the FSF will do any better.
As these dominos fall, I am reconsidering my participation in these
communities. But I continue my work and support my users.
It may seem easy to prompt a LLM with
Add fourmolu config and restyled
neat
format a module
And commit the result and call yourself a 10xer.
But please consider the broader impact of your actions.
(In the above case, that project lost my further collaboration on it.)
I am a Distinguished Reviewer of GPCE 2026, colocated with ECOOP in Brussels. The award went to two out of a program committee of 33, putting me in the top 6%.
Update June 2026 This blog is about drawing finite regions of the infinite non-periodic tessellations of Roger Penrose’s kite and dart tiles. It was first written before developing a Haskell package (PenroseKiteDart) now available on Hackage. More info and developments can be seen at the end. I have made small updates to this blog to keep it compatible with later developments (and it is no longer a complete literate Haskell file).
Introduction
As part of a collaboration with Stephen Huggett, working on some mathematical properties of Penrose tilings, I recognised the need for quick renderings of tilings. I thought Haskell diagrams would be helpful here, and that turned out to be an excellent choice. Two dimensional vectors were well-suited to describing tiling operations and these are included as part of the diagrams package.
The Haskell below uses the Haskell Diagrams package to draw tilings with kites and darts. It also implements compChoices and decompPatch which are used for constructing tilings (explained below).
Firstly, these 5 lines are needed in Haskell to use the diagrams package:
{-# LANGUAGE NoMonomorphismRestriction #-}{-# LANGUAGE FlexibleContexts #-}{-# LANGUAGE TypeFamilies #-}importDiagrams.PreludeimportDiagrams.Backend.SVG.CmdLine
and we will also import a module for half tiles (explained later)
importHalfTile
Legal tilings
These are the kite and dart tiles.
Figure: Kite and Dart
The red line marking here on the right hand copies, is purely to illustrate rules about how tiles can be put together for legal (non-periodic) tilings. Obviously edges can only be put together when they have the same length. If all the tiles are marked with red lines as illustrated on the right, the vertices where tiles meet must all have a red line or none must have a red line at that vertex. This prevents us from forming a simple rombus by placing a kite top at the base of a dart and thus enabling periodic tilings.
All edges are powers of the golden section which we write as phi.
phi::Doublephi=(1.0+sqrt5.0)/2.0
So if the shorter edges are unit length, then the longer edges have length phi. We also have the interesting property of the golden section that and so
, and .
All angles in the figures are multiples of tt which is 36 deg or 1/10 turn. We use ttangle to express such angles (e.g 180 degrees is ttangle 5).
In order to implement compChoices and decompPatch, we need to work with half tiles. We now define these in the separately imported module HalfTile with constructors for Left Dart, Right Dart, Left Kite, Right Kite
dataHalfTilerep-- defined in HalfTile module=LDrep|RDrep|LKrep|RKrep
where rep is a type variable allowing for different representations. However, here, we want to use a more specific type which we call Piece.
typePiece=HalfTile[V2Double]
Here the half tiles have a simple 2D vector representation to provide orientation and scale. (Update 2026: Originally a single vector was used to represent the join edge of a half tile but now we use a list of two vectors instead).
The list of two two-dimensional vectors represents two edges of the half tile (excluding the join edge where half tiles come together). The origin for a dart is the tip, and the origin for a kite is the acute angle tip (marked in the figure with a red dot).
These are the only 4 pieces we use. They are defined oriented with the join along the x axis. In the figure they are rotated 90 degrees so the join edges are vertical (and they have also been labelled).
Perhaps confusingly, we regard left and right of a dart differently from left and right of a kite when viewed from the origin. The diagram shows the right dart before the left dart and the left kite before the right kite. Thus in a complete tile, going clockwise round the origin the right dart comes before the left dart, but the left kite comes before the right kite.
When it comes to drawing pieces, for the simplest case, we just want to draw the two tile edges of each piece (and not the join edge). These are the drawnEdges of the tile. We can also use the joinVector of the tile (which is simply the vector sum of the drawn edges) The drawnEdges are ordered starting from the origin of each piece.
For an alternative fill operation on whole tiles, we calculated a list of the 4 tile edges of a completed half-tile piece clockwise from the origin of the tile. This allows colour filling a whole tile, but it does rely on prior transformations preserving angles as it uses angles in the definition (not shown).
wholeTileEdges::Piece->[V2Double]
To fill whole tiles with colours, darts with dcol and kites with kcol we can now use leftFillPieceDK. This uses only the left pieces to identify the whole tile and ignores right pieces so that a tile is not filled twice and uses wholeTileEdges.
So we can scale and rotate a piece by an angle (positive rotations are in the anticlockwise direction) but we cannote translate until they are located (as Patches).
Here mapLoc applies a function to the piece in a located piece – producing a located diagram in this case, and viewLoc returns the pair of point and diagram from a located diagram. Finally position forms a single diagram from the list of pairs of points and diagrams. (The use of a class definition here anticipates more instances in later developments).
Patches are automatically inferred to be transformable, so we can also scale a patch, translate a patch by a vector, and rotate a patch by an angle (for example).
This figure shows some example patches, drawn with draw The first is a star and the second is a sun.
Figure: Tile Patches
The tools so far for creating patches may seem limited (and do not help with ensuring legal tilings), but there is an even bigger problem.
Correct Tilings
Unfortunately, correct tilings – that is, tilings which can be extended to infinity – are not as simple as just legal tilings. It is not enough to have a legal tiling, because an apparent (legal) choice of placing one tile can have non-local consequences, causing a conflict with a choice made far away in a patch of tiles, resulting in a patch which cannot be extended. This suggests that constructing correct patches is far from trivial.
The infinite number of possible infinite tilings do have some remarkable properties. Any finite patch from one of them, will occur in all the others (infinitely many times) and within a relatively small radius of any point in an infinite tiling. (For details of this see links at the end).
This is why we need a different approach to constructing larger patches. There are two significant processes used for creating patches, namely inflate (also called compose) and decompose.
To understand these processes, take a look at the following figure.
Figure: Experiment
Here the small pieces have been drawn in an unusual way. The edges have been drawn with dashed lines, but long edges of kites have been emphasised with a solid line and the join edges of darts marked with a red line. From this you may be able to make out a patch of larger scale kites and darts. This is an inflated patch arising from the smaller scale patch. Conversely, the larger kites and darts decompose to the smaller scale ones.
Decomposition
Since the rule for decomposition is uniquely determined, we can express it as a simple function on patches.
where the function decompPiece acts on located pieces and produces a list of the smaller located pieces contained in the piece. For example, a larger right dart will produce both a smaller right dart and a smaller left kite. Decomposing a located piece also takes care of the location, scale and rotation of the new pieces. (Revised version 2026 avoiding use of angles).
This is illustrated in the following figure for the cases of a right dart and a right kite.
Figure: Decomposition and Composition
The symmetric diagrams for left pieces are easy to work out from these, so they are not illustrated.
With the decompPatch operation we can start with a simple correct patch, and decompose repeatedly to get more and more detailed patches. (Each decomposition scales the tiles down by a factor of but we can rescale at any time.)
This figure illustrates how each piece decomposes with 4 decomposition steps below each one.
The earlier figure illustrating larger kites and darts emphasised from the smaller ones is also suns!!6 but this time pieces are drawn with experiment.
experimentFig=drawWithexperiment(suns!!6)#lwthinexperiment::Piece->DiagramBexperimentpc=emphpc<>(drawRoundPiecepc#dashingN[0.002,0.002]0#lwultraThin)whereemphpc=casepcof(LDv)->(strokeLine.fromOffsets)[v]#lcred-- emphasise join edge of darts in red(RDv)->(strokeLine.fromOffsets)[v]#lcred(LKv)->(strokeLine.fromOffsets)[rotate(ttangle1)v]-- emphasise long edge for kites(RKv)->(strokeLine.fromOffsets)[rotate(ttangle9)v]
Compose Choices
You might expect composition (also called inflation) to be a kind of inverse to decomposition, but it is a bit more complicated than that. With our current representation of pieces, we can only compose single pieces. This amounts to embedding the piece into a larger piece that matches how the larger piece decomposes. There is thus a choice at each composition step as to which of several possibilities we select as the larger half-tile. We represent this choice as a list of alternatives. This list should not be confused with a Patch. It only makes sense to select one of the alternatives giving a new single piece.
The earlier diagram illustrating how decompositions are calculated also shows the two choices for embedding a right dart into either a right kite or a larger right dart. There will be two symmetric choices for a left dart, and three choices for left and right kites.
Once again we work with located pieces to ensure the resulting larger piece contains the original in its original position in a decomposition. (Revised version 2026 avoiding use of angles).
As the result is a list of alternatives, we need to select one to do further inflations. We can express all the alternatives after n steps as compNChoices n where
This figure illustrates 5 consecutive choices for composing a left dart to produce a left kite. On the left, the finishing piece is shown with the starting piece embedded, and on the right the 5-fold decomposition of the result is shown.
Finally, at the end of this haskell program we choose which figure to draw as output.
fig::DiagramBfig=leftFilledSun6main=mainWithfig
That’s it. But, What about composing whole patches?, I hear you ask. Unfortunately we need to answer questions like what pieces are adjacent to a piece in a patch and whether there is a corresponding other half for a piece. These cannot be done with our simple vector representations. We would need some form of planar graph representation, which is much more involved. That is another story which can be found in these subsequent blogs.
Graphs, Kites and Darts intoduced Tgraphs. This gave more details of implementation and results of early explorations. (The class Forcible was introduced subsequently).
Empires and SuperForce – these new operations were based on observing properties of boundaries of forced Tgraphs.
There is also a very interesting article by Roger Penrose himself: Penrose R Tilings and quasi-crystals; a non-local growth problem? in Aperiodicity and Order 2, edited by Jarich M, Academic Press, 1989.
More information about the diagrams package can be found from the home page Haskell diagrams
In this episode of the Haskell Interlude, we are joined by Sylvain Henry, one of the all-time top contributors to GHC. He tells us about his work on GHC, the bignum library, modularization, and the secret to becoming a top contributor!
So, evidently I failed to fulfill my ambition to blog regularly about the contents of my planned book on Patterns in Functional Programming. But I have been making progress. I had the privilege of another sabbatical 2024-2025, in which I managed to draft the entire book.
It’s in short chapters, following the example set by Dexter Kozen in his lovely books: the idea is that each chapter is roughly one lecture’s worth of material. I had 40 to 50 chapter ideas, and 40 to 50 weeks in my sabbatical, so diligently stuck to one chapter per week for a year—if this week’s chapter wasn’t finished by the end of the week, it was put aside anyway in order to move on to the next chapter the following week.
That did mean that although I ended the year with a draft of the entire book, it did have many gaps and to-dos remaining. Reality hit at the end of my sabbatical in October 2025, and it has taken me the best part of another year around actual responsibilities to fill in most of the gaps and knock off most of the to-dos. I have also had the benefit of a number of readers (thank you, everyone!), with many helpful comments to implement.
But I have just yesterday sent a complete polished version to the publisher, Cambridge University Press, for the input of a professional copyeditor. I still have to construct an index, write solutions for the many exercises (which may appear separately from the book itself, in order to keep the length and hence the cost down), and make my own proof-reading pass. I am hoping to complete those tasks and implement the copyeditor’s eventual corrections over the summer, and that the book will finally appear before the end of 2026.
(Updated June 2026 for PenroseKiteDart version 1.10)
PenroseKiteDart is a Haskell package with tools to experiment with finite tilings of Penrose’s Kites and Darts. It uses the Haskell Diagrams package for drawing tilings. As well as providing drawing tools, this package introduces tile graphs (Tgraphs) for describing finite tilings. (I would like to thank Stephen Huggett for suggesting planar graphs as a way to reperesent the tilings).
This document summarises the design and use of the PenroseKiteDart package.
PenroseKiteDart package is now available on Hackage.
In figure 1 we show a dart and a kite. All angles are multiples of (a tenth of a full turn). If the shorter edges are of length 1, then the longer edges are of length , where is the golden ratio.
Figure 1: The Dart and Kite Tiles
Aperiodic Infinite Tilings
What is interesting about these tiles is:
It is possible to tile the entire plane with kites and darts in an aperiodic way.
Such a tiling is non-periodic and does not contain arbitrarily large periodic regions or patches.
The possibility of aperiodic tilings with kites and darts was discovered by Sir Roger Penrose in 1974. There are other shapes with this property, including a chiral aperiodic monotile discovered in 2023 by Smith, Myers, Kaplan, Goodman-Strauss. (See the Penrose Tiling Wikipedia page for the history of aperiodic tilings)
This package is entirely concerned with Penrose’s kite and dart tilings also known as P2 tilings.
Legal Tilings
In figure 2 we add a temporary green line marking purely to illustrate a rule for making legal tilings. The purpose of the rule is to exclude the possibility of periodic tilings.
If all tiles are marked as shown, then whenever tiles come together at a point, they must all be marked or must all be unmarked at that meeting point. So, for example, each long edge of a kite can be placed legally on only one of the two long edges of a dart. The kite wing vertex (which is marked) has to go next to the dart tip vertex (which is marked) and cannot go next to the dart wing vertex (which is unmarked) for a legal tiling.
Figure 2: Marked Dart and Kite
Correct Tilings
Unfortunately, having a finite legal tiling is not enough to guarantee you can continue the tiling without getting stuck. Finite legal tilings which can be continued to cover the entire plane are called correct and the others (which are doomed to get stuck) are called incorrect. This means that decomposition and forcing (described later) become important tools for constructing correct finite tilings.
2. Using the PenroseKiteDart Package
You will need the Haskell Diagrams package (See Haskell Diagrams) as well as this package (PenroseKiteDart). When these are installed, you can produce diagrams with a Main.hs module. This should import a chosen backend for diagrams such as the default (SVG) along with Diagrams.Prelude.
Note that the token B is used in the diagrams package to represent the chosen backend for output. So a diagram has type Diagram B. In this case B is bound to SVG by the import of the SVG backend. When the compiled module is executed it will generate an SVG file. (See Haskell Diagrams for more details on producing diagrams and using alternative backends).
3. Overview of Types and Operations
Half-Tiles
In order to implement operations on tilings (decompose in particular), we work with half-tiles. These are illustrated in figure 3 and labelled RD (right dart), LD (left dart), LK (left kite), RK (right kite). The join edges where left and right halves come together are shown with dotted lines, leaving one short edge and one long edge on each half-tile (excluding the join edge). We have shown a red dot at the vertex we regard as the origin of each half-tile (the tip of a half-dart and the base of a half-kite).
The labels are actually data constructors introduced with type operator HalfTile which has an argument type (rep) to allow for more than one representation of the half-tiles.
dataHalfTilerep=LDrep-- Left Dart|RDrep-- Right Dart|LKrep-- Left Kite|RKrep-- Right Kitederiving(Show,Eq)
Tgraphs
We introduce tile graphs (Tgraphs) which provide a simple planar graph representation for finite patches of tiles. For Tgraphs we first specialise HalfTile with a triple of vertices (positive integers) to make a TileFace such as RD(1,2,3), where the vertices go clockwise round the half-tile triangle starting with the origin.
typeTileFace=HalfTile(Vertex,Vertex,Vertex)typeVertex=Int-- must be positive
The function
makeTgraph::[TileFace]->Tgraph
then constructs a Tgraph from a TileFace list after checking the TileFaces satisfy certain properties (described below). We also have
faces::Tgraph->[TileFace]
to retrieve the TileFace list from a Tgraph.
As an example, the fool (short for fool’s kite and also called an ace in the literature) consists of two kites and a dart (= 4 half-kites and 2 half-darts):
fool::Tgraphfool=makeTgraph[RD(1,2,3),LD(1,3,4)-- right and left dart,LK(5,3,2),RK(5,2,7)-- left and right kite,RK(5,4,3),LK(5,6,4)-- right and left kite]
To produce a diagram, we simply draw the Tgraph
foolFigure::DiagramBfoolFigure=drawfool
which will produce the diagram on the left in figure 4.
Alternatively,
foolFigure::DiagramBfoolFigure=labelleddrawjfool
will produce the diagram on the right in figure 4 (showing vertex labels and dashed join edges).
Figure 4: Diagram of fool without labels and join edges (left), and with (right)
When any (non-empty) Tgraph is drawn, a default orientation and scale are chosen based on the lowest numbered join edge. This is aligned on the positive x-axis with length 1 (for darts) or length (for kites).
Tgraph Properties
Tgraphs are actually implemented as
newtypeTgraph=Tgraph[TileFace]deriving(Show)
but the data constructor Tgraph is not exported to avoid accidentally by-passing checks for the required properties. The properties checked by makeTgraph ensure the Tgraph represents a legal tiling as a planar graph with positive vertex numbers, and that the collection of half-tile faces are both connected and have no crossing boundaries (see note below). Finally, there is a check to ensure two or more distinct vertex numbers are not used to represent the same vertex of the graph (a touching vertex check). An error is raised if there is a problem.
Note: If the TileFaces are faces of a planar graph there will also be exterior (untiled) regions, and in graph theory these would also be called faces of the graph. To avoid confusion, we will refer to these only as exterior regions, and unless otherwise stated, face will mean a TileFace. We can then define the boundary of a list of TileFaces as the edges of the exterior regions. There is a crossing boundary if the boundary crosses itself at a vertex. We exclude crossing boundaries from Tgraphs because they prevent us from calculating relative positions of tiles locally and create touching vertex problems.
For convenience, in addition to makeTgraph, we also have
The first of these (performing no checks) is useful when you know the required properties hold. The second performs the same checks as makeTgraph except that it omits the touching vertex check. This could be used, for example, when making a Tgraph from a sub-collection of TileFaces of another Tgraph.
Main Tiling Operations
There are three key operations on finite tilings, namely
Decomposition (also called deflation) works by splitting each half-tile into either 2 or 3 new (smaller scale) half-tiles, to produce a new tiling. The fact that this is possible, is used to establish the existence of infinite aperiodic tilings with kites and darts. Since our Tgraphs have abstracted away from scale, the result of decomposing a Tgraph is just another Tgraph. However if we wish to compare before and after with a drawing, the latter should be scaled by a factor times the scale of the former, to reflect the change in scale.
Figure 5: fool (left) and decompose fool (right)
We can, of course, iterate decompose to produce an infinite list of finer and finer decompositions of a Tgraph
Force works by adding any TileFaces on the boundary edges of a Tgraph which are forced. That is, where there is only one legal choice of TileFace addition consistent with the seven possible vertex types. Such additions are continued until either (i) there are no more forced cases, in which case a final (forced) Tgraph is returned, or (ii) the process finds the tiling is stuck, in which case an error is raised indicating an incorrect tiling. [In the latter case, the argument to force must have been an incorrect tiling, because the forced additions cannot produce an incorrect tiling starting from a correct tiling.]
An example is shown in figure 6. When forced, the Tgraph on the left produces the result on the right. The original is highlighted in red in the result to show what has been added.
Figure 6: A Tgraph (left) and its forced result (right) with the original shown red
Compose
Composition (also called inflation) is an opposite to decompose but this has complications for finite tilings, so it is not simply an inverse. (See Graphs,Kites and Darts and Theorems for more discussion of the problems). Figure 7 shows a Tgraph (left) with the result of composing (right) where we have also shown (in pale green) the faces of the original that are not included in the composition – the remainder faces.
Figure 7: A Tgraph (left) and its (part) composed result (right) with the remainder faces shown pale green
Under some circumstances composing can fail to produce a Tgraph because there are crossing boundaries in the resulting TileFaces. However, we have established that
If g is a forced Tgraph, then compose g is defined and it is also a forced Tgraph.
Try Results
It is convenient to use types of the form Try a for results where we know there can be a failure. For example, compose can fail if the result does not pass the connected and no crossing boundary check, and force can fail if its argument is an incorrect Tgraph. In situations when you would like to continue some computation rather than raise an error when there is a failure, use a try version of a function.
We define Try as a synonym for Either ShowS (which is a monad) in module Tgraph.Try.
type Try a = Either ShowS a
(Note ShowS is String -> String). Successful results have the form Right r (for some correct result r) and failure results have the form Left (s<>) (where s is a String describing the problem as a failure report).
The function
runTry::Trya->arunTry=eithererrorid
will retrieve a correct result but raise an error for failure cases. This means we can always derive an error raising version from a try version of a function by composing with runTry.
force=runTry.tryForcecompose=runTry.tryCompose
Elementary Tgraph and TileFace Operations
The module Tgraph.Prelude defines elementary operations on Tgraphs relating vertices, directed edges, and faces. We describe a few of them here.
When we need to refer to particular vertices of a TileFace we use
originV::TileFace->Vertex-- the first vertex - red dot in figure 2oppV::TileFace->Vertex-- the vertex at the opposite end of the join edge from the originwingV::TileFace->Vertex-- the vertex not on the join edge
A directed edge is represented as a pair of vertices.
typeDedge=(Vertex,Vertex)
So (a,b) is regarded as a directed edge from a to b.
When we need to refer to particular edges of a TileFace we use
joinE::TileFace->Dedge-- shown dotted in figure 2shortE::TileFace->Dedge-- the non-join short edgelongE::TileFace->Dedge-- the non-join long edge
which are all directed clockwise round the TileFace. In contrast, joinOfTile is always directed away from the origin vertex, so is not clockwise for right darts or for left kites:
In the special case that a list of directed edges is symmetrically closed [(b,a) is in the list whenever (a,b) is in the list] we can think of this as an edge list rather than just a directed edge list.
For example,
internalEdges::Tgraph->[Dedge]
produces an edge list, whereas
boundary::Tgraph->[Dedge]
produces single directions. Each directed edge in the resulting boundary will have a TileFace on the left and an exterior region on the right. The function
dedges::Tgraph->[Dedge]
produces all the directed edges obtained by going clockwise round each TileFace so not every edge in the list has an inverse in the list.
Note 1: There is now a class HasFaces (introduced in version 1.4) which includes instances for both Tgraph and [TileFace] and others. This allows some generalisations. For example
Note 2: There is now a class HasGraph (introduced in version 1.8) which includes instances for Tgraph as well as other types used in forcing. This allows some other generalisations. For example
Behind the scenes, when a Tgraph is drawn, each TileFace is converted to a Piece. A Piece is another specialisation of HalfTile. Since version 1.10 this uses two two-dimensional vectors to represent the drawn edges of the half-tile starting from the origin, fixing its scale and orientation. The whole Tgraph then becomes a list of located Pieces called a Patch.
Piece drawing functions can use the drawnEdges (two vectors) and the joinVector (which is just the sum of the drawn edge vectors). In particular (in the TileLib module) we have
where the first draws the drawnEdges (the non-join edges) of a Piece, the second does the same but adds a faint dashed line for the join edge, and the third takes two colours – one for darts and one for kites, which are used to fill the piece as well as using drawPiece.
Patch is an instance of class Transformable so a Patch can be scaled, rotated, and translated for example.
Vertex Patches
It is useful to have an intermediate form between Tgraphs and Patches, that contains information about both the location of vertices (as 2D points), and the abstract TileFaces. This allows us to introduce labelled drawing functions (to show the vertex labels) which we then extend to Tgraphs. We call the intermediate form a VPatch (short for Vertex Patch).
calculates vertex locations using a default orientation and scale.
VPatch is made an instance of class Transformable so a VPatch can also be scaled, translated, and rotated for example.
One essential use of this intermediate form is to be able to draw a Tgraph with labels, transformed but without the labels themselves being transformed. We can simply convert the Tgraph to a VPatch, and transform that before drawing with labels.
labelleddraw(rotatesomeAngle(makeVPg))
We can also align a VPatch using vertex labels.
alignXaxis::(Vertex,Vertex)->VPatch->VPatch
So if g is a Tgraph with vertex labels a and b we can align it on the x-axis with a at the origin and b on the positive x-axis (after converting to a VPatch), instead of accepting the default orientation.
labelleddraw(alignXaxis(a,b)(makeVPg))
Another use of VPatches is to share the vertex location map when drawing only subsets of the faces (see Overlaid examples in the next section).
4. Drawing in More Detail
Class Drawable
There is a class Drawable with instances Tgraph, VPatch, Patch. When the token B is in scope standing for a fixed backend then we can assume
draw::Drawablea=>a->DiagramB-- draws non-join edgesdrawj::Drawablea=>a->DiagramB-- as with draw but also draws dashed join edgesfillDK::Drawablea=>ColourDouble->ColourDouble->a->DiagramB-- fills with colours
where fillDK clr1 clr2 will fill darts with colour clr1 and kites with colour clr2 as well as drawing non-join edges.
These are the main drawing tools. However they are actually defined for any suitable backend b so have more general types.
(Update Sept 2024) From version 1.1 onwards of PenroseKiteDart, these are
Class DrawableLabelled is defined with instances Tgraph and VPatch, but Patch is not an instance (because this does not retain vertex label information).
So labelColourSize c m modifies a Patch drawing function to add labels (of colour c and size measure m). Measure is defined in Diagrams.Prelude with pre-defined measures tiny, verySmall, small, normal, large, veryLarge, huge. For most of our diagrams of Tgraphs, we use red labels and we also find small is a good default size choice, so we define
and then labelled draw, labelled drawj, labelled (fillDK clr1 clr2) can all be used on both Tgraphs and VPatches as well as (for example) labelSize tiny draw, or labelCoulourSize blue normal drawj.
Further drawing functions
There are a few extra drawing functions built on top of the above ones. The function smart is a modifier to add dashed join edges only when they occur on the boundary of a Tgraph
smart::HasGrapha=>(VPatch->DiagramB)->a->DiagramB
So smart vpdraw g will draw dashed join edges on the boundary of g before applying the drawing function vpdraw to the VPatch for g. For example the following all draw dashed join edges only on the boundary for a Tgraph g
Here, smartOn g vpdraw vp uses the given vp for drawing boundary joins and drawing faces of g (with vpdraw) rather than converting g to a new VPatch. This assumes vp has locations for vertices in g.
Overlaid examples (location map sharing)
The function
drawForce::Tgraph->DiagramB
will (smart) draw a Tgraph g in red overlaid (using <>) on the result of force g as in figure 6. Similarly
drawPCompose::Tgraph->DiagramB
applied to a Tgraph g will draw the result of a partial composition of g as in figure 7. That is a drawing of compose g but overlaid with a drawing of the remainder faces of g shown in pale green.
Both these functions make use of sharing a vertex location map to get correct alignments of overlaid diagrams. In the case of drawForce g, we know that a VPatch for force g will contain all the vertex locations for g since force only adds to a Tgraph (when it succeeds). So when constructing the diagram for g we can use the VPatch created for force g instead of starting afresh. Similarly for drawPCompose g the VPatch for g contains locations for all the vertices of compose g so compose g is drawn using the VPatch for g instead of starting afresh.
The location map sharing is done with
subFaces::HasFacesa=>a->VPatch->VPatch
so that subFaces fcs vp is a VPatch with the same vertex locations as vp, but replacing the faces of vp with fcs. [Of course, this can go wrong if the new faces have vertices not in the domain of the vertex location map so this needs to be used with care. Any errors would only be discovered when a diagram is created.]
For cases where labels are only going to be drawn for certain faces, we need a version of subFaces which also gets rid of vertex locations that are not relevant to the faces. For this situation we have
restrictTo::HasFacesa=>a->VPatch->VPatch
which filters out un-needed vertex locations from the vertex location map. Unlike subFaces, restrictTo checks for missing vertex locations, so restrictTo fcs vp raises an error if a vertex in fcs is missing from the keys of the vertex location map of vp.
5. Forcing in More Detail
The force rules
The rules used by our force algorithm are local and derived from the fact that there are seven possible (internal) vertex types as depicted in figure 8.
Figure 8: Seven vertex types
Our rules are shown in figure 9 (omitting mirror symmetric versions). In each case the TileFace shown yellow needs to be added in the presence of the other TileFaces shown.
Figure 9: Rules for forcing
Main Forcing Operations
To make forcing efficient we convert a Tgraph to a BoundaryState to keep track of boundary information of the Tgraph, and then calculate a ForceState which combines the BoundaryState with a record of awaiting boundary edge updates (an update map), and an UpdateGenerator. Then each face addition is carried out on a ForceState, converting back when all the face additions are complete. It makes sense to apply force (and related functions) to a Tgraph, a BoundaryState, or a ForceState, so we define a class Forcible with instances Tgraph, BoundaryState, and ForceState.
The first will raise an error if a stuck tiling is encountered. The second uses a Try result which produces a Left report for failures and a Right a for successful result a.
There are several other operations related to forcing including
The first two force (up to) a given number of steps (=face additions) and the other four add a half dart/kite on a given boundary edge.
Update Generators
An update generator is used to calculate which boundary edges can have a certain update. There is an update generator for each force rule, but also a combined (all update) generator. The force operations mentioned above all use the default all update generator (defaultAllUGen) but there are more general (with) versions that can be passed an update generator of choice. For example
where wholeTileUpdates is an update generator that just finds boundary join edges to complete whole tiles.
In fact UpdateGenerators are functions that take a BoundaryState and a focus (list of boundary directed edges) to produce an update map. Each Update is calculated as either a SafeUpdate (where two of the new face edges are on the existing boundary and no new vertex is needed) or an UnsafeUpdate (where only one edge of the new face is on the boundary and a new vertex needs to be created for a new face).
Completing (executing) an UnsafeUpdate requires a touching vertex check to ensure that the new vertex does not clash with an existing boundary vertex. Using an existing (touching) vertex would create a crossing boundary so such an update has to be blocked.
Forcible Class Operations
The Forcible class operations are higher order and designed to allow for easy additions of further generic operations. They take care of conversions between Tgraphs, BoundaryStates and ForceStates. The first two are designed to create functions that return the same Forcible type as the input.
For example, given any f:: ForceState -> Try ForceState , then f can be generalised to work on any Forcible using tryFSOp f. This is used to define both tryForce and tryStepForce.
Similarly given any f:: BoundaryState -> Try BoundaryChange , then f can be generalised to work on any Forcible using tryChangeBoundary f. This is used to define tryAddHalfDart and tryAddHalfKite.
Note that the type BoundaryChange contains a resulting BoundaryState, the single TileFace that has been added, a list of edges removed from the boundary (of the BoundaryState prior to the face addition), and a list of the (3 or 4) boundary edges affected around the change that require checking or re-checking for updates.
The class function tryInitFS will create an initial ForceState for any Forcible. If the Forcible is already a ForceState it will do nothing. Otherwise it will calculate updates for the whole boundary using defaultAllUGen.
The update generator is assumed to be defaultAllUGen but this can be changed using
Note that (force . force) does the same as force, but we might want to chain other force related steps in a calculation.
For example, consider the following combination which, after decomposing a Tgraph, forces, then adds a half dart on a given boundary edge (d) and then forces again.
Since decompose produces a Tgraph, the instances of force and addHalfDart d will have type Tgraph -> Tgraph so each of these operations, will begin and end with conversions between Tgraph and ForceState. We would do better to avoid these wasted intermediate conversions working only with ForceStates and keeping only those necessary conversions at the beginning and end of the whole sequence.
This can be done using tryFSOp. To see this, let us first re-express the forcing sequence using the Try monad, so
force.addHalfDartd.force
becomes
tryForce<=<tryAddHalfDartd<=<tryForce
Note that (<=<) is the Kliesli arrow which replaces composition for Monads (defined in Control.Monad). (We could also have expressed this right to left sequence with a left to right version tryForce >=> tryAddHalfDart d >=> tryForce). The definition of combo becomes
The sequence actually has type Forcible a => a -> Try a but when passed to tryFSOp it specialises to type ForceState -> Try ForseState. This ensures the sequence works on a ForceState and any conversions are confined to the beginning and end of the sequence, avoiding unnecessary intermediate conversions.
A limitation of forcing
To avoid creating touching vertices (or crossing boundaries) a BoundaryState keeps track of locations of boundary vertices. At around 35,000 face additions in a single force operation the calculated positions of boundary vertices can become too inaccurate to prevent touching vertex problems. In such cases it is better to use
These work by recalculating all vertex positions at 20,000 step intervals to get more accurate boundary vertex positions. For example, 6 decompositions of the kingGraph has 2,906 faces. Applying force to this should result in 53,574 faces but will go wrong before it reaches that. This can be fixed by calculating either
recalibratingForce(decompositionskingGraph!!6)
or using an extra force before the decompositions
force(decompositions(forcekingGraph)!!6)
In the latter case, the final force only needs to add 17,864 faces to the 35,710 produced by decompositions (force kingGraph) !!6.
6. Advanced Operations
Guided comparison of Tgraphs
Asking if two Tgraphs are equivalent (the same apart from choice of vertex numbers) is a an np-hard problem. However, we do have an efficient guided way of comparing Tgraphs. In the module Tgraph.Rellabelling we have
sameGraph::(Tgraph,Dedge)->(Tgraph,Dedge)->Bool
The expression sameGraph (g1,d1) (g2,d2) asks if g2 can be relabelled to match g1 assuming that the directed edge d2 in g2 is identified with d1 in g1. Hence the comparison is guided by the assumption that d2 corresponds to d1.
where tryRelabelToMatch (g1,d1) (g2,d2) will either fail with a Left report if a mismatch is found when relabelling g2 to match g1 or will succeed with Right g3 where g3 is a relabelled version of g2. The successful result g3 will match g1 in a maximal tile-connected collection of faces containing the face with edge d1 and have vertices disjoint from those of g1 elsewhere. The comparison tries to grow a suitable relabelling by comparing faces one at a time starting from the face with edge d1 in g1 and the face with edge d2 in g2. (This relies on the fact that Tgraphs are connected with no crossing boundaries, and hence tile-connected.)
which tries to find the union of two Tgraphs guided by a directed edge identification. However, there is an extra complexity arising from the fact that Tgraphs might overlap in more than one tile-connected region. After calculating one overlapping region, the full union uses some geometry (calculating vertex locations) to detect further overlaps.
which will find common regions of overlapping faces of two Tgraphs guided by a directed edge identification. The resulting common faces will be a sub-collection of faces from the first Tgraph. These are returned as a list as they may not be a connected collection of faces and therefore not necessarily a Tgraph.
Empires and SuperForce
In Empires and SuperForce we discussed forced boundary coverings which were used to implement both a superForce operation
superForce::Forciblea=>a->Forceda
and operations to calculate empires.
We will not repeat the descriptions here other than to note that
forcedBoundaryECovering::Tgraph->[ForcedTgraph]
finds boundary edge coverings after forcing a Tgraph. That is, forcedBoundaryECovering g will first force g, then (if it succeeds) finds a collection of (forced) extensions to force g such that
each extension has the whole boundary of force g as internal edges.
each possible addition to a boundary edge of force g (kite or dart) has been included in the collection.
(possible here means – not leading to a stuck Tgraph when forced.) There is also
forcedBoundaryVCovering::Tgraph->[ForcedTgraph]
which does the same except that the extensions have all boundary vertices internal rather than just the boundary edges. In both cases the result is a list of explicitly forced Tgraphs (discussed next).
Combinations and Explicitly Forced
We introduced a new type Forced (in v 1.3) to enable a forcible to be explictily labelled as being forced. For example
This allows us to restrict certain functions which expect a forced argument by making this explicit.
composeF::HasGrapha=>Forceda->ForcedTgraph
The definition makes use of theorems established in Graphs,Kites and Darts and Theorems that composing a forced Tgraph does not require a check (for connectedness and no crossing boundaries) and the result is also forced. This can then be used to define efficient combinations such as
compForce::(Forciblea,HasGrapha)=>a->ForcedTgraph-- compose after forcingcompForce=composeF.forceFallCompForce::(Forciblea,HasGrapha)=>a->[ForcedTgraph]-- iterated (compose after force) while not emptyTgraphmaxCompForce::(Forciblea,HasGrapha)=>a->ForcedTgraph-- last item in allCompForce (or emptyTgraph)
Note that BoundaryState, ForceState as well as Tgraph and Forced versions of these are all instances of class HasGraph.
has proven useful in experimentation as well as in producing artwork with darts and kites. The idea is to keep a record of sub-collections of faces of a Tgraph when doing both force operations and decompositions. A list of the sub-collections forms the tracked list associated with the Tgraph. We make TrackedTgraph an instance of class Forcible by having force operations only affect the Tgraph and not the tracked list. The significant idea is the implementation of
decomposeTracked::TrackedTgraph->TrackedTgraph
Decomposition of a Tgraph involves introducing a new vertex for each long edge and each kite join. These are then used to construct the decomposed faces. For decomposeTracked we do the same for the Tgraph, but when it comes to the tracked collections, we decompose them re-using the same new vertex numbers calculated for the edges in the Tgraph. This keeps a consistent numbering between the Tgraph and tracked faces, so each item in the tracked list remains a sub-collection of faces in the Tgraph.
is used to draw a TrackedTgraph. It uses a list of functions to draw VPatches. The first drawing function is applied to a VPatch for any untracked faces. Subsequent functions are applied to VPatches for the tracked list in order. Each diagram is beneath later ones in the list, with the diagram for the untracked faces at the bottom. The VPatches used are all restrictions of a single VPatch for the Tgraph, so will be consistent in vertex locations. When labels are used, there is also a drawTrackedTgraphRotating and drawTrackedTgraphAligning for rotating or aligning the VPatch prior to applying the drawing functions.
Note that the result of calculating empires (see Empires and SuperForce ) is represented as a TrackedTgraph. The result is actually the common faces of a forced boundary covering, but a particular element of the covering (the first one) is chosen as the background Tgraph with the common faces as a tracked sub-collection of faces. Hence we have
Diagrams for Penrose Tiles – the first blog introduced drawing Pieces and Patches (without using Tgraphs) and provided a version of decomposing for Patches (decompPatch).
Graphs, Kites and Darts intoduced Tgraphs. This gave more details of implementation and results of early explorations. (The class Forcible was introduced subsequently).
Empires and SuperForce – these new operations were based on observing properties of boundaries of forced Tgraphs.
tl;dr: This is a fully commentated, from-scratch proof of the
Fundamental Theorem of Arithmetic in
Agda,
intended for those who already know a bit of Agda but might benefit
from reading and working through a larger example. See the
Introduction and the Table of Contents below for more details.
So I decided to spend about an hour trying to prove it in Agda,
to gauge the level of the project. At the end of an hour, I had
learned two things: (1) proving the Fundamental Theorem of Arithmetic is not an appropriate project for
my students (who had only had a few weeks’ practice with Agda); (2) I
was not going to be able to stop until I finished the proof myself!
Over the next week or so, I finished the proof completely from
scratch—without using anything from the standard library, and without
looking up any reference material. I based it only on my experience
in Agda, knowledge of the relevant proofs on an informal level, and
Agda techniques I’ve picked up along the way (from e.g. Conor McBride, Jacques
Carette, colleagues at Penn, and elsewhere).
I decided to publish the proof, with extra commentary, in the hopes
that it can be useful as an intermediate-level reference. That is,
perhaps you’ve learned some basic Agda (if not, I suggest this
tutorial to
start)
and have some basic familiarity
with the Curry-Howard correspondence, but would benefit from seeing an
example of a fully worked out, medium-sized proof.Another good
source of information along these lines is this post by Jesper
Cockx.
The resulting blog
post is extremely long, but I make no apologies for that—if you want
an entertaining 5-minute read, you should look elsewhere!
Below is a table of contents. Depending on your background, you may
of course choose to skip some sections. For example, if you have
already had a good deal of practice dealing with basic natural number
arithmetic, equality, and inequality in Agda, you might wish to skip
over those sections.
(Half of) The Fundamental Theorem of Arithmetic (Constructively)
The Fundamental Theorem of
Arithmetic
(FTA for short) states that any natural number \(n \geq 1\) can be
written as a product of zero or more primes, and moreover that this
product is unique up to permutation.
For now, we are only going to prove the existence part (I may write
another blog post with the uniqueness proof later). Since a constructive
existence proof is really an algorithm for constructing the thing that
is claimed to exist, this can also be seen as a formally verified
factorization program: put any number in, get a prime factorization
out. Writing a prime factorization program is not hard, of course;
it’s the formal verification part that is interesting!
Stop! Before reading on, if you want to get the most out of this tutorial, I
strongly recommend downloading the version with
holes
and trying to complete as many of the proofs as you can before reading mine!
Preliminaries
We will often make use of A and B to stand for arbitrary
sets/types, so we use a variable declaration to tell Agda that it
should implicitly quantify them whenever they show up as free
variables. That way we don’t have to write {A B : Set} → ... all the time.
variable A B :Set
Basic logic
Since we’re building this completely from scratch, we start with some
types to represent basic logical building blocks (via the
Curry-Howard correspondence). First, the “top” type ⊤ to stand for truth, i.e. a proposition with trivial evidence:
data ⊤ :Setwhere tt : ⊤
tt is declared to be the one and only value of type ⊤.
Note that some things we define here—such as ⊤—will have the same
names as they do in the Agda standard library. However, many things
won’t, since I either didn’t know the standard name and made up my
own, or (in a few cases) did know the standard name but didn’t like
it, and made up my own anyway.
Next, the “bottom” type ⊥ with no constructors, representing
falsity, along with a corresponding elimination principle, absurd. The elimination
principle says that anything follows from ⊥ (“ex falso
quodlibet”), and is implemented using Agda’s absurd pattern,
written (). If Agda can tell that there are no possible
constructors which could give rise to a value of a certain type, we
can pattern-match on it with (), and are absolved of providing a right-hand side for the definition in that case.
data ⊥ :Setwhereabsurd : ⊥ → Aabsurd ()
We can now define negation as an implication to ⊥.
¬ :Set→Set¬ P = P → ⊥
Dependent pairs are next: a pair of values where the type of the
second component can depend on the value of the first. That is, a value of type Σ A B is a value a of type
A paired with a value of type B a. Via Curry-Howard, this is used
to represent existential quantification: a (constructive) proof of
\(\exists a : A.\; B(a)\) is a value \(a\) of type \(A\) (the witness)
paired with a proof that \(a\) has property \(B\) (i.e. a value of type \(B(a)\)).
infixr1_,_data Σ (A :Set)(B : A →Set):Setwhere_,_:(a : A)→ B a → Σ A B
We also define a projection function (we only end up needing fst;
defining snd is left as an exercise for the readerThe definition
of snd is trivial; writing down its type is a worthwhile
exercise.
), along with a type of non-dependent pairs, corresponding
to logical conjunction (and).
fst :∀{A B}→ Σ A B → Afst (a , _)= ainfixr3_×__×_:(A B :Set)→SetA × B = Σ A (λ_→ B)
Finally, we define a disjoint (tagged) union type corresponding to
logical disjunction (or).
infixr2_⊎_data_⊎_(A B :Set):Setwhere inj₁ : A → A ⊎ B inj₂ : B → A ⊎ B
Equality
Next, we write down the standard equality (aka identity, aka path) type, with a single
constructor refl that witnesses when its two arguments are
identical.It still seems somewhat magical to me that this seemingly
too-simple definition encapsulates everything we want in an equality
relation (well, almost everything).
We also define a convenient
synonym for inequality.
infix4_≡_data_≡_(a : A): A →Setwhere refl : a ≡ a_≢_: A → A →Setx ≢ y = ¬ (x ≡ y)
Besides reflexivity, equality enjoys various properties that we will
need: symmetry, transitivity, and congruence (i.e., we can apply any
function to both sides of an equation).
sym :{x y : A}→ x ≡ y → y ≡ xsym refl = refltrans :{x y z : A}→ x ≡ y → y ≡ z → x ≡ ztrans refl y≡z = y≡zcong :(f : A → B)→{x y : A}→ x ≡ y → f x ≡ f ycong _ refl = refl
Since we will spend a good amount of time reasoning about equality, it
is worthwhile building up some machinery for writing more readable
equality proofs. Instead of writing, say,
trans p (trans q (trans (sym r) s))
we will be able to instead write equality proofs like so:
begin
v ≡[ p ⟩≡
w ≡[ q ⟩≡
x ≡⟨ r ]≡
y ≡[ s ⟩≡
z ∎
The intention is that this proof shows v ≡ z, by first using p to
show that v ≡ w, then q to show w ≡ x, and so on. This notation
is one of my favorite applications of Agda’s mixfix operator
syntax,
and has several benefits:
We can avoid nested parentheses when chaining uses of transitivity.
We can automatically apply symmetry by using a left-pointing
instead of right-pointing operator.
We get to explicitly mention (and have Agda check for us) all the
intermediate values, making it easier to write the proof
incrementally, and much easier for humans to read.
This is one of the places where I deliberately chose different
operator names than the standard library, which uses _≡⟨_⟩_ and
_≡⟨_⟨_. The operator names I decided to use are inspired by Conor
McBride. I just like the way they look better.
infix1 begin_begin_:{x y : A}→ x ≡ y → x ≡ ybegin x≡y = x≡yinfixr2_≡[_⟩≡__≡[_⟩≡_:(x : A)→{y z : A}→(x ≡ y)→(y ≡ z)→(x ≡ z)_ ≡[ x≡y ⟩≡ y≡z = trans x≡y y≡zinfixr2_≡⟨_]≡__≡⟨_]≡_:(x : A)→{y z : A}→(y ≡ x)→(y ≡ z)→(x ≡ z)_ ≡⟨ y≡x ]≡ y≡z = trans (sym y≡x) y≡zinfixr5_∎_∎ :(x : A)→ x ≡ x_ ∎ = refl
Finally, a few Applicative-like operators for more conveniently
writing common forms of congruence. For example, instead of writing
cong f x≡y, we can write f $≡ x≡y; or to use congruence on both
arguments of a two-place function at once, we can write f $≡ x≡y ≡$≡ z≡w. (These operators were also inspired by Conor.)
infixl4_$≡__$≡_:(f : A → B)→{x y : A}→ x ≡ y → f x ≡ f yf $≡ x≡y = cong f x≡yinfixl4_≡$__≡$_:{f g : A → B}→ f ≡ g →(x : A)→ f x ≡ g xf≡g ≡$ x = cong (λ h → h x) f≡ginfixl4_≡$≡__≡$≡_:{f g : A → B}→ f ≡ g →{x y : A}→ x ≡ y → f x ≡ g yf≡g ≡$≡ x≡y = trans (f≡g ≡$ _)(_ $≡ x≡y)
Natural numbers
Of course, we will need a type to represent the natural numbers. We
can also tell Agda that our natural number type should correspond to its
built-in notion of natural numbers, so we can use numeric literals
like 2 : ℕ instead of having to write suc (suc zero).
data ℕ :Setwhere zero : ℕ suc : ℕ → ℕ{-# BUILTIN NATURAL ℕ #-}
No confusion
For our natural number type—and often, for any algebraic data type—we
need to know that the constructors are
disjoint, meaning that different constructors always generate
different values (so it’s a contradiction to have an equality
between values built with different constructors); and
injective, meaning that if we have an equality between values built
with the same constructor, we can decompose it into equalities between
the components.
We can prove both of these simultaneously using a property called “no
confusion”. This property and its name is well-known in the
literature; for example, see
McBridge or Cornes +
Terrasse.
For natural numbers m and n, the type NoConf m n should be
thought of as the type of evidence that m ≡ n, based on looking at
the top-level constructors of m and n. If m and n have different
constructors, then no evidence can possibly show that they are equal,
so NoConf m n = ⊥ in that case. If m and n are both zero, then
they are evidently equal, so NoConf 0 0 = ⊤. Otherwise, if m and
n are both successors, NoConf m n reduces to a proof of equality
between their predecessors.
NoConf : ℕ → ℕ →SetNoConf zero zero = ⊤NoConf zero (suc n)= ⊥NoConf (suc m) zero = ⊥NoConf (suc m)(suc n)= m ≡ n
Now we can prove the no confusion lemma for our natural number type,
which says that NoConf m n always holds whenever m ≡ n.
Since m ≡ n, we only have to deal with the cases when m and n
are both zero or both a successor—but this also justifies assigning a
type of ⊥ to the cases when the constructors do not match. noConf
can therefore be used to strip suc from both sides of an equation,
or to derive a contradiction when we have an equation between
non-matching constructors.
noConf :{m n : ℕ}→ m ≡ n → NoConf m nnoConf {zero} refl = ttnoConf {suc m} refl = refl
As an aside, this definition of the no confusion property uses a
technique I like: defining a type starting with a capital letter,
then defining a term that returns that type starting with a
lowercase letter. This pattern will come up again later. Sometimes
we define named types in this way just for convenience, say, to be
able to refer to the type multiple times in a concise way; or, as in
the above case, sometimes the type is actually defined via some
nontrivial computation.
Decidable equality
We can now show how to decide equality of natural numbers. We first
define a simple type representing decidability in general: Dec P represents
either a proof of P, or a proof of ¬ P.You may be aware that the
law of excluded middle, which
says that \(P \lor \neg P\) for all propositions \(P\), is rejected in constructive logic. However, even
though \(P \lor \neg P\) does not hold for all\(P\), it can still hold
for certain specific propositions. Propositions \(P\) for which \(P \lor
\neg P\) holds constructively are called decidable.
data Dec (P :Set):Setwhere yes : P → Dec P no : ¬ P → Dec P
We can then prove that for any natural numbers x and y, we can decide
whether x ≡ y. Notice the several different uses of the no
confusion lemma: two to handle impossible situations, and one to strip
suc off both sides of an equality.
_≟_:(x y : ℕ)→ Dec (x ≡ y)zero ≟ zero = yes reflzero ≟ suc y = no noConfsuc x ≟ zero = no noConfsuc x ≟ suc y with x ≟ y...| yes x≡y = yes (suc $≡ x≡y)...| no x≢y = no (λ sx≡sy → x≢y (noConf sx≡sy))
Addition
We next turn to defining addition (by pattern-matching on the
left-hand argument), along with several properties of
addition we will need: zero is a right identity for addition; we can
pull out a suc from the right-hand argument; and addition is
commutative, associative, and left-cancellable.
infixl6_+__+_: ℕ → ℕ → ℕzero + y = ysuc x + y = suc (x + y)_+0 :(n : ℕ)→(n + 0 ≡ n)zero +0 = refl(suc n) +0 = suc $≡ (n +0)_+suc_:(x y : ℕ)→(x + suc y) ≡ suc (x + y)zero +suc y = refl(suc x) +suc y = suc $≡ (x +suc y)+-comm :(x y : ℕ)→ x + y ≡ y + x+-comm zero y = sym (y +0)+-comm (suc x) y = trans (suc $≡ (+-comm x y))(sym (y +suc x))+-assoc :(x y z : ℕ)→(x + y) + z ≡ x + (y + z)+-assoc zero y z = refl+-assoc (suc x) y z = suc $≡ (+-assoc x y z)+-cancelˡ :(x y z : ℕ)→ x + y ≡ x + z → y ≡ z+-cancelˡ zero y z x+y≡x+z = x+y≡x+z+-cancelˡ (suc x) y z x+y≡x+z = +-cancelˡ x y z (noConf x+y≡x+z)
Multiplication
Multiplication is next: we start by defining the multiplication
operation (by pattern-matching on the left-hand argument) and proving
a few lemmas about multiplying by known arguments on the right. The
proof of *suc is the most involved proof we have seen yet, but it
ultimately just comes down to algebra, and we can make good use of our
notation for writing chained equality proofs.
infixl7_*__*_: ℕ → ℕ → ℕzero * y = zerosuc x * y = y + x * y_*0 :(n : ℕ)→(n * 0 ≡ 0)zero *0 = refl(suc n) *0 = n *0_*1 :(n : ℕ)→(n * 1 ≡ n)0 *1 = refl(suc n) *1 = suc $≡ (n *1)_*suc_:(x y : ℕ)→(x * suc y ≡ x + x * y)zero *suc y = refl(suc x) *suc y = suc $≡ ( begin y + x * suc y ≡[ (y +_) $≡ (x *suc y) ⟩≡ y + (x + x * y) ≡⟨ +-assoc y x (x * y) ]≡(y + x) + x * y ≡[ _+_ $≡ +-comm y x ≡$ x * y ⟩≡(x + y) + x * y ≡[ +-assoc x __ ⟩≡ x + (y + x * y) ∎)
We prove some standard properties of multiplication: commutativity,
distributivity over addition, associativity. Again, the proofs mostly
consist of a whole bunch of algebra, using the special notation for
building chained equality proofs.
*-comm :(x y : ℕ)→ x * y ≡ y * x*-comm zero y = sym (y *0)*-comm (suc x) y = begin y + x * y ≡[ y +_ $≡ *-comm x y ⟩≡ y + y * x ≡⟨ y *suc x ]≡ y * suc x ∎*-distribˡ :(x y z : ℕ)→ x * (y + z) ≡ x * y + x * z*-distribˡ zero y z = refl*-distribˡ (suc x) y z = begin y + z + x * (y + z) ≡[ (y + z) +_ $≡ *-distribˡ x y z ⟩≡ y + z + (x * y + x * z) ≡[ +-assoc y __ ⟩≡ y + (z + (x * y + x * z)) ≡⟨ y +_ $≡ +-assoc z __ ]≡ y + ((z + x * y) + x * z) ≡[ y +_ $≡ (_+_ $≡ +-comm z _ ≡$ x * z) ⟩≡ y + ((x * y + z) + x * z) ≡[ y +_ $≡ +-assoc (x * y)__ ⟩≡ y + (x * y + (z + x * z)) ≡⟨ +-assoc y __ ]≡ y + x * y + (z + x * z) ∎*-distribʳ :(x y z : ℕ)→(x + y) * z ≡ x * z + y * z*-distribʳ x y z = begin(x + y) * z ≡[ *-comm (x + y)_ ⟩≡ z * (x + y) ≡[ *-distribˡ z __ ⟩≡ z * x + z * y ≡[ _+_ $≡ *-comm z _ ≡$≡ *-comm z _ ⟩≡ x * z + y * z ∎*-assoc :(x y z : ℕ)→(x * y) * z ≡ x * (y * z)*-assoc zero y z = refl*-assoc (suc x) y z = begin(y + x * y) * z ≡[ *-distribʳ y __ ⟩≡ y * z + (x * y) * z ≡[ y * z +_ $≡ *-assoc x __ ⟩≡ y * z + x * (y * z) ∎
Finally, we prove that multiplication is left-cancellative. This
proof is somewhat tricky—in the case that x, y, and z are all
successors, we need to use the induction hypothesis (i.e. a
recursive call to *-cancelˡ) on x and the
predecessors of y and z, using the fact that + is
left-cancellative to construct the required input equality.
*-cancelˡ :(x y z : ℕ)→(0 ≢ x)→ x * y ≡ x * z → y ≡ z*-cancelˡ zero y z x≢0 xy≡xz = absurd (x≢0 refl)*-cancelˡ (suc x) zero zero x≢0 xy≡xz = refl*-cancelˡ (suc x) zero (suc z) x≢0 xy≡xz = absurd (noConf (trans (sym (x *0)) xy≡xz))*-cancelˡ (suc x)(suc y) zero x≢0 xy≡xz = absurd (noConf (trans xy≡xz (x *0)))*-cancelˡ (suc x)(suc y)(suc z) x≢0 xy≡xz = suc $≡( *-cancelˡ (suc x) y z x≢0( +-cancelˡ (suc x)(suc x * y)(suc x * z)( begin suc x + suc x * y ≡⟨ (suc x) *suc y ]≡ suc x * suc y ≡[ xy≡xz ⟩≡ suc x * suc z ≡[ (suc x) *suc z ⟩≡ suc x + suc x * z ∎)))
Inequality
Next, we give a standard definition of the “less than or equal to”
relation on natural numbers. Note that the structure of a proof of \(x \leq
y\) exactly matches the structure of \(x\) itself.
data_≤_: ℕ → ℕ →Setwhere zle :{n : ℕ}→ zero ≤ n sle :{m n : ℕ}→ m ≤ n → suc m ≤ suc n
We also prove some standard properties of \(\leq\): it is reflexive and
transitive, and is related to suc in various ways.
≤-refl :{m : ℕ}→ m ≤ m≤-refl {zero}= zle≤-refl {suc m}= sle ≤-refl≤-trans :{x y z : ℕ}→ x ≤ y → y ≤ z → x ≤ z≤-trans zle y≤z = zle≤-trans (sle x≤y)(sle y≤z)= sle (≤-trans x≤y y≤z)≤-sucr :{m n : ℕ}→ m ≤ n → m ≤ suc n≤-sucr zle = zle≤-sucr (sle m≤n)= sle (≤-sucr m≤n)≤-sucl :{m n : ℕ}→ suc m ≤ n → m ≤ n≤-sucl (sle sm≤n)= ≤-sucr sm≤n≤-pred :{x y : ℕ}→ suc x ≤ suc y → x ≤ y≤-pred (sle sx≤sy)= sx≤sy
For convenience, we define \(<\) in terms of \(\leq\), and prove a few
properties: any number is less than its successor, and \(<\) is
transitive and non-reflexive.
_<_: ℕ → ℕ →Setx < y = suc x ≤ y_<suc :(x : ℕ)→ x < suc x_<suc zero = sle zle_<suc (suc x)= sle (x <suc)<-trans :{x y z : ℕ}→ x < y → y < z → x < z<-trans (sle x<y)(sle y<z)= ≤-trans (sle x<y)(≤-sucr y<z)x≮x :{x : ℕ}→ ¬ (x < x)x≮x {zero}=λ()x≮x {suc x}=λ{(sle x<x)→ x≮x x<x}
Relationships among equality and inequality
Of course, equality, \(<\) and \(\leq\) have various relationships that we
will need. First, equality implies \(\leq\).
≡→≤ :{x y : ℕ}→ x ≡ y → x ≤ y≡→≤ refl = ≤-refl
Next, \(x < y\) implies that \(x\) and \(y\) are not related by \(\equiv\) or
\(\geq\). The first lemma in particular—that \(<\) implies \(\not\equiv\)—gets used quite a bit. Note that it can be read in two equivalent
ways: on the surface, it is a way to turn a proof of \(x < y\) into a
proof of \(x \not\equiv y\); but
since \(x \not\equiv y\) is really an abbreviation for \((x \equiv y) \to \bot\), it can be
used to derive a contradiction if we have proofs that \(x < y\) and
also \(x \equiv y\).
<→≢ :{x y : ℕ}→ x < y → x ≢ y<→≢ x<y refl = x≮x x<y<→≱ :{x y : ℕ}→ x < y → ¬ (y ≤ x)<→≱ (sle x<y)(sle y≤x)= <→≱ x<y y≤x
If \(x \leq y\) but they are not equal, then \(x < y\).
≤≢→< :{x y : ℕ}→ x ≤ y → x ≢ y → x < y≤≢→< {y = zero} zle x≢y = absurd (x≢y refl)≤≢→< {y = suc y} zle x≢y = sle zle≤≢→< (sle x≤y) x≢y = sle (≤≢→< x≤y (λ m≡n → x≢y (suc $≡ m≡n)))
We will need a form of transitivity that says if \(x \leq y\) and \(y <
z\), then \(x < z\), as well as the other way around.
≤-<-trans :{x y z : ℕ}→ x ≤ y → y < z → x < z≤-<-trans x≤y (sle y<z)= ≤-trans (sle x≤y)(sle y<z)<-≤-trans :{x y z : ℕ}→ x < y → y ≤ z → x < z<-≤-trans (sle x<y) y≤z = ≤-trans (sle x<y) y≤z
Finally, a very specific lemma we will need: if a number is not
equal to either 0 or 1, then it must be greater than or equal to 2.
The last lemmas we need relate arithmetic operations and inequality.
First, adding and multiplying cannot make anything smaller (unless we
multiply by zero, of course).
≤+ :{x y : ℕ}→ x ≤ (x + y)≤+ {zero}= zle≤+ {suc x}= sle ≤+≤* :{x y : ℕ}→(x ≢ 0)→ y ≤ (x * y)≤* {zero} x≢0 = absurd (x≢0 refl)≤* {suc x} x≢0 = ≤+
As a result, if we know that one thing is equal to a sum or product of
other things, we can conclude something about their relative sizes.
+→≤ :{x y z : ℕ}→ x + y ≡ z → x ≤ z+→≤ refl = ≤++→< :{x y z : ℕ}→0 < y → x + y ≡ z → x < z+→< {x}{suc y}_ x+y≡z = +→≤ (trans (sym (x +suc y)) x+y≡z)*→≤ :{x y z : ℕ}→(y ≢ 0)→ y * x ≡ z → x ≤ z*→≤ {x}{y} y≢0 refl = ≤* y≢0
Divisibility, primes, and composites
With the preliminaries out of the way, we can finally get on with the
meat of the problem—and we finally get to make use of a dependent pair! A constructive proof that a divides
b is a specific natural number witness k, along with a proof that k * a ≡ b.
_∣_: ℕ → ℕ →Seta ∣ b = Σ ℕ (λ k → k * a ≡ b)
Proofs of divisibility are unique—that is, for given \(a\) and \(b\) there
is at most one value of \(k\) such that \(ka = b\). We won’t need this,
but it follows easily from the fact that multiplication is
cancellative. More interesting is the fact that divisibility is
decidable—that is, for given numbers \(a\) and \(b\) we can calculate
either a proof that \(a \mid b\), or a proof that \(\neg (a \mid b)\).
This will play a starring role later on—to factor a number we need to
be able to try potential divisors and find out whether they work—but proving it is not easy!
It will take us several hundred more lines of Agda to get there.
In any case, using this notion of divisibility, we can now define prime and
composite numbers. A number \(n\) is defined to be prime if it is at
least two, and every \(2 \leq d < n\) does not divide \(n\).
Prime : ℕ →SetPrime n =(2 ≤ n) × (∀(d : ℕ)→(d < n)→(2 ≤ d)→ ¬ (d ∣ n))
One could equivalently define primality by saying that any divisor of
\(n\) must be equal to \(1\) or \(n\); I just decided I liked this
formulation better, especially because it directly matches up with the
way we will test a number for primality later.
A composite number is one that has a nontrivial divisor—that is, a number \(d\)
such that \(2 \leq d < n\) and \(d\) divides \(n\).Note
that we could easily prove that if \(n\) is prime then \(n\) is not
composite, and likewise if \(n\) is composite then it is not prime, but
we won’t end up needing these lemmas.
Composite : ℕ →SetComposite n = Σ ℕ (λ d →2 ≤ d × d < n × d ∣ n)
Unlike proofs of divisibility, proofs of Composite n are not
unique. For example, we could prove Composite 12 by showing that
\(2\) is a nontrivial divisor of \(12\), or by showing that \(3\) is.
Although this does not matter from a purely logical point of view, it
matters computationally; in general, we care which specific proof of
Composite n we have.
Nontrivial divisors come in pairs
Before moving on to other things, we will prove a lemma about
composite numbers. If \(n\) is composite, by definition it has a
nontrivial divisor \(a\); but this means it must also have a second
nontrivial divisor \(b\) such that \(ab = n\). This fact seems almost
trivial to us. Indeed, it’s easy to show that if \(n\) has a divisor
\(a\), then it must have another divisor \(b\) such that \(ab = n\). The
tricky part is showing that if \(a\) is a nontrivial divisor, then \(b\)
is also nontrivial. The proof relies on much of the infrastructure
we have built up about natural numbers, multiplication, and
inequality.
First, we define a type representing two factors of a number \(n\): a
pair of proofs that \(n\) is composite (i.e. two nontrivial divisors
of \(n\)), along with a proof that the product of those divisors is \(n\).
Now, we prove that if \(n\) is composite, then it has two nontrivial
factors. We begin by pattern-matching on the proof that \(n\) is
composite, which consists of a divisor \(a\), evidence that \(a\) is
nontrivial (i.e.\(2 \leq a\) and \(a < n\)), and a proof that \(a\) is a
divisor of \(n\), which itself consists of a number \(b\) paired with a
proof that \(ba = n\).
factorsOf :(n : ℕ)→ Composite n → FactorsOf nfactorsOf n (a , 2≤a , a<n , b , ba≡n)=
To construct the proof of FactorsOf n, we need two proofs of
Composite n along with a proof that the product of the two divisors
is \(n\). We already have a proof that \(ba = n\), so we use that, with
\(a\) as the second divisor (replicating the corresponding proof of
Composite n), and \(b\) as the first. Proving that \(b\) is a divisor of
\(n\) is easy: \(a\) is the witness, and proving that \(ab = n\) is easy
since we already know \(ba = n\) and multiplication is commutative. The
only thing left is to prove that \(b\) is nontrivial, i.e. that \(2
\leq b\) and \(b < n\).
((b , 2≤b , b<n , a , trans (*-comm a b) ba≡n) , (a , 2≤a , a<n , b , ba≡n)) , ba≡n
First, we need a lemma that \(0 < n\), which follows because \(0 < 1 < a
< n\) (remember that a proof of \(1 < a\) is actually defined to be the
same thing as a proof of \(2 \leq a\)).
where 0<n :0 < n 0<n = <-trans (sle zle)(<-trans 2≤a a<n)
Next, we tackle \(2 \leq b\), by showing that \(b\) can’t possibly be \(0\)
or \(1\) (using our previous lemma that anything not equal to 0 or 1
must be greater than or equal to 2).
2≤b :2 ≤ b 2≤b = ¬01-is-≥2 b
If \(b\) were \(0\), then \(ba = n\) would imply \(0 = n\), but we know
\(0 < n\), so this is a contradiction.
(λ b≡0 → <→≢ 0<n(begin0 ≡[ refl ⟩≡0 * a ≡⟨ _*_ $≡ b≡0 ≡$ a ]≡ b * a ≡[ ba≡n ⟩≡ n ∎))
If \(b\) were \(1\), then \(ba = n\) would imply \(a = n\), but we know
\(a < n\), so this is also a contradiction.
(λ b≡1 → <→≢ a<n(begin a ≡⟨ a *1 ]≡ a * 1 ≡[ *-comm a 1 ⟩≡1 * a ≡⟨ _*_ $≡ b≡1 ≡$ a ]≡ b * a ≡[ ba≡n ⟩≡ n ∎))
Finally, we prove \(b < n\), by showing \(b \leq n\) and \(b \neq n\).
b<n : b < n b<n = ≤≢→<
\(b \leq n\) since \(ba = n\) and \(a\) is not zero (if \(a\) were zero it
would contradict the fact that \(2 \leq a\)).
(*→≤ (λ a≡0 → <→≢ (<-trans (sle zle) 2≤a)(sym a≡0))(trans (*-comm a b) ba≡n))
\(b \neq n\), since \(b = n\) together with \(ba = n\) would imply \(a = 1\)
(since multiplication is cancellative), but \(2 \leq a\) so it cannot
equal 1.
(λ b≡n → <→≢ 2≤a(sym(*-cancelˡ n a 1(<→≢ 0<n)(begin n * a ≡⟨ _*_ $≡ b≡n ≡$ a ]≡ b * a ≡[ ba≡n ⟩≡ n ≡⟨ n *1 ]≡ n * 1 ∎))))
Division
Let’s start working our way towards proving that divisibility is
decidable. To check whether \(d \mid n\), the usual idea would be to
divide \(n\) by \(d\) and check whether we get a remainder of zero. So we
need to formalize this notion of division with remainder.
Specifically, when we divide \(n\) by \(d\), we expect to get a quotient\(q\)
and a remainder\(r\), such that \(r + qd = n\), and \(0 \leq r < d\).
The first condition, \(r + qd = n\), just defines what we mean by division: \(n\) is
\(q\) times \(d\), plus a remainder of \(r\). The second condition will ensure
that the result is unique. We wouldn’t want to divide \(17\) by \(2\) and
end up with a quotient of \(6\) and a remainder of \(5\); the remainder should be as small as possible.
The DivMod type simply encodes these requirements.
data DivMod (n d q r : ℕ):Setwhere DM :(r + q * d ≡ n)→(r < d)→ DivMod n d q r
We can prove a few lemmas about DivMod. First, whenever we have
DivMod n d q r, then d must be positive, since \(r < d\) and \(r\) is
a natural number.
divMod→0<d :{n d q r : ℕ}→ DivMod n d q r →0 < ddivMod→0<d (DM _ r<d)= ≤-<-trans zle r<d
We can also show that for nonzero \(d\), the remainder is zero if and only if \(d
\mid n\):
mod0→divides :(n d : ℕ){q : ℕ}→ DivMod n d q 0→ d ∣ nmod0→divides n d {q}(DM eq _)= q , eqdivides→mod0 :(n d : ℕ)→(0 < d)→ d ∣ n → Σ ℕ (λ q → DivMod n d q 0)divides→mod0 n d 0<d (q , qd≡n)= q , (DM qd≡n 0<d)
We would also like to show that if the remainder when dividing \(n\) by
\(d\) is not zero, then \(d\) does not divide \(n\). This is almost
the contrapositive of divides→mod0—which would be trivial to
show—but not quite: I said “the” remainder, but actually we don’t yet
know that the quotient and remainder are unique! Perhaps we could get
a remainder of 0 and some other remainder for the same \(n\) and \(d\), by
choosing different quotients?
Of course, quotients and remainders are unique: that is, if \(q_1,
r_1\) and \(q_2, r_2\) both satisfy the properties to be the quotient and
remainder of \(n\) divided by \(d\), then in fact \(q_1 = q_2\) and \(r_1 =
r_2\). But how can we prove this? The usual idea is to look at the
difference \(r_1 - r_2 = dq_1 - dq_2\), which is divisible by \(d\); but
since \(r_1 < d\) and \(r_2 < d\), the only way for the difference \(r_1 -
r_2\) to be divisible by \(d\) is if in fact \(r_1 - r_2 = 0\). From here
we can also derive \(q_1 = q_2\) via algebra.
Subtraction, eh? In order to formalize this, it seems as though we might
need to define the integers… but there is a better way!
Absolute difference
The previous informal argument mentioned the difference \(r_1 - r_2\).
But we could just as easily have talked about \(r_2 - r_1\) instead, and
the same argument would work just as well. This observation shows
that we do not actually care about the (signed) difference between
\(r_1\) and \(r_2\), but only the distance between them. This means we
can just stick to our well-loved natural numbers, and define a commutative
absolute difference function which computes the nonnegative distance
between its two arguments, like so:
∥_-_∥ : ℕ → ℕ → ℕ∥ zero - y ∥ = y∥ suc x - zero ∥ = suc x∥ suc x - suc y ∥ = ∥ x - y ∥
Of course, we will need a lot of small lemmas about the properties of
this operation. We can start by proving that the distance between two
numbers is 0 if and only if they are equal:
diff0 :(x : ℕ)→0 ≡ ∥ x - x ∥diff0 zero = refldiff0 (suc x)= diff0 xdiff0→≡ :{x y : ℕ}→0 ≡ ∥ x - y ∥ → x ≡ ydiff0→≡ {zero}{zero} eq = eqdiff0→≡ {suc x}{suc y} eq = suc $≡ diff0→≡ eq
Next, the distance between any number and 0 is the number itself, and
the distance function is commutative.
∥x-0∥≡x :(x : ℕ)→ ∥ x - 0 ∥ ≡ x∥x-0∥≡x zero = refl∥x-0∥≡x (suc x)= refldiff-comm :{x y : ℕ}→ ∥ x - y ∥ ≡ ∥ y - x ∥diff-comm {zero}{zero}= refldiff-comm {zero}{suc y}= refldiff-comm {suc x}{zero}= refldiff-comm {suc x}{suc y}= diff-comm {x}{y}
A key lemma supporting the argument outlined in the previous section
is that if \(x\) and \(y\) are both less than \(d\), so is their absolute difference.
diff-< :{x y d : ℕ}→ x < d → y < d → ∥ x - y ∥ < ddiff-< {zero}{y} x<d y<d = y<ddiff-< {suc x}{zero} x<d y<d = x<ddiff-< {suc x}{suc y} x<d y<d = diff-< {x}{y}(<-trans (x <suc) x<d)(<-trans (y <suc) y<d)
We can also cancel the same thing being added to both sides, or factor out
the same thing being multiplied on both sides.
diff-cancelˡ :(a b c : ℕ)→ ∥ (a + b) - (a + c) ∥ ≡ ∥ b - c ∥diff-cancelˡ zero b c = refldiff-cancelˡ (suc a) b c = diff-cancelˡ a b cdiff-distribʳ :(x y d : ℕ)→ ∥ x * d - y * d ∥ ≡ ∥ x - y ∥ * ddiff-distribʳ zero y d = refldiff-distribʳ (suc x) zero d = ∥x-0∥≡x (d + x * d)diff-distribʳ (suc x)(suc y) d = begin ∥ (d + x * d) - (d + y * d) ∥ ≡[ diff-cancelˡ d (x * d)(y * d) ⟩≡ ∥ x * d - y * d ∥ ≡[ diff-distribʳ x y d ⟩≡ ∥ x - y ∥ * d ∎
Another key lemma is that if \(w + x = y + z\), then \(\|w - y\| = \|x -
z\|\) (sub₂ below). Personally, I found this quite tricky to prove.
The best approach I found was to first prove the simpler lemma that
\(x + y = z\) implies \(x = \| z - y \|\) (sub₁), which can then be used
in several places in the proof of sub₂.
sub₁ :{x y z : ℕ}→ x + y ≡ z → x ≡ ∥ z - y ∥sub₁ {zero}{y}{z} refl = diff0 ysub₁ {suc x}{zero}{suc z} x+y≡z = begin suc x ≡⟨ suc $≡ x +0 ]≡ suc (x + 0) ≡[ x+y≡z ⟩≡ suc z ∎sub₁ {suc x}{suc y}{suc z} x+y≡z = sub₁ {suc x}{y}{z}(noConf (trans (suc $≡ sym (x +suc y)) x+y≡z))sub₂ :{w x y z : ℕ}→ w + x ≡ y + z → ∥ w - y ∥ ≡ ∥ x - z ∥sub₂ {zero}{x}{y}{z} w+x≡y+z = sub₁ (sym w+x≡y+z)sub₂ {suc w}{x}{zero}{z} w+x≡y+z = trans (sub₁ w+x≡y+z)(diff-comm {z})sub₂ {suc w}{x}{suc y}{z} w+x≡y+z = sub₂ {w}(noConf w+x≡y+z)
Quotient and remainder are unique
We can now return to prove that quotient and remainder are unique.
First, we show that zero is the only multiple of \(d\) which is less than \(d\).
∣<→0 :{d x : ℕ}→ d ∣ x → x < d →0 ≡ x∣<→0 (zero , ad≡x) x<d = ad≡x∣<→0 (suc a , ad≡x) x<d = absurd (<→≱ x<d (+→≤ ad≡x))
And now for the main event: if we have both DivMod n d q₁ r₁ and
DivMod n d q₂ r₂, then in fact the qs and rs must be the same.
divModUnique :{n d q₁ r₁ q₂ r₂ : ℕ}→ DivMod n d q₁ r₁ → DivMod n d q₂ r₂ →(q₁ ≡ q₂) × (r₁ ≡ r₂)divModUnique {n}{d}{q₁}{r₁}{q₂}{r₂} dm@(DM r₁+q₁d≡n r₁<d)(DM r₂+q₂d≡n r₂<d)= q₁≡q₂ , r₁≡r₂where
Since \(r_1 + q_1d = n\) and \(r_2 + q_2d = n\), by transitivity and
symmetry we have \(r_1 + q_1d = r_2 + q_2d\); then by the sub₂ lemma,
\(\|r_1 - r_2\| = \|q_1d - q_2d\|\).
Next, we can show that \(d\) divides the absolute difference \(\|r_1 -
r_2\|\), by factoring it out of \(\|q_1 d - q_2 d\|\).
d∣r₁-r₂ : d ∣ ∥ r₁ - r₂ ∥ d∣r₁-r₂ = ∥ q₁ - q₂ ∥ ,(begin ∥ q₁ - q₂ ∥ * d ≡⟨ diff-distribʳ q₁ q₂ d ]≡ ∥ q₁ * d - q₂ * d ∥ ≡⟨ rem-diff ]≡ ∥ r₁ - r₂ ∥ ∎)
We can then put three lemmas together to conclude \(r_1 = r_2\): first,
since \(r_1\) and \(r_2\) are both less than \(d\), so is their absolute
difference; since \(d\) also divides the absolute difference, the
absolute difference must be zero; and finally, an absolute difference
of zero means \(r_1\) and \(r_2\) must be equal.
From here, proving \(q_1 = q_2\) just requires some algebra.
dq₁≡dq₂ : d * q₁ ≡ d * q₂ dq₁≡dq₂ = +-cancelˡ r₁ (d * q₁)(d * q₂)(begin r₁ + d * q₁ ≡[ r₁ +_ $≡ *-comm d q₁ ⟩≡ r₁ + q₁ * d ≡[ r₁+q₁d≡n ⟩≡ n ≡⟨ r₂+q₂d≡n ]≡ r₂ + q₂ * d ≡[ _+_ $≡ sym r₁≡r₂ ≡$≡ *-comm q₂ d ⟩≡ r₁ + d * q₂ ∎) q₁≡q₂ : q₁ ≡ q₂ q₁≡q₂ = *-cancelˡ d q₁ q₂ (<→≢ (divMod→0<d dm)) dq₁≡dq₂
Finally, we can use uniqueness of quotients and remainders to show the
lemma we wanted about divisibility and remainders: if \(n\) divided by
\(d\) has some nonzero number as remainder, then \(d\) does not divide
\(n\). If \(d\) did divide \(n\), then we know we would get a remainder of
\(0\); but since remainders are unique, we can’t have both a zero and
nonzero remainder.
modS→¬divides :(n d : ℕ){q r : ℕ}→ DivMod n d q (suc r)→ ¬ (d ∣ n)modS→¬divides n d dm d∣n with divides→mod0 n d (divMod→0<d dm) d∣n...| q₂ , dm₂ with divModUnique dm dm₂...| q₁≡q₂ , ()
The division algorithm, take 1
So, given natural numbers \(n\) and \(d\), how do we compute the quotient
and remainder? We can write down a type DivAlg that expresses what
we want: given some \(n\) and \(d\), DivAlg n d represents the result of
the division algorithm, that is, a pair of numbers \((q,r)\) such that
DivMod n d q r holds.
DivAlg : ℕ → ℕ →SetDivAlg n d = Σ (ℕ × ℕ)(λ{(q , r)→ DivMod n d q r })
Then we want a function with a type something like (n d : ℕ) → DivAlg n d (actually this type is not quite correct—can you see why?).
How can we write something with this type?
One simple idea, expressed imperatively, is to start with \(q = 0\).
Now, as long as \(n \geq d\), subtract \(d\) from \(n\) and add one to
\(q\)—if we can find \(q\) and \(r\) such that \(r + qd = n - d\), then \(r +
(q+1)d = n\). Eventually, \(n\) must land in the range \(0 \leq n < d\),
in which case it will be the remainder, and the current value of \(q\)
will be the quotient.
Construct the evidence you would like to pattern-match on
That’s the idea, but turning this into a verified constructive algorithm will take some
work. First, let’s formalize the idea of testing whether \(n\) is less
than \(d\), and decreasing it by \(d\) if not. We’d rather not actually
deal with subtraction, so the idea is to generate either a proof that
\(n < d\), or another number \(n'\) along with a proof that \(n' + d = n\).
We encapsulate this in the following type Cmp:
data Cmp (n d : ℕ):Setwhere LT : n < d → Cmp n d GE :(n′ : ℕ)→(n′ + d ≡ n)→ Cmp n d
Cmp n d represents the result of comparing \(n\) and \(d\), and is
equivalent to having either \(n < d\) or \(n \geq d\), but expressed in a
form that is more directly useful to us. Construct the evidence you
would like to pattern-match on! That is, in general, evidence for a
proposition \(P\) can take many logically equivalent forms, and you
should pick the form that will make your life easiest at the use
site, even if it means you have to work harder to construct it in
the first place. You can write standalone lemmas for constructing
your evidence; but pattern-matching it will happen in the middle of
some bigger proof which ought not to be cluttered by calls to
conversion lemmas.
To construct evidence for Cmp n d, we write the function
decreaseBy? which decides whether we can decrease n by d or not.
Writing this function is a bit more work than writing something
of type (n d : ℕ) → (n < d) ⊎ (d ≤ n), but our work will pay off later!
_decreaseBy?_:(n d : ℕ)→ Cmp n dzero decreaseBy? zero = GE 0 reflzero decreaseBy? suc d = LT (sle zle)suc n decreaseBy? zero = GE (suc n)((suc n) +0)suc n decreaseBy? suc d with n decreaseBy? d...| LT n<d = LT (sle n<d)...| GE n′ n′+d≡n = GE n′ (trans (n′ +suc d)(suc $≡ n′+d≡n))
We can also write a helper function incDivMod which encodes the
observation from before, that if \(r + qd = n-d\), then \(r + (q+1)d =
n\). Of course we don’t actually want to use subtraction, so instead
of writing \(n-d\), we work in terms of an \(n'\) such that \(n' + d = n\).
Proving this requires only some straightforward algebra.
incDivMod :{n′ n d q r : ℕ}→ n′ + d ≡ n → DivMod n′ d q r → DivMod n d (suc q) rincDivMod {n′}{n}{d}{q}{r} n′+d≡n (DM r+qd≡n′ r<d)= DM r+d+qd≡n r<dwhere r+d+qd≡n : r + (d + q * d) ≡ n r+d+qd≡n = begin r + (d + q * d) ≡⟨ +-assoc r __ ]≡(r + d) + q * d ≡[ _+_ $≡ +-comm r _ ≡$ q * d ⟩≡(d + r) + q * d ≡[ +-assoc d __ ⟩≡ d + (r + q * d) ≡[ d +_ $≡ r+qd≡n′ ⟩≡ d + n′ ≡[ +-comm d _ ⟩≡ n′ + d ≡[ n′+d≡n ⟩≡ n ∎
Now it seems like we have everything we need to write the division
algorithm as a recursive algorithm: given \(n\) and \(d\), check whether
\(n\) can be decreased by \(d\) or not. If not, we can return \(q = 0\) and
\(r = n\). Otherwise, recurse on \(n - d\), returning the same remainder
and an incremented quotient from whatever the recursive call returns, using
incDivMod to discharge the proof obligation. It’s just a few lines
of code, right?
module DivModBad where{-# NON_TERMINATING #-} divAlg :(n d : ℕ)→ DivAlg n d divAlg n d with n decreaseBy? d...| LT n<d =(0 , n) , (DM (n +0) n<d)...| GE n′ n′+d≡n with divAlg n′ d...|(q , r) , dm =(suc q , r) , (incDivMod n′+d≡n dm)
Well, as you can see, it is just a few lines of code, but all is not
well: although this function typechecks, Agda can’t tell that it is
terminating! (I added the NON_TERMINATING pragma so I could include
this bad version of divAlg in the code without causing an error.)
The problem is that the recursive call to divAlg is on n′,
which is not a subterm of n, but instead comes from the call to
decreaseBy?. Agda has no way of knowing whether the result from
some random function call is going to end up being smaller than the
original input.
Now, you and I can both see that this function does indeed terminate,
but we just need a way to convince Agda of this fact… right?
…have you spotted the flaw? Remember how I mentioned that the type (n d : ℕ) → DivAlg n d is not quite right? In fact, the above bad
implementation of divMod is not terminating, and Agda is quite right to
be worried! In particular, the function recurses infinitely when given an input of \(d
= 0\), since it will keep subtracting \(0\) from \(n\) forever. This makes sense, of
course: everyone knows you can’t divide by zero because it makes the
universe go into infinite recursion.
The correct type for divAlg is (n d : ℕ) → (0 < d) → DivAlg n d,
but we’re still going to have trouble convincing Agda that our
algorithm is terminating. In order to do so, we need to take a detour
through well-founded induction.
Well-founded induction
Normally, Agda only allows functions that are structurally
recursive—that is, functions which make recursive calls on syntactic
subterms of their inputs. (Agda’s termination checking is a bit more
sophisticated than that, but that’s the basic idea.) However, we can
use basic structural induction to bootstrap our way into more exotic
forms. In particular, we are going to define something called
well-founded induction.Note that I will use the terms “recursion”
and “induction” more or less interchangeably. In some contexts, people
make a distinction between the terms (typically a recursion
principle is a less-dependently-typed version of an induction
principle), but in this context, inductive proofs correspond, via
Curry-Howard, to (suitably restricted) recursive functions, so
“induction” and “recursion” describe the same thing from a logical and
computational viewpoint, respectively.
The idea of well-founded induction starts with the general idea of a
relation. A relation on A is just a function that takes two
values of type A and produces a type, representing evidence that the
two values are related (according to whatever kind of relationship we
have in mind).
Rel :Set→Set₁Rel A = A → A →Set
We have already seen quite a few relations, such as equality, \(<\),
\(\leq\), and divisibility.
Suppose we’re writing a recursive function, with some relation \(\prec\)
in mind, and for a given input \(x\) we’re only allowed to make
recursive calls on values \(y\) such that \(y \prec x\). If \(\prec\) is the
“is a syntactic subterm of” relation, then we get structural
recursion as usual. But what if \(\prec\) is some other relation? What
needs to be true about \(\prec\) for this to make sense? In particular, how
can we be sure that the function won’t get stuck in infinite recursion?
One’s first instinct might be to say that \(y \prec x\) needs to imply that
\(y\) is “smaller than” \(x\) somehow. But what does “smaller than” mean?
And in fact, “smaller than” doesn’t always work: for example, if we are
writing a function over the rational numbers, or even just the
integers, the usual “smaller than” relation does not guarantee our
function will terminate; it’s possible to continue choosing smaller
and smaller rational numbers or integers forever.
The key idea is exactly that this can’t happen: it’s not possible to
have an infinite chain of values where each is related to the
previous. That is, there should be no left-infinite chains \(\dots
\prec y_3 \prec y_2 \prec y_1 \prec x\). Then we are guaranteed that if we keep making
recursive calls on values that are related by \(\prec\) to the previous
value, we will have to stop eventually: after some finite number of calls
we will hit a value with nothing else related to it.
A relation \(\prec\) with this “no left-infinite chains” property is
called well-founded. But how do we encode this idea in Agda?
Accessibility
Instead of thinking negatively (no left-infinite
chains), the key is to think positively: all chains to the left of
every value are finite. Call a value accessible if all chains
leading to it are finite. Another way to say this is that a value is
accessible if every value related to it is also accessible:
data Acc (_≺_: Rel A): A →Setwhere acc :{x : A}→((y : A)→ y ≺ x → Acc _≺_ y)→ Acc _≺_ x
Acc _≺_ x defines what it means for a particular value x to be
accessible with respect to a relation \(\prec\). There is only one
constructor, acc, which requires (y : A) → y ≺ x → Acc _≺_ y—that
is, for every value y of type A, if y is related to x, then
y is accessible. In other words, x is accessible if and only if every y ≺ x
is accessible.
This is definitely tricky to wrap your head around! At this point
you may have two objections:
What about base cases? Shouldn’t we have another constructor which
says x is accessible if nothing is related to it? Actually,
the acc constructor already says that! If nothing is related to
x, then (y : A) → y ≺ x → Acc _≺_ y is trivially true: we can
easily promise anything we want as the output of a function if we
know it can never be called. Every natural number less than zero is a
purple flying weasel.
Doesn’t this just run into the same problem as before with
left-infinite chains? If we consider the “is one less than”
relation on the integers, isn’t \(2\) accessible because \(1\) is
accessible because \(0\) is accessible because \(-1\) is accessible
because … ?
There is something a bit subtle going on here: recursive data types
in Agda (unlike Haskell) are interpreted according to a
least fixed point semantics. Put in plain terms, the only values
of a data type are those which can be built by applications of a
finite number of constructors. So in fact, the “no left-infinite
chain” condition is foundationally built into the way Agda data
types work!
The idea is that we can turn well-founded induction into structural
induction by pattern-matching on Acc proofs! Starting with some
\(x\), any \(y \prec x\) has an accessibility proof which is a subterm of
the accessibility proof for \(x\). This is a bit exotic though: if we
pattern-match on the acc for \(x\) we get a function that yields an
accessibility proof for each \(y \prec x\); calling that function
produces another accessibility proof, which counts as a structural
subterm of the original. This seems a bit strange until you think of
a value of type Acc like an big, arbitrarily-branching tree of
finite depth; each node contains a function which really just stores
all the subtrees. In other words, a function of type (y : A) → y ≺ x → Acc _≺_ y can be thought of as a giant tuple of Acc values, one
for each y \prec x.I am not sure exactly how Agda handles this
internally, but I assume this is well-trodden ground for designers of
proof assistants.
Well-founded induction, defined
Given the definition of accessible elements, we can now give the
definition of a well-founded relation: a relation on A is well-founded if
every value of type A is accessible.
WellFounded : Rel A →SetWellFounded {A}_≺_=(a : A)→ Acc _≺_ a
We can now write down the principle of well-founded induction. This
is also quite tricky to wrap your brain around, so we’ll go through it
slowly. Previously, we were just talking about whether functions terminated or
not; but the reason this is important is that a function might be
calculating a proof. A function which purports to calculate a proof
but sometimes goes into infinite recursion is a charlatan, and not
really a proof at all.
So instead of thinking about termination, let’s switch to thinking
about proofs. Given a proposition \(P\), we want to prove that
\(P\) holds for every value of type \(A\). The idea is that when trying to
prove \(P(y)\) for a particular \(y\), we get to assume that \(P(z)\) holds
(i.e. we get to make recursive calls) for all \(z \prec y\).
Here, then, is the statement of the principle of well-founded induction, with
each argument broken out on a separate line so we can explain them as
we go.
wf-ind :{P : A →Set}
P represents an arbitrary proposition on A; our goal is to show P holds for
every value of type A.
{_≺_: Rel A}→
An arbitrary relation.
WellFounded _≺_→
A proof that ≺ is a well-founded relation.
((y : A)→((z : A)→ z ≺ y → P z)→ P y)→
This is the trickiest
argument to understand. Intuitively, it says “For any
y, if we know P z holds for all z ≺ y, then we can show P y
also holds.”
(x : A)→ P x
The principle of well-founded induction says that all of this is
enough to show that P x holds for allx : A.
So, how do we implement this? If we try something
straightforward, as in wf-ind-bad below—just call ind on x, then call wf-ind recursively
to fill in the proofs for P z—of course it does not work; Agda cannot
tell that this is terminating.As an aside, Agda complains that this definition of wf-ind-bad
is not terminating—which makes sense—but it continues to complain even
when I include the NON_TERMINATING pragma, which I don’t
understand. Perhaps this has been fixed in a more recent version of Agda.
And this makes sense, because we are
not even using the fact that the relation is well-founded at all!
module WFIndBad where
{-# NON_TERMINATING #-}
wf-ind-bad : {P : A → Set} {_≺_ : Rel A} → WellFounded _≺_ → ((y : A) → ((z : A) → z ≺ y → P z) → P y) → (x : A) → P x
wf-ind-bad wf ind x = ind x (λ z Rzx → wf-ind-bad wf ind z)
Instead, the right idea is to use the fact that \(\prec\) is
well-founded to generate an initial proof of accessibility for the
input \(x\), and then pattern match on accessibility proofs alongside
the values as we recurse. Every time we make a recursive call on some
\(y \prec x\), we can just pattern-match on the accessibility proof for
\(x\) to get an accessibility proof for \(y\), so Agda will be able to see
that the whole thing is structurally recursive on the accessibility
proofs.
wf-ind {A}{P}{_≺_} wf ind x = go x (wf x)where go :(x : A)→ Acc _≺_ x → P x go x (acc f)= ind x (λ z z≺x → go z (f z z≺x))
Less-than is well-founded
Now that we have well-founded induction under our belts, let’s show
that the less-than relation on natural numbers is well-founded. This
corresponds to what is often called “strong induction”.Incidentally,
we could probably have gotten away with directly defining a principle
of strong natural number induction, without bothering with the full
generality of well-founded induction, but this way is more fun and
interesting!
To prove that \(<\) is well-founded, we of course must
show that every natural number is accessible under \(<\). However, if
we directly try to prove (m : ℕ) → (Acc _<_) m, we run into a
variant of the exact same problem we have been dealing with: to prove
that \(m\) is accessible we need to know that every\(k < m\) is also
accessible, but again, we cannot show this directly by
recursion/induction, since \(k\) may not be a structural subterm of \(m\).
What we need is the usual trick for proving strong induction from weak
induction: instead of proving that \(P(x)\) holds for all \(x\), we prove
that \((\downarrow P)(x)\) holds for all \(x\), where \(\downarrow P\) is
the “downward closure” of \(P\). That is, \((\downarrow P)(x)\) says that
\(P(x)\) holds for all\(y < x\).Note that another way to define
\((\downarrow P)(x)\) is that \(P(y)\) holds for all \(y \sim x\), where \(\sim\)
is the transitive closure of the predecessor relation. As an
advanced exercise, generalize \(\downarrow_\prec P\) to be defined relative to
the transitive closure of any relation \(\prec\), and then prove that \(\prec\) is well-founded
if and only if its transitive closure is. For more along
these lines, see this very cool (but much more abstract) post on
well-founded induction by Callan McGill.
↓ :(ℕ →Set)→(ℕ →Set)↓ P n =(k : ℕ)→(k < n)→ P k
Now we can prove, for all natural numbers \(m\), that every natural
number up to and including \(m\) is accessible under the \(<\) relation. Zero is accessible
because nothing is less than it; everything up to the successor of \(m\) is accessible because by induction we know everything up to \(m\) is, and anything less than the successor of \(m\) must in fact be \(\leq m\).
<-acc :(m : ℕ)→ ↓ (Acc _<_) m<-acc zero =λ k ()<-acc (suc m) zero (sle le)= acc (λ y ())<-acc (suc m)(suc k)(sle le)= acc (λ y y<sk → <-acc m y (<-≤-trans y<sk le))
Finally, to show that any natural number \(n\) is accessible—i.e. that \(<\)
is well-founded—we can use the fact that all numbers less than the successor of \(n\)
are accessible, and just project out accessibility for \(n\) itself.
<-wf : WellFounded _<_<-wf n = <-acc (suc n) n (n <suc)
The division algorithm
Finally, we can define the division algorithm, via well-founded
induction! The definition is very similar to our first attempt, but we use the principle of well-founded induction with \(<\). Note that neither divAlg nor its helper function go is directly recursive. Instead, go takes an induction hypothesis as an argument, which we call instead, providing an extra proof that the subject of the induction hypothesis is in fact less than the original input. wf-ind takes care of the actual recursion.
divAlg :(n d : ℕ)→(0 < d)→ DivAlg n ddivAlg n d 0<d = wf-ind {P =λ n → DivAlg n d} <-wf go nwhere go :(n : ℕ)→((n′ : ℕ)→ n′ < n → DivAlg n′ d)→ DivAlg n d go n IH with n decreaseBy? d...| LT n<d =(0 , n) , DM (n +0) n<d...| GE n′ n′+d≡n with IH n′ (+→< 0<d n′+d≡n)...|(q , r) , dm =(suc q , r) , incDivMod n′+d≡n dm
Using the division algorithm, we can also finally decide whether one
number divides another: zero divides zero; zero does not divide any
successor since that would imply there is some \(k\) such that \(k\) times
zero is nonzero, which is absurd; and if \(x\) is a successor, we can
apply the division algorithm and check the remainder, applying some
previous lemmas that say what zero and nonzero remainders tells us
about divisibility.
_∣?_:(x y : ℕ)→ Dec (x ∣ y)zero ∣? zero = yes (0 , refl)zero ∣? (suc y)= no λ{(a , eq)→ absurd (noConf (trans (sym (*-comm a zero)) eq))}(suc x) ∣? y with divAlg y (suc x)(sle zle)...|(q , zero) , dm = yes (mod0→divides y (suc x) dm)...|(q , suc r) , dm = no (modS→¬divides y (suc x) dm)
Primality testing
To test a number for primality, we are just going to use
straightforward, naive trial division. The straightforward way of
doing this is by starting at \(2\) and counting up—but this is a
problem, because when pattern-matching on natural numbers we most
naturally count down.
Well, remember—build the evidence you want to pattern-match on! Let’s
develop some machinery for counting up instead of down.
Counting up
The problem starts with \(\leq\): a proof of \(m \leq n\) starts with a
base case representing evidence that \(0 \leq k\), then every
constructor application of sle increments both sides by one.
Pattern-matching on a proof of \(m \leq n\) thus either reveals that \(m
= 0\), or that \(m' \leq n'\) where \(m'\) and \(n'\) are the predecessors of
\(m\) and \(n\): in other words, it facilitates counting down, just
like matching directly on \(m\) would.
However, there is an alternative way to define the \(\leq\) relation,
which we will call \(\leq'\).
We can choose reflexivity of \(\leq'\) as a base case, that is, \(n \leq'
n\) for any \(n\). We can then decrement the left-hand side every time
we apply another constructor. Like so:
data_≤′_: ℕ → ℕ →Setwhere lerefl :{n : ℕ}→ n ≤′ n lesuc :{m n : ℕ}→ suc m ≤′ n → m ≤′ n
Pattern-matching on a proof of \(m \leq' n\) thus facilitates counting
up from \(m\) to \(n\), just like we wanted!
We can also prove a few lemmas about properties of \(\leq'\). For
example, the two axioms that define the usual \(\leq\) can be proved as
lemmas.
≤′-suc :{m n : ℕ}→ m ≤′ n → suc m ≤′ suc n≤′-suc lerefl = lerefl≤′-suc (lesuc m≤′n)= lesuc (≤′-suc m≤′n)0≤′ :(n : ℕ)→0 ≤′ n0≤′ zero = lerefl0≤′ (suc n)= lesuc (≤′-suc (0≤′ n))
We can also prove that \(m \leq n\) implies \(m \leq' n\). (The converse
is true as well, and can be proved as an easy exercise, but we won’t need it.)
≤→≤′ :{m n : ℕ}→ m ≤ n → m ≤′ n≤→≤′ {n = n} zle = 0≤′ n≤→≤′ (sle m≤n)= ≤′-suc (≤→≤′ m≤n)
So, we can pattern-match on a proof of \(m \leq' n\) to count up from \(m\) to
\(n\), but this isn’t quite good enough: while counting, we won’t remember the relationship of the
intermediate values to the original \(m\). We would like to be able to
count up through some interval, from some starting \(a\) to ending \(b\),
knowing all along the way that the values we count are contained in
the interval.
To this end, we can create a data
type i ∈[ a ⋯ b ] which represents a stage in counting from \(a\) to
\(b\). The base case is when \(i = b\); otherwise i ∈[ a ⋯ b ] when \(a
\leq i\) and also suc i ∈[ a ⋯ b ].
data_∈[_⋯_] : ℕ → ℕ → ℕ →Setwhere stop :{a b : ℕ}→ a ≤ b → b ∈[ a ⋯ b ] step :{a i b : ℕ}→ a ≤ i → suc i ∈[ a ⋯ b ] → i ∈[ a ⋯ b ]
We can then write a function which “constructs a loop”—that is,
starting from a proof of \(a \leq' b\), it builds
a value of type a ∈[ a ⋯ b ] which represents a reified loop from
\(a\) to \(b\). By pattern-matching on this value we can successively
increment from \(a\) up to \(b\), with the appropriate guarantees along
the way.
loop :(a b : ℕ)→(a ≤′ b)→ a ∈[ a ⋯ b ]loop a b a≤′b = mid a a b ≤-refl a≤′bwhere mid :(a i b : ℕ)→(a ≤ i)→(i ≤′ b)→ i ∈[ a ⋯ b ] mid a i b a≤i lerefl = stop a≤i mid a i b a≤i (lesuc i≤′b)= step a≤i (mid a (suc i) b (≤-sucr a≤i) i≤′b)
Finally, we need as a simple lemma the fact that if i ∈[ a ⋯ b ]
then in fact \(i \leq b\).
top :{i a b : ℕ}→ i ∈[ a ⋯ b ] → i ≤ btop (stop _)= ≤-refltop (step _ s)= ≤-sucl (top s)
Primality testing by trial division
First, a lemma about downward closure: if we know \((\downarrow P)(m)\),
and we know \(P(m)\), then we know \((\downarrow P)(1 + m)\). In other
words, if \(P\) holds for everything less than \(m\), we can extend it by
one by providing a proof that \(P\) also holds for \(m\).
extend :{P : ℕ →Set}{m : ℕ}→(↓ P) m → P m →(↓ P)(suc m)extend {m = m} soFar Pm j with(j ≟ m)...| yes refl =λ_→ Pm...| no j≢m =λ{(sle j≤m)→ soFar j (≤≢→< j≤m j≢m)}
Now we can define primality testing itself, via trial division. We
loop from \(2\) up to \(n\), testing each number to see if it divides
\(n\), keeping track along the way of the fact that all the numbers less
than our current trial divisor do not divide \(n\). If the next divisor
does divide \(n\), we return it as proof that \(n\) is composite. If it
does not, we extend our accumulating proof of all the numbers that do
not divide \(n\), and proceed to the next. If we reach \(n\), our
accumulated proof tells us that none of the numbers less than \(n\)
divide it, which is proof that \(n\) is prime.
prime? :(n : ℕ)→(2 ≤ n)→ Prime n ⊎ Composite nprime? n 2≤n = trialDiv (loop 2 n (≤→≤′ 2≤n)) noDivisorsUpTo2where NoDivisorsUpTo : ℕ →Set NoDivisorsUpTo = ↓ (λ # →(2 ≤ #)→ ¬ (# ∣ n)) noDivisorsUpTo2 : NoDivisorsUpTo 2 noDivisorsUpTo2 (suc zero)_(sle ())_ noDivisorsUpTo2 (suc (suc j))(sle (sle ()))__ trialDiv :{m : ℕ}→ m ∈[ 2 ⋯ n ] → NoDivisorsUpTo m → Prime n ⊎ Composite n trialDiv (stop 2≤n) soFar = inj₁ (2≤n , soFar) trialDiv {m}(step 2≤m next) soFar with m ∣? n...| yes m∣n = inj₂ (m , 2≤m , top next , m∣n)...| no pf = trialDiv next (extend soFar (λ_→ pf))
Lists
Before we are able to state the Fundamental Theorem of Arithmetic, we need to build up a data type for lists, along with some standard list manipulation functions. First, we define the type of lists and the standard foldr function.
data List (A :Set):Setwhere [] : List A_∷_: A → List A → List Afoldr :(A → B → B)→ B → List A → Bfoldr _&_ z [] = zfoldr _&_ z (x ∷ xs)= x & foldr _&_ z xs
Now we can define concatenation and product via foldr.
_++_: List A → List A → List Axs ++ ys = foldr (_∷_) ys xsproduct : List ℕ → ℕproduct = foldr _*_1
We will need All, which expresses that some predicate holds of all
the elements of a list. In fact, All is manifestly an instance of
foldr as well, but we would need a universe-polymorphic version of foldr for that, so we just write it manually.
All :(P : A →Set)→ List A →SetAll P [] = ⊤All P (x ∷ xs)= P x × All P xs
Now, we just need a couple lemmas about concatenation: first, that if P holds for all the elements in xs and all the elements in ys, then it holds for all the elements in xs ++ ys; and second, that product distributes over concatenation (i.e. it is a homomorphism from the monoid of lists under concatenation to the monoid of natural numbers under multiplication).
All-++ :{P : A →Set}{xs ys : List A}→ All P xs → All P ys → All P (xs ++ ys)All-++ {xs = []} Pxs Pys = PysAll-++ {xs =_ ∷ _}(Px , Pxs) Pys = Px , All-++ Pxs Pysproduct-++ :(xs ys : List ℕ)→ product (xs ++ ys) ≡ product xs * product ysproduct-++ [] ys = sym (_ +0)product-++ (x ∷ xs) ys = trans (x *_ $≡ product-++ xs ys)(sym (*-assoc x (product xs)(product ys)))
The Fundamental Theorem of Arithmetic
Finally, we can put all the pieces together to state and prove (one
half of) the Fundamental Theorem of Arithmetic! FTA n says that for
some positive integer n, we can find a list of natural numbers which
are all prime, and whose product is n.
FTA : ℕ →SetFTA n = Σ (List ℕ)(λ ps → All Prime ps × product ps ≡ n)
To prove that this holds for all positive integers, we can again use
well-founded induction: in the base case, if \(n = 1\), the empty list
suffices. Otherwise, we can decide whether \(n\) is prime. If so, the
singleton list containing \(n\) fits the bill. Otherwise, \(n = ab\) where
\(a\) and \(b\) are both nontrivial divisors of \(n\); by the induction
hypothesis, both can be factored into primes, and the list we want for
\(n\) is simply the concatenation of the factorizations for \(a\) and \(b\).
fta :(n : ℕ)→(0 < n)→ FTA nfta n = wf-ind {P =(λ n →(0 < n)→ FTA n)} <-wf go nwhere go :(n : ℕ)→((n′ : ℕ)→ n′ < n →0 < n′ → FTA n′)→0 < n → FTA n go (suc zero) IH 0<n = [] , (tt , refl) go (suc (suc n)) IH 0<n with prime? (suc (suc n))(sle (sle zle))...| inj₁ P =(suc (suc n) ∷ []) , ((P , tt) , (suc $≡ (suc $≡ (n *1))))...| inj₂ C with factorsOf _ C...|((a , sle _ , a<n , _) , (b , sle _ , b<n , _)) , ab≡nwith IH a a<n (sle zle)| IH b b<n (sle zle)...| ps₁ , Pps₁ , prod₁ | ps₂ , Pps₂ , prod₂ =(ps₁ ++ ps₂) , (All-++ Pps₁ Pps₂) , begin product (ps₁ ++ ps₂) ≡[ product-++ ps₁ ps₂ ⟩≡ product ps₁ * product ps₂ ≡[ _*_ $≡ prod₁ ≡$≡ prod₂ ⟩≡ a * b ≡[ ab≡n ⟩≡ suc (suc n) ∎
Further Directions
That concludes our tour of the Fundamental Theorem of Arithmetic in Agda! If you’ve worked through the whole thing and
completed the proofs mostly on your own, congratulations! If you want
more practice, there are a lot of directions you could take this:
Doing trial division all the way up to \(n\) is silly; we can stop
when we get to \(\sqrt n\). I think this would make for a nice
exercise (in fact, Taneb’s version in the Agda stdlib does this).
Define “\(d\) is a proper divisor of \(n\)” to mean that that \(d \mid n\)
and \(2 \leq d < n\), then show that the “is a proper divisor of” relation
is well-founded, and prove fta via well-founded induction on that
relation instead. This might streamline some parts of the proof;
I’m not sure.
The other half of the FTA says that the prime factorization is
unique up to permutation. To prove this, one has to define
what it means for one list to be a permutation of another, and show that
if there are two different prime factorizations then one must be a
permutation of the other (if \(p\) is a prime from the first
factorization, then it divides the other factorization as well,
which means it must be equal to one of the primes in the other
factorization). I may write up this proof in a follow-up post.
<noscript>Javascript needs to be activated to view comments.</noscript>
Tell your elected representatives and the Prime Minister that blocking our indyref mandate is unacceptable.
The Scottish Parliament elections in May 2026 returned the largest ever pro-independence majority in the history of the Scottish Parliament. That democratic majority provides an undeniable mandate for a second Scottish independence referendum, and the Parliament has now confirmed that mandate by demanding the UK Government transfer the powers required to hold that referendum.
Every one of those 73 MSPs stood on a manifesto platform supporting Scotland’s right to choose its own future and calling for a second independence referendum. The Scottish people have therefore elected a parliament with a clear democratic mandate to demand a referendum on Scottish independence.
All democrats must believe that the Scottish people have an inalienable right to choose their own future. The Scottish people have voted for a second independence referendum. Any attempt to deny them the right to choose their own future is an assault on Scottish parliamentary democracy and an affront to the people of Scotland - so that mandate must not be denied.
This is the thirty-first edition of our Haskell ecosystem activities report,
which describes the work Well-Typed are doing on GHC, Cabal, HLS and other parts
of the core Haskell toolchain. The current edition covers roughly the months of
March 2026 to May 2026.
We offer Haskell Ecosystem Support Packages to provide commercial
users with support from Well-Typed’s experts while investing in the Haskell
community and its technical ecosystem including through the work described in
this report. To find out more, read our announcement of these
packages in partnership with
the Haskell Foundation. We need funding to continue this essential maintenance work!
Rodrigo and Wolfgang have continued working to disentangle base from GHC,
with the ultimate goal of being able to use different versions of base with
a single GHC version. This is all part of a long-term project to make
GHC upgrades easier, documented in the
reinstallable-base repo,
and recently described in an
excellent haskell.org blog article by Simon Peyton Jones.
Simon, Rodrigo and Wolfgang are working together to rethink GHC’s treatment of
“known-key names” so base will be much less tightly coupled to ghc-internal (!15899).
One big milestone was making the current base buildable both with GHC 9.14
(!16070) and with the upcoming GHC 10.0 (!16035).
Various other pieces of technical groundwork were required:
moving most of the System.IO implementation into base (!15694),
making various SafeHaskell-related changes (CLC #408, !16034).
Wolfgang also opened several CLC proposals identifying key areas that require further
work:
the deprecation of unstable base modules (CLC #392), and
working towards making bytestring and text not depend on internal
I/O machinery (CLC #410).
Semaphores and -jsem
The implementation of semaphores used by cabal-install and GHC to coordinate
concurrency suffered from a serious issue when GHC and cabal-install were
linked against different libc implementations (#25087).
Zubin remedied this issue with a new semaphore implementation on top
of Unix domain sockets (!8), described in GHC proposal #673. GHC (!15729) and
cabal-install (#11628) were then
switched to this new protocol version.
As part of this work, Zubin also identified some deficiencies in the semantics
of interruptible FFI (#27110).
Cabal modernisation
Sam worked to modernise the architecture of cabal-install by making it directly call the Cabal library to build packages (#11703).
This unlocked the performance optimisations described in a recent blog post (#11767, #11768), achieving
speed-ups of around 10-15% in certain situations.
In the long term, we would like to move towards Cabal having a fine-grained build graph across the whole project, rather than using a component-level build graph and relying on GHC to orchestrate the compilation of all the modules in a component/package. This will unlock more parallelism and other developer experience improvements.
Sam also implemented many improvements to build-type: Hooks, the modern
replacement for build-type: Custom:
improved recompilation checking for pre-build rules (#11731),
support for generating non-Haskell files in pre-build rules (#11573).
Tobias chimed in by adding support for recursive globs in file monitoring, which is useful for SetupHooks (#11658).
Windows DLL support
Duncan, with the help of David, embarked on the project of adding proper dynamic
linking support to GHC on Windows. While this is still work-in-progress,
several important steps have already been taken:
extending Cmm syntax to support symbols from external DSOs/DLLs (!15135),
solving the recursive DLL dependency between the RTS and ghc-internal
(!15907),
making GHC use __attribute__((dllimport)) for external symbol
declarations (!15914),
updating Hadrian to create individual .def files per ghc-internal DLL
(!16082).
Critical process issue on macOS
Magnus diagnosed a critical issue with process on macOS
(#27144, #356), implementing a fix
in #363. As part of this work,
he discovered an issue with several uploaded versions of process
(#365) which was resolved by
coordinating with the process maintainers.
GHC
Releases
Keeping all of GHC’s active release branches in good shape is a demanding,
largely behind-the-scenes effort. Each release requires triaging and backporting
a steady stream of bugfixes, with patches that often don’t cleanly apply and
require careful reworking. Information about upcoming releases is available on the
GHC release status page.
GHC currently has four (!) active branches. Zubin worked towards the
10.0 release as well as on 9.14.2; Magnus prepared 9.12.5, and Andreas
took on 9.10.4.
Frontend
Rodrigo bumped the default language edition to GHC2024 (#26039, !14420).
Starting from GHC 10.0, code without an explicit language edition will
default to GHC2024. Compared to GHC2021, this adds the extensions DataKinds,
DerivingStrategies, DisambiguateRecordFields, ExplicitNamespaces,
GADTs, MonoLocalBinds, LambdaCase and RoleAnnotations.
Magnus fixed the documentation of getSizeofMutableByteArray# (!16065).
Sam fixed a loop with -XDeepSubsumption on GHC 9.14 (#26823, !15604).
Wolfgang made several performance improvements to the driver, allowing
downsweep to use existing module graph nodes (!16028), introducing a cache
for hole modules (!15888), and storing home unit dependencies as sets (!15849).
Hannes made several performance improvements to ghc-pkg, speeding up its closure
computation (!16062) and migrating it to use OsPath (!15584).
Andreas modularised the GHC.Driver.Main module (!15940), as that single
module had become quite unwieldy.
Following on from previous work allowing typechecker plugins to run in the
pattern match checker (!14797), Sam made sure that plugins are only initialised
once per module (!15485), fixing the regression reported in #26839.
Rodrigo provided a standalone reproducer for the simplifier slowness reported
in #26989, which allowed Simon Peyton Jones to diagnose and fix this quadratic
behaviour (!15725).
Sam investigated the type family performance regressions reported in #26426,
identifying two key patches that had accidentally fixed the regression and
recording these findings in Notes (!16113).
Andreas identified that a patch to use Generics within GHC significantly
regressed compile times (#27191). The offending patch was reverted for the
time being, and the coding style Wiki page was updated to
document this unfortunate limitation.
Backend
Sam finished up work by Matthew Craven to improve the representation of
floating point literals in GHC, fixing several issues with the treatment of
negative zero and NaN values (!15528). This brings GHC much closer to proper
IEEE 754 floating point compliance.
Andreas discovered a bug with AArch64 profiled dynamic builds of GHC and
concluded that it was a bug in gcc/binutils (#26994).
Sam fixed a crash in Core Prep caused by invalid profiling tick occurrences
(#27182, !16003).
Sam investigated a crash in mkDupableContWithDmds, and worked with Simon
Peyton Jones to land a fix (#27261, !16084).
Sam fixed several bugs in the implementation of the hsExprType function
(#26910, !15772).
Zubin fixed the typing of void pointer chains in capi FFI calls to avoid
-Wincompatible-pointer-type errors by the C compiler (#26852, !15547).
Sam helped first-time contributor Avery Parker land his AmeriHac contribution
to add constant folding for SIMD vector operations (!15512).
Sam reviewed several patches to the AArch64 native code generator by Ian Duncan,
in the process uncovering a cluster of latent correctness bugs:
!15620 fixed a bug in “shift right” using a logical shift instead of an
arithmetic shift (#26979). A separate register clobbering bug was
identified and fixed.
!15619 fixed sign extension at 32-bit width (#26978). A separate bug
with the overflow bit was identified and fixed (#27047). Another
register clobbering bug was found and fixed separately (#27046, !16031).
Sam fixed a recalcitrant “failed to detect OverLit” crash in
coreExprToPmLit (!15895, #27124, #25926).
Magnus and Sam investigated the GHC panic reported in #27227, which was
narrowed down to Cabal bug #7684,
and subsequently fixed (#11791).
ghci & bytecode
Work continued on making the bytecode interpreter, which underpins GHCi as well
as the debugger, more capable and memory efficient.
Hannes introduced the -fimport-loaded-target ghci flag to fix a regression
with the :add command relating to support for multiple home units
(!15533, #26866).
Hannes added support for hpc in the bytecode interpreter (#27036, !15843).
Rodrigo added support for static constructors in the bytecode interpreter,
also fixing its treatment of unlifted values (#25636, !15221).
Hannes improved the memory usage of the bytecode interpreter by recording only
a LinkableUsage instead of Linkable in LoaderState (#26500, #27018,
!15689).
RTS
Duncan consolidated the ticker implementations to a single one on POSIX
(!15781), removing signal-based ticker implementations (!15757, !16014)
which presented a number of disadvantages (described in #27073).
David resurrected an old MR improving the documentation of the allocator
(!3812).
Andreas added missing profiling headers for origin_thunk frames (!15665).
Duncan identified some incorrect STOP_THREAD status codes in ghc-events
(#130).
Build system
David made several improvements to GHC’s build system and Hadrian, in
relation to his work on Windows DLL support:
work on response files to avoid MAX_PATH issues on Windows (!15891, !16120).
Andreas fixed an issue with --target in the configure script (!15649).
Zubin stopped Hadrian from including package hashes in Haddock directory names,
as this was causing many broken links when browsing Haddocks (#26635, !15475).
GHC contribution experience
Magnus overhauled the MR template to be more helpful for new contributors
(!15943, #27165).
Many team members provided reviews and helped land contributions from others,
as described elsewhere in this report.
CI and tests
Magnus has been doing significant work on the gitlab.haskell.org
instance and CI infrastructure to improve robustness of CI, deal with spam
and manage the server load imposed by AI crawlers.
Magnus changed the Darwin CI to clone rather than copy when creating the Cabal cache (!15683).
Sam added a vendored mini-QuickCheck component for use in GHC’s testsuite,
fixing some bugs in the previous implementation used in the foundation
primops testsuite (!15893, #25969, #25990).
Haskell Language Server
Zubin prepared release 2.14.0 of the Haskell Language Server (#4897).
#4865 migrating
the Stackage build to use GitHub actions,
#4854 fixing
a redundant hash in the ghcide cache path.
Hannes released version 0.19.0 of hie-bios (#506).
Sam fixed a hie-bios regression in which the local build directory would get overwritten,
leading to cache trashing (#501, #503).
Haskell syntax highlighting
Sam fixed a large number of bugs
in the language-haskell VS Code syntax highlighting extension.
Haskell Debugger
Rodrigo continued to lead development of the
Haskell Debugger (hdb), an
interactive step-through debugger for Haskell,
with contributions from Andrea and Hannes.
Built on top of the bytecode
interpreter, it implements the Debug Adapter Protocol,
allowing debugging of Haskell programs directly in the editor. We:
added a new RTS message to GHC allowing a thread’s flags (TSO flags)
to be set or unset (!15831, #27131), which is needed to safely implement
features like pausing, or toggling step-out/step-in per thread;
arranged for hdb to run the debuggee directly in the terminal
when using the external interpreter
(#260);
added support for custom external interpreter commands to GHC (!15676),
making use of them rather than parsing heap terms (#222);
fixed a bug where forcing a thunk would invalidate stack frames on
all threads rather than just the right one
(#292), and fixed
breakpoints being overwritten by looking for active breaks in the correct
ModBreaks
(#298);
refactored the home-unit session initialisation
(#279).
Andrea made various quality-of-life improvements to the debugger:
landed an old MR by Teo Camarasu, adding support for the non-moving GC (!10).
eventlog-live, eventlog-socket
Wen continued to develop eventlog-live,
which allows GHC’s eventlog to be monitored live as a program runs.
Highlights of the changes to eventlog-live:
support for receiving eventlog input over TCP (#154, #155),
made the profiler more robust, ensuring it never crashes on decoding
errors (#12) and
backporting a fix for stack-decoding segmentation faults from GHC HEAD
(#20);
integrated the profiler with
eventlog-socket, adding
support for its lifecycle hooks
(#19) and an
eventlog-socket test suite
(#25);
improved thread management by using async
(#10) and
exposing stopStackProfilerThread
(#11).
IHaskell
Sam added Windows support to IHaskell, a library that provides Haskell
integration for Jupyter notebooks (#1595).
stm library
Magnus performed some important maintenance tasks on the stm library,
adding missing compiler versions to CI (#98)
and fixing a slow test (#97).
I recently found a way to represent sheaves in Haskell. It was a fun couple of
weeks of head-scratching. But as much as I wanted it to, the code in my
demonstration repo doesn’t speak for itself. So I’m writing this blog
post to share my newfound understanding. In this post I’ll be assuming a pretty
solid knowledge of category theory (but not of sheaves, which I’ll be
explaining). If you aren’t, wait until my next post which will give a more
practical introduction to sheaves.
I don’t think it’s
necessary to use Haskell for this. Other functional programming languages should
work as well, but Haskell certainly makes some things easier as types get a bit
dependent eventually. Of course, it would be even easier in a true dependently
typed language, but the whole point was to avoid needing that level of sophistication.
As a general warning: all of this is about translating well-known mathematical
concepts into Haskell. While doing so, I have to use a lot of approximations, as
Haskell doesn’t have, say, a notion of equality. I will generally not even
mention any conditions that I’m supposed to prove to properly align with the
mathematical definitions, and only focus on the operational aspects. I’ll try to
leave enough breadcrumbs to fill in the gaps for those of you who would want to.
First, presheaves
I’ll start by giving a concrete instance of sheaves, which makes the definition
surprisingly transparent. Later I’ll be expanding that to the general notion of
sheaves.
Let’s give ourselves a category of arithmetic expressions, or
rather, arithmetic functions. It’s got just enough material to illustrate the point.
(I named the presheaves’ restriction pb, for “pullback”, because we’re going
to be writing it quite a lot.)
The category of presheaves (with natural transformations forall i. p i -> q i
as morphisms) is a Cartesian closed category (and then some) which contains the
Expr category as a full subcategory, via the Yoneda embedding
Therefore we can think of the category of presheaves as a completion of
Expr with a bunch of extra structure. And the problem that we will want
to solve is that presheaves actually add too much structure. This manifests in
the impossibility of interpreting IfThenElse. Or, rather, the Yoneda embedding
lets us build a presheaf
ifThenElse::YTBooli->Yji->Yji->Yji
But this isn’t the usual type of ifThenElse, we want instead
Unfortunately, we can’t define such an ifThenElse function. This is because
Y TBool isn’t a coproduct in the category of presheaves. Presheaves create
coproducts (and in fact all colimits) freely.
What we can do, however, is define a new type class, and we can even define it
in the most on-the-nose way possible (because nobody is stopping us).
This is almost insultingly straightforward, but I swear this is a mere
specialisation of the general definition of sheaves, only slightly simplified
from the definition seen in textbooks.
Now, of course, sheaves support ifThenElse as we wanted, but the truly
astounding thing is that the theory of sheaves tells us that the category of
sheaves (and natural transformations forall i. p i -> q i) also has all the
structure we need from the category of presheaves. In particular it’s Cartesian
closed. Let’s demonstrate this next.
Closed Cartesianness
Products of sheaves are simply Haskell’s product applied fibrewise, same as with
presheaves:
Exponential objects are more complicated. If you’ve never seen exponentials of
presheaves before, you can think of the type in terms of variance: because
forall i. p i -> q i is contravariant in p, we can’t implement pb for
natural transformation directly. So we freely adjoin the presheaf structure.
Here again, the construction is the same for presheaves and sheaves.
typePFun::(Ty->Type)->(Ty->Type)->(Ty->Type)newtypePFunpqi=MkPFun(forallk.Exprki->pk->qk)instance(Presheafp,Presheafq)=>Presheaf(PFunpq)wherepbf(MkPFung)=MkPFun$\kx->g(composekf)xinstance(Presheafp,Sheafq)=>Sheaf(PFunpq)where-- This is not a typo, `p` only needs to be a presheaf.-- It's occasionally useful.glueIfThenElseb(MkPFunft)(MkPFunff)=MkPFun$\kx->glueIfThenElse(k`compose`b)(ftkx)(ffkx)
I found that the twist in the definition of exponentials is the source of
much of the difficulties in working with sheaves. For instance, this is why we
need IfThenElse and glueIfThenElse rather than this more typical way of
expressing that TBool is a coproduct of Unit and Unit:
It turns out that IfThenElse is, in fact, strictly stronger than cocone in
general. I started the project believing them to be equivalent, but they
aren’t in general. They are equivalent in a Cartesian closed category (among
other things) though, but Expr isn’t Cartesian closed. Textbooks also
have a version of glueCocone, specifically that sheaves must verify that
p TBool must be isomorphic to a pair p TUnit. Realising that this condition
wasn’t sufficient to prove that PFun p q was a sheaf took me a while; and this
is how, dear reader, one loses nights of sleep.
Yoneda embeddings as sheaves
Another thing, with our definition of sheaves, is that the Yoneda embeddings
of objects Ty are sheaves. This won’t always be the case for the general
notion of sheaves below, though.
The category of sheaves also has coproducts, but they aren’t the same as that of
presheaves. Coproducts of presheaves are defined fibrewise like products, but as
we’ve been saying this is “too free”, in that it creates a coproduct for TUnit
and TUnit which is distinct from TBool.
Fortunately, there’s a technical device which makes
defining coproducts of sheaves easy: the free sheaf construction, also known as sheafification.
It turns out that we can construct a free sheaf out of any presheaf, and the way
you do that is to simply store all the uses of glueIfThenElse instead of
running them (much like PFun stores all the uses of pb instead of running
them):
You can also define recursive data types like lists (in categorical terms,
polynomial endofunctors have initial algebras), you just have to make sure to
wrap all the recursive calls with Sheafify. The easiest way is to inline
Sheafify like so:
Now we have the general idea set up. Let’s tackle the general notion of
sheaves. First we can get rid of Expr, and use an arbitrary category as
a base.
-- The `Category` class from base.typeCategory::forall{k}.(k->k->Type)->ConstraintclassCategoryhomwhereid::homaa(.)::hombc->homab->homac
Presheaves readily generalise to arbitrary categories
We will need an extra piece of data in order to define sheaves, called a
Grothendieck topology (I’ll just be saying “topology”). This will be the part
that lets us choose which objects of the base category are to be colimits in the
category of sheaves.
Before I show how we can represent topologies in Haskell, let us make a small
detour and examine the textbook definition of sheaves (and reverting to
mathematical notation for a moment). First a new notion: a sieve on an object
<semantics>a<annotation encoding="application/x-tex">a</annotation></semantics>a is a set of arrows with codomain <semantics>a<annotation encoding="application/x-tex">a</annotation></semantics>a closed by precomposition. That is a
set <semantics>S<annotation encoding="application/x-tex">S</annotation></semantics>S, such that for any <semantics>(x<mover><mo><mo>⟶</mo></mo><mi>f</mi></mover>a)∈S<annotation encoding="application/x-tex">(x \stackrel{f}{\longrightarrow} a)\in S</annotation></semantics>(x⟶fa)∈S and
any arrow <semantics>(y<mover><mo><mo>⟶</mo></mo><mi>g</mi></mover>x)<annotation encoding="application/x-tex">(y \stackrel{g}{\longrightarrow} x)</annotation></semantics>(y⟶gx), we also have <semantics>(y<mover><mo><mo>⟶</mo></mo><mi>g</mi></mover>x<mover><mo><mo>⟶</mo></mo><mi>f</mi></mover>a)∈S<annotation encoding="application/x-tex">(y
\stackrel{g}{\longrightarrow} x \stackrel{f}{\longrightarrow} a)\in S</annotation></semantics>(y⟶gx⟶fa)∈S. A
topology is a set of such sieves (subject to some axioms). Sieves in a topology
are called covering sieves.
Let <semantics>P<annotation encoding="application/x-tex">P</annotation></semantics>P be a presheaf. A matching
family in <semantics>P<annotation encoding="application/x-tex">P</annotation></semantics>P, for a covering sieve <semantics>S<annotation encoding="application/x-tex">S</annotation></semantics>S on <semantics>a<annotation encoding="application/x-tex">a</annotation></semantics>a, is a function <semantics>m<annotation encoding="application/x-tex">m</annotation></semantics>m mapping each
<semantics>(x<mover><mo><mo>⟶</mo></mo><mi>f</mi></mover>a)∈S<annotation encoding="application/x-tex">(x \stackrel{f}{\longrightarrow} a)\in S</annotation></semantics>(x⟶fa)∈S to <semantics>mf∈P(x)<annotation encoding="application/x-tex">m_f ∈ P(x)</annotation></semantics>mf∈P(x), such that <semantics>mf.g=pb(g)(mf)<annotation encoding="application/x-tex">m_{f . g} = \mathsf{pb}(g) (m_f)</annotation></semantics>mf.g=pb(g)(mf). Then,
<semantics>P<annotation encoding="application/x-tex">P</annotation></semantics>P is a sheaf if for every such matching family <semantics>m<annotation encoding="application/x-tex">m</annotation></semantics>m, there is a unique <semantics>glue(m)∈P(a)<annotation encoding="application/x-tex">\mathsf{glue}(m) \in P(a)</annotation></semantics>glue(m)∈P(a)
such that <semantics>mf=pb(f)(glue(m))<annotation encoding="application/x-tex">m_f = \mathsf{pb}(f) (\mathsf{glue}(m))</annotation></semantics>mf=pb(f)(glue(m)) for all <semantics>f∈S<annotation encoding="application/x-tex">f ∈ S</annotation></semantics>f∈S.
Now, this is an extraordinarily compact definition. It achieves a lot in just a
handful of axioms. But it’s also a very wasteful definition. The definition of
sieves requires that all the <semantics>(y<mover><mo><mo>⟶</mo></mo><mi>g</mi></mover>x<mover><mo><mo>⟶</mo></mo><mi>f</mi></mover>a)∈S<annotation encoding="application/x-tex">(y \stackrel{g}{\longrightarrow} x \stackrel{f}{\longrightarrow} a)\in S</annotation></semantics>(y⟶gx⟶fa)∈S
are arguments of <semantics>m<annotation encoding="application/x-tex">m</annotation></semantics>m, but at the same time that <semantics>mf.g<annotation encoding="application/x-tex">m_{f . g}</annotation></semantics>mf.g is determined by <semantics>mf<annotation encoding="application/x-tex">m_f</annotation></semantics>mf.
This is very unsatisfactory from a functional programming perspective, as we like
to make illegal things unrepresentable, but the mathematical definition gives us
infinitely many ways to represent illegal states. Besides, having many
irrelevant values to take into account adds unwanted noise to our programs.
Even if you are fine with those issues, there’s a bigger problem. The
implementation of gluing for exponentials (much for the same reason as exponentials
needing the full IfThenElse rather than merely cocone) necessarily involves a
sieve, called the pullback sieve <semantics>f∗S<annotation encoding="application/x-tex">f^*S</annotation></semantics>f∗S where (<semantics>b<mover><mo><mo>⟶</mo></mo><mi>f</mi></mover>a)<annotation encoding="application/x-tex">b \stackrel{f}{\longrightarrow}
a)</annotation></semantics>b⟶fa) is an arrow and <semantics>S<annotation encoding="application/x-tex">S</annotation></semantics>S is a sieve on <semantics>a<annotation encoding="application/x-tex">a</annotation></semantics>a; <semantics>f∗S<annotation encoding="application/x-tex">f^*S</annotation></semantics>f∗S is, then, a sieve on <semantics>b<annotation encoding="application/x-tex">b</annotation></semantics>b.
And this is too much dependent typing for even Haskell. I’ve
tried to make it work but couldn’t.
Which leads us to our first simplification: we don’t need covering sieves, we
can consider arbitrary covering families of arrows (the corresponding covering
sieve is the sieve generated by those arrows, but it’ll only exist in our head). Our second simplification
is that we don’t even need covering families to be families of arrows:
arbitrary types will do. This will remove most of the obstacles, and the
pullback sieve won’t show up at all.
In ordinary mathematics, a topology is a set of sets. The natural way to
represent this in types is as a type indexed by another type, which yields our
definition of topology, or rather of a site: a category equipped with a
topology.
Where Cover hom a is the type of covering families of a (typically,
Cover hom a is simply an enum of names), and Gen hom c is the type of elements of
the covering family c (which we think of as generating a covering sieve, hence
the name).
Sheaves on a site
Now sheaves are given by the following type class:
(I’ve cheated a little and assumed that the underlying category is Cartesian; we
can get rid of this hypothesis by replacing p (k × b) with the equivalent, but
considerably more heavyweight, PFun (Y x) p b)
This definition includes one trick that I haven’t described yet: with a cover
c :: Cover hom a instead of gluing only at type p a, we need to be able to glue
at type p b for any arrow f :: hom b a. This is how we avoid having to talk
about a pullback sieve. And this also seems to be why generators don’t need to
be actual arrows.
To elucidate this definition, let’s see how to instantiate it to Expr1
To show a bigger example, one that makes use of the x parameter in p (x × b)
(so far we’ve simply ignored x, since it’s always been equal to Bool), let’s
extend the arithmetic expressions with a sum type:
In order to be able to pattern match on sums in the category of sheaves, we will
have to add a cover for TSum. As the type of Case suggests, we will use the
x parameter to pass the value contained in Left or Right.
This is equivalent to saying that sheaves for SumExpr have two gluing
functions, glueIfThenElse and glueCase, such that in glueCase the Left
alternative is passed an a and the Right alternative is passed a b, like
we expect of a case expression.
Now, all instances from the previous section can be written in this abstract
style. Except the instance for the Yoneda embedding. In particular, if you add a
covering family for an object which isn’t a colimit in the base category, then
the Yoneda embedding won’t yield sheaves. If you want to look this up,
topologies where the Yoneda embedding only yields sheaves are called
subcanonical.
Further reading and final thoughts
If you want to see the actual instances for the abstract definition of sheaves,
you’ll find them in this file. In there the site is actually
concrete, but the instances are written as if it were abstract.
For those who want to read even more, I wrote some other thoughts on the project
on Bluesky which you may enjoy. If you are type-theory inclined, you
will probably enjoy Pierre-Marie Pédrot’s Pursuing Shtuck, it helped
me a lot with figuring these things out (it left quite direct a mark on the
project – for instance I lifted the definition of the sheafification functor
directly from there).
When I started trying to implement sheaves I didn’t know whether it would work.
Sometimes it pays to be stubborn enough. But also, implementing a project like
this lets you confront the finer details. Here’s one: in my definition of
Expr there is no fixed point. Recursive functions like fact and fib
simply compile to infinite Expr trees (which is fine as long as you keep
Expr lazy enough). And the truth is: I don’t know how to add fixed
points in a way that could be lifted to sheaves (via a sheaf condition or
otherwise). It might not be possible at all (if you know something about that,
get in touch!). Anyway, now, at least, I know what I don’t know.
[2026-06-22] Many thanks to Sjoerd Visscher who spotted an inexcusable amount of typos in
this post as I first published it.
We can, conversely, derive glue from glueIfThenElse using the fact
that a pair of p i is isomorphic to a function Bool -> p i. But this
requires singleton types to deal with the dependent quantification of the
cover c. To avoid obscuring the presentation, I’m not showing the converse
direction in this already-too-long blog post.↩
In the previous post, we learned how to get started with managing and building a Haskell project with Nix. In this post, we learn how to easily create statically-linked executables for Haskell projects with Nix.
I recommend going through the previous post, because we are going to start off from where we left last time (ignoring the bonus sections). This is how our project’s directory tree looks at this point:
Main.hs is the default generated main file that prints “Hello, Haskell!�. ftr.cabal is the default generated Cabal file. sources.(json|nix) are generated by Niv to pin Nixpkgs to a particular revision. nixpkgs.nix provides the nixpkgs that we use for building tools and dependencies. package.nix and shell.nix build the package and manage the Nix shell respectively. We are not going to touch any of these files in this post. Let’s get started.
A static build is an executable that is statically-linked against all the libraries it depends on. This is in contrast to a dynamically-linked executable, which contains references to the libraries it depends on, and those libraries are loaded and linked when the executable runs. While dynamic linking has its benefits, the main advantage of static linking is that the executable can be shipped by itself, without needing to ship or install dependency libraries. This makes it quite attractive for deploying backend services. You download and deploy that one binary executable file and you are done! No need to care about installing and maintaining its dependencies.
Many compilers support static builds—Go and Rust being two. Haskell compiler GHC also supports it, but not out-of-the-box. To statically link a Haskell executable, we need to configure GHC itself, and then configure the executable build as well. We also need to configure GHC to link with musl libc. That’s where Nix helps us by smoothing out the process1.
As mentioned, first we need a GHC configured to do static builds. We create a nixpkgs derivation, separate from nixpkgs.nix, that contains the custom configured GHC.
Let’s go over it piece-by-piece. First, we take the arch and ghcVersion parameters, letting us build the package for different architectures (X86-64 and AArch64), and for different GHC versions. We default the ghcVersion to the default GHC in nixpkgs.
The derivation is same as nixpkgs.nix, except we add some overlays. The first overlay adds the custom configured GHC for static builds. We enable certain configurations for that purpose:
enableRelocatedStaticLibs = true
Configures GHC runtime system and core packages to be built with position independent code so that they can be loaded for template Haskell.
enableShared = false
Disables building dynamically-linkable libraries, so they are built only as static archives.
enableDwarf = false
Disables DWARF-based stack traces, because it is unavailable on musl targets.
enableProfiledLibs = false
Disables building profiling enabled libraries.
enableDocs = false
Disables generation of documentation.
enableNativeBignum = true
Makes GHC use pure-Haskell based native bignum backend ghc-bignum instead of GMP, so that the package executables it creates are GPL-free. You may remove this setting if you are okay with GPL executables.
The buildHaskellPackages related lines set the custom GHC as the compiler for Haskell-based tools used in Nix2.
The second overlay makes cabal2nix—the tool used to convert .cabal files into Nix derivations—use the custom GHC. The third overlay disables documentation generation, testing, and profiling of all Haskell libraries built with the custom GHC. We do this to save the build time, assuming that static builds are for release only, and the docs, tests, and profiling are done using a normal GHC.
Building this custom GHC may take anywhere from several minutes to several hours depending on the build machine configuration34. But this is a one-time price to pay, as long as we keep the GHC build around. Next, we configure our package to be built as a statically-linked executable.
package-static.nix also takes arch and ghcVersion as parameters, and passes them to nix/nixpkgs-static-ghc.nix to create the nixpkgs with the custom GHC as described above. This give us pkgsOrig, from which we get the pkgsMusl version. pkgsMusl is same nixpkgs, except every executable in it links to musl libc. We capture this as pkgs, and use it to build our Haskell package.
When linking the executable, we need to link it against static version of all the dependency libraries it depends on. That’s what nix/static-deps.nix file provides us. We’ll look at it in the next section, but for now, we see that it gives us the libffi, zlib, and numactl libraries5.
Finally, we get to the package configuration. It starts the same as package.nix, using cabal2nix to connect the Haskell project to Nix, but then, we provide a list of custom configurations. We disable Haddock docs, hyperlinked source docs, coverage tests, profiling, and shared library build. We enable static executable build and dead code elimination. Then we configure cabal to run builds with multithreading, and add lld to its list of build tools.
Configures GHC to use lld as the linker, which is much faster than the default linker. You can omit these lines to use the default linker. Or you can replace all metions of lld with mold to use the Mold linker, which may be even faster depending on your project.
Enables reductions in binary size by removing dead code6.
--extra-lib-dirs=...
These lines allow GHC to link the output executable against the static version of the mentioned dependency libraries.
Finally, the last function in the pipeline uses UPX to compress the output executable. This generally results in a large reduction in the binary size7.
Now we can actually build the statically-linked exe:
The first and second line above build the exe for the X86-64 and AArch64 architectures with the default GHC version. The third line specifies a different GHC version to build with. Here is the cleaned-up output log for the first command:
Output log
$ nix-build --argstr arch x86_64 package-static.nix
these 2 derivations will be built:
/nix/store/42a291bq7ydvkdy3fdsyj82axrfsi6sy-ftr-0.1.0.0.drv
/nix/store/2c2l50la8291q0jrqlc23bybaxwip8y2-ftr-0.1.0.0-compressed.drv
building '/nix/store/42a291bq7ydvkdy3fdsyj82axrfsi6sy-ftr-0.1.0.0.drv' on 'ssh-ng://builder@linux-builder'...
copying 1 paths...
copying path '/nix/store/l9ls307kzxby72hqj4yl7ri7m8s3b3fk-source' to 'ssh-ng://builder@linux-builder'...
building '/nix/store/42a291bq7ydvkdy3fdsyj82axrfsi6sy-ftr-0.1.0.0.drv'...
Running phase: setupCompilerEnvironmentPhase
Build with /nix/store/717lxds14ra0ndbnin2qhdhh91d3b69g-ghc-musl-native-bignum-9.10.3.
Running phase: unpackPhase
unpacking source archive /nix/store/l9ls307kzxby72hqj4yl7ri7m8s3b3fk-source
source root is source
Running phase: patchPhase
Running phase: compileBuildDriverPhase
setupCompileFlags: -package-db=/nix/var/nix/b/10kwxdphxvyy519y831ryji7fn/b/tmp.EPOEKNjT6Z/setup-package.conf.d -threaded
[1 of 2] Compiling Main ( /nix/store/4mdp8nhyfddh7bllbi7xszz7k9955n79-Setup.hs, /nix/var/nix/b/10kwxdphxvyy519y831ryji7fn/b/tmp.EPOEKNjT6Z/Main.o )
[2 of 2] Linking Setup
Running phase: updateAutotoolsGnuConfigScriptsPhase
Running phase: configurePhase
configureFlags: --verbose --prefix=/nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0 --libdir=$prefix/lib/$compiler/lib --libsubdir=$abi/$libname --with-gcc=gcc --package-db=/nix/var/nix/b/10kwxdphxvyy519y831ryji7fn/b/tmp.EPOEKNjT6Z/package.conf.d --ghc-option=-j4 --ghc-option=+RTS --ghc-option=-A64M --ghc-option=-RTS --disable-library-profiling --disable-profiling --disable-shared --disable-coverage --enable-static --disable-executable-dynamic --disable-tests --disable-benchmarks --enable-library-vanilla --disable-library-for-ghci --enable-split-sections --enable-library-stripping --enable-executable-stripping -O2 --ghc-option=-fPIC --ghc-option=-split-sections --ghc-option=-optl-fuse-ld=lld --ld-option=-fuse-ld=lld --ld-option=-Wl,--gc-sections,--build-id,--icf=all --with-ld=ld.lld --ghc-option=-optl=-static --extra-lib-dirs=/nix/store/yi771fg1dfj1bg618vv5flmisy8zw3hm-libffi-3.5.2/lib --extra-lib-dirs=/nix/store/jk77s356gjn68dcrzpz1m7m5amzxmkw8-zlib-1.3.2-static/lib --extra-lib-dirs=/nix/store/044b10glmg0f3yyijmrwrgv5lsys6x6n-numactl-2.0.18/lib --extra-lib-dirs=/nix/store/m1j2f9b1h6pbq1mq5ibnw4cpp60w5dfi-libffi-3.5.2/lib --extra-include-dirs=/nix/store/j9c1ifaa7vph3zxfbzb55y1frm0vp4xm-musl-iconv-1.2.5/include --extra-lib-dirs=/nix/store/lrrmafbkrpa4f3wxfz6a3sd3dv6xgp7n-numactl-2.0.18/lib
[snip]
Running phase: buildPhase
Preprocessing executable 'ftr' for ftr-0.1.0.0...
Building executable 'ftr' for ftr-0.1.0.0...
[1 of 1] Compiling Main ( app/Main.hs, dist/build/ftr/ftr-tmp/Main.o )
[2 of 2] Linking dist/build/ftr/ftr
Running phase: haddockPhase
Running phase: installPhase
Installing executable ftr in /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0/bin
Warning: The directory
/nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0/bin is not in the
system search path.
Running phase: fixupPhase
shrinking RPATHs of ELF executables and libraries in /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0
shrinking /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0/bin/ftr
patchelf: cannot find section '.dynamic'. The input file is most likely statically linked
checking for references to /nix/var/nix/b/10kwxdphxvyy519y831ryji7fn/b/ in /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0...
patchelf: cannot find section '.dynamic'. The input file is most likely statically linked
patching script interpreter paths in /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0
stripping (with command strip and flags -S -p) in /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0/bin
copying 1 paths...
copying path '/nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0' from 'ssh-ng://builder@linux-builder'...
building '/nix/store/2c2l50la8291q0jrqlc23bybaxwip8y2-ftr-0.1.0.0-compressed.drv' on 'ssh-ng://builder@linux-builder'...
copying 0 paths...
building '/nix/store/2c2l50la8291q0jrqlc23bybaxwip8y2-ftr-0.1.0.0-compressed.drv'...
Running phase: unpackPhase
unpacking source archive /nix/store/pb2zay1k8b0vifhx7ghd5j6lbncq4b66-ftr-0.1.0.0
source root is ftr-0.1.0.0
Running phase: patchPhase
Running phase: updateAutotoolsGnuConfigScriptsPhase
Running phase: configurePhase
no configure script, doing nothing
Running phase: buildPhase
no Makefile or custom buildPhase, doing nothing
Running phase: installPhase
Ultimate Packer for eXecutables
Copyright (C) 1996 - 2026
UPX 5.1.1 Markus Oberhumer, Laszlo Molnar & John Reiser Mar 5th 2026
File size Ratio Format Name
-------------------- ------ ----------- -----------
1356096 -> 525804 38.77% linux/amd64 ftr bin/ftr [linux/amd64, LZMA/1]
Packed 1 file.
Running phase: fixupPhase
shrinking RPATHs of ELF executables and libraries in /nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed
shrinking /nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed/bin/ftr
patchelf: no section headers. The input file is probably a statically linked, self-decompressing binary
checking for references to /nix/var/nix/b/19b7g2frvcvani3cnj61lsb4fq/b/ in /nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed...
patchelf: no section headers. The input file is probably a statically linked, self-decompressing binary
patching script interpreter paths in /nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed
stripping (with command strip and flags -S -p) in /nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed/bin
copying 1 paths...
copying path '/nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed' from 'ssh-ng://builder@linux-builder'...
/nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed
The output log mentions:
patchelf: cannot find section ‘.dynamic’. The input file is most likely statically linked
We can also verify for ourselves:
$ file /nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed/bin/ftr
/nix/store/j8gg1x3vrlb5dc1mh149ys0nih9fvmwk-ftr-0.1.0.0-compressed/bin/ftr: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), BuildID[sha1]=df53df80d301b4bba2a7634a4169c6291d64ea72, statically linked, no section header
Dynamically-linked Haskell builds contain references to their dependency libraries and GHC that was used to build it. If you use direnv or install a dynamically-linked executable, it creates Nix GC roots for the libraries and GHC, preventing them from being garbage-collected by Nix. But statically-linked builds have no references to anything, as intended. So we need to create GC roots by ourselves to the libraries and the GHC toolchain. This is even more important because building the custom GHC may be an extremely time-consuming affair.
First, we list all dependencies in a separate file:
This file lists the dependency libraries and the GHC toolchain. Notice how we override each library’s config to make it statically-linkable. I’ve included some additional libraries here (gmp6 and ncurses) that are generally used by Haskell projects, but we don’t use them in this project. You may have to add more of such libraries depending on your project’s dependencies.
We already saw how we use this file in package-static.nix. Now, we use it to create Nix GC roots:
package-static-deps.nix simply gathers all dependencies from nix/static-deps.nix and creates a directory with symlinks to them. This brings us to the finale.
One more thing static builds are great for: wrapping them into Docker images. Since they are much smaller than dynamically-linked executables and their dependencies combined, they are better to package as Docker images. Here’s how we do it:
This image also shows how to package extra Nix packages in images, setting up a non-root user to run the executable, and setting up user-owned directories to expose as volumes. We can build the image by running:
This post shows how to configure GHC and Haskell projects to build statically-linked executables that are fully portable and independent. If your Haskell project has any complex requirements, such as custom dependency versions, patched dependencies, custom non-Haskell dependencies etc., this setup may not scale. In such case you can either grow this setup by learning Nix in more depth with the help of the official Haskell with Nix docs and this great tutorial, or switch to using a framework like haskell.nix or haskell-flake. For dealing with complex static builds, static-haskell-nix project may be of help.
If you have any questions or comments, please leave a comment below. If you liked this post, please share it. Thanks for reading!
This is the first part of a miniseries on this year’s Symposium on Principles of Programming Languages, a.k.a. POPL 2026, hosted by Jessica Foster.
In this episode we talk about: symbolic execution monads, what a lazy linear core in Haskell might have in common with Rust, hyperfunctions, the hallway track, and how to deal with rejection.
This post presents a little epic to insert static checks in Haskell’s Diff package using Liquid Haskell (LH).1
Static or compile-time checks are helpful to confirm formerly implicit assumptions in the implementation,
providing an additional layer of assurance.
Making illegal states unrepresentable at an affordable cognitive cost is a staple of statically typed functional programming.
Endeavors like Dependent Haskell and Liquid Haskell delve into this aspect.
A distinctive feature of LH is that it works on top of regular Haskell code,
meaning that the program can still be compiled after disabling it,
thus making it possible to enforce properties without changing the source code.
In what follows I’ll give you a glimpse of how the Liquid Haskell approach feels in practice and how far it can go.
Liquid Haskell was created by the UCSD Programming Systems group
and these days is mainly maintained and further improved by my colleague Facundo Domínguez.
Applying Liquid Haskell to strengthen libraries has precedent in the Haskell ecosystem,
and it was in this spirit that Facundo suggested this project as we were pondering an attempt to statically check our in-house Ormolu,
of which Diff is a transitive dependency and a more suitable commitment given the engineering time I could bestow upon it.2
Diff will never be the same
The Diff package is a small and (relatively) self-contained library implementing the Myers diff algorithm.
As a provider of basic functionality in the Haskell ecosystem,
adding formal guarantees to it is of intrinsic value to the community.
From the get-go, my objective was adding static checks to strengthen this library
in a contribution guided by two opposing desiderata:
Minimize source changes
Maximize checked invariants
While the first is about testing how (non-)intrusive Liquid Haskell can be,
the second is about its expressiveness.
To put it bluntly, the ideal LH would be able to statically check all the existing invariants
of an unsuspecting library using nothing more than specification annotations.
Reality is not that kind, forcing me to compromise on both objectives,
but I kept this mindset to help me see how close LH is to this ideal.
My first milestone was filling the mind gap between the Diff implementation and the referenced paper’s algorithm,
through an in-depth study of the library,
resulting in documentation contributions highlighting the most salient invariants (pre- and post-conditions) and assumptions.3
In general, it is by a careful threading of logic that a program is built into existence;
the problem (and the source of well engineered solutions) is that the critical aspects of it lie within a theory in its writer’s mind,
which tends to be lost across iterations, updates, refactors and people moving on.
Both documentation and specification cannot completely solve this problem,
but they can help.
For example, I added a post-condition to this function haddock
dataPolyDiffab=Firsta|Secondb|Bothab-- | Like 'getGroupedDiff' but accepts a custom equality predicate.---- Postcondition: the output list is guaranteed to be /chunked/. i.e. no two adjacent-- elements share the same constructor.getGroupedDiffBy::(a->b->Bool)->[a]->[b]->[PolyDiff[a][b]]
making the expected form of its output explicit.
This allows a reader to get an immediate notion of what the implementation is supposed to accomplish in order to satisfy the caller’s expectations.
Similarly, data types often carry more meaning than what they actually encode,
in which case documenting the implicit assumptions can help understand their intended use.
-- | Line Range: start, end and contents.---- The following invariants hold:---- > snd lrNumbers >= fst lrNumbers-- > snd lrNumbers - fst lrNumbers + 1 == length lrContents---- which imply @lrContents@ cannot be empty.dataLineRange=LineRange{lrNumbers::(LineNo,LineNo),lrContents::[String]}
These haddocks are inspired by the kind of properties that LH can express.
Nevertheless, their value doesn’t depend on providing static checks
as they already save us from some arduous code path diving.
Wouldn’t it be wonderful if the compiler could take those haddocks to heart?
In a sense that’s what LH is about!
Engineering the static checks took me into a tight feedback loop between the documentation process,
coming up with refactorings4 to make the code easier to check (which always implied easier to explain!)
and the writing of LH specifications matching the documented invariants.
This approach is in close sympathy with the doc it like it’s hot philosophy.
From dry code to liquid types
After installing LH, compilation failed due to new shiny errors,
even though I hadn’t written a single LH specification yet.
This is because LH inspects the bodies of all function definitions out of the box to prove that
Existing specifications are fulfilled
Recursive functions terminate
The first condition is not limited to local specifications;
LH comes bundled with specifications for many boot package functions.
For instance, many of Prelude’s partial functions are refined this way to be total,
so LH tries to prove that all their uses are safe.
One prominent example is head, which was the only failure of the first condition in Diff:
it was not certain that the list passed to head in its ses function is always non-empty,
which can be found to be true from the algorithm specification
and by following the composition of the involved processes.
LH tries to build this knowledge from specifications, in the form of refinement types, found along the call stack.
Such specifications are introduced using a special comment syntax {-@ ... @-}
whose contents are processed to generate a set of constraints for an external SMT solver to verify.
This allows us to mechanically check function specifications, formed out of pre- and post-conditions,
and data invariants expressed as simple logical predicates at compile time.
In what follows I’ll show some examples of LH specification annotations,
but in most cases I won’t be explaining their syntax or fundamentals,
trusting that their meaning within the general argument can be gathered from context.
For further details please look at the spec reference documentation.
The same comment syntax is also used to set LH directives,
like the ignore annotation I used to skip checks in the body of the offending ses function.
{-@ ignore ses @-}ses::(a->b->Bool)->[a]->[b]->[DI]seseqasbs=path.head.dropWhile(\dl->poidl/=lena||pojdl/=lenb).concat.iterate(dstepcd).(:[]).addsnakecd$DL{poi=0,poj=0,path=[]}wherecd=canDiageqasbslenalenblena=lengthas;lenb=lengthbs
Turning now to the second condition:
To prove termination of a recursive function, LH needs to be told of a size reduced towards a lower bound at each recursive call.
This is called a termination metric.
Some recursive functions might be proved terminating without intervention, because when no explicit metric is given LH follows a simple heuristic:
it checks for the first (non-function) argument with an associated size metric to be strictly decreasing and non-negative at each recursive call.
LH has definitions of associated size metric for lists (their length) and integer values,
which are considered metrics themselves when non-negative.
Metrics get interesting when we have mutually recursive functions,
as is the case for doPrefix and doSuffix,
a pair of local functions whose job is to chop common lines of input to create the context windows that make a diff’s hunks.
I introduced a lexicographic metric,
annotated with the syntax / [metric1, metric2, ...] at the end of a function refinement,
to prove their termination:
Using this metric LH checks that either the input hunk (a list of diff elements) length is reduced after each recursive call,
as it would do by its default heuristic,
or considers a call to doPrefix (0) from doSuffix (1) to be a strict reduction.
This second fallback metric is needed because of the third equation of doSuffix (second guard),
where doPrefix is called with a list of equal length.
Apart from this case, each (mutually) recursive call is done on the tail of the input and thus strictly decreasing.
Here I’ve presented instances of two general strategies to handle LH errors:
Fight: Fix the failing termination checks by introducing metrics
and offending functions calls by adding specifications.
Flight: Disable checks by using an escape hatch, e.g. the {-@ lazy myRecursiveFunction @-} annotation to circumvent termination checking,
the {-@ ignore myOffendingFunction @-} to disable all checks within a function’s body
or the {-@ assume myFunction :: ... spec ... @-} to set a function specification as true without verification.
A priori it’s desirable to minimize the use of escape hatches,
but they’re also tools to prioritize static checking efforts.
Invariant static checking
One thing that made Diff particularly suitable for this effort is that a detailed specification of it existed in the form of a research paper.
Indeed, my first documentation contribution was making their connection explicit throughout.
The Myers diff algorithm can be summarized as a breadth-first search for the shortest path across a bidimensional edit grid to an endpoint,5
the latter representing the complete transformation of one input to the other.
The algorithm is in fact tersely expressed in the ses definition presented before;
its name stands for “smallest edit script”,
which is one of the output characterizations of the diff algorithm.
What I found is that the idea of a wave front is the link between this implementation and the original algorithm.
This statement is now supported by a static check showing that a wave front is transformed
as the algorithm prescribes for its inner loop.
A wave front is defined as a list of nodes at the same depth,
i.e. the edit trace length,
which is iterated upon by the dstep function to return nodes one step deeper.
This function is a direct implementation of the extension procedure used by the algorithm at each search step.
Furthermore, the paper proves a pair of lemmas that result in a specific configuration of the node list after each iteration,
which is related to the diagonals on the edit grid and checked by a wfDiags predicate that I wrote to specify it.
The details of this condition aren’t essential here:
while the paper leverages it to introduce a space optimization,
the Haskell implementation doesn’t depend on it,
but the configuration is preserved nonetheless.
I encoded the fixed depth of nodes and their diagonal configuration using refinement type aliases to obtain a wave front specification.
-- | A node representing the tip of a path in the edit grid.dataDL=DL{...,path::[DI]-- ^ The edit trace accumulated so far}deriving(Show,Eq)-- A node at a fixed edit trace length (depth).{-@ type DLN D = { x : DL | len (path x) = D } @-}-- | This function is used only in LH specs to check if-- diagonal configuration holds for a node list.wfDiags::[DL]->BoolwfDiags=...-- All nodes in a wave front are at the same depth,-- and satisfy the diagonal configuration.{-@ type WaveFront D = {xs : [DLN D] | wfDiags xs} @-}
With this encoding, and a phantom parameter carrying the current depth,
I specified dstep (called from ses) to match the algorithm behavior
(which also includes the node list growing by one).
{-@
dstep
:: (Nat -> Nat -> Bool)
-> d : Nat
-> {nodes : WaveFront d | len nodes > 0}
-> {v : WaveFront (d + 1) | len v = len nodes + 1}
@-}dstep::(Int->Int->Bool)-- ^ Check for node coordinates producing a free edge->Int-- ^ The current depth; used for the static check of the wave front invariant->[DL]-- ^ A non-empty wave front of nodes at edit distance D->[DL]-- ^ A non-empty wave front of nodes at edit distance D+1
Refinement type aliases become statically checked invariants when used in a function specification,
and are verified to hold at each call site.
As a second example, let’s see the invariants of a Hunk,
expressed again using refinement type aliases.
-- A valid list diff is such that any `Both` value has arguments of equal length.{-@ type ValidListDiff a b = { d : PolyDiff [a] [b] | validListDiff d }@-}-- | True when, for a 'Both' value, both sides have the same length.-- 'First' and 'Second' trivially satisfy this.-- Introduced for LH specifications.validListDiff::PolyDiff[a][b]->BoolvalidListDiff(Bothxsys)=lengthxs==lengthysvalidListDiff_=True-- | True if the list does not contain adjacent 'PolyDiff's with the same constructor.noStuttering::[PolyDiffab]->BoolnoStuttering=...-- | A 'Hunk' is a list of adjacent 'Diff's.---- No two consecutive elements in a 'Hunk' are both applications-- of 'First', 'Second', or 'Both', i.e. the list does not stutter-- on 'Diff' constructors.typeHunkc=[Diff[c]]{-@ type Hunk c = { h : [ValidListDiff c c] | noStuttering h} @-}
The interesting part here is the check for the noStuttering invariant in the specification of the main Hunk producing function.
For brevity’s sake I won’t show this function, but let’s see what came to be of the specification of the previously presented doPrefix,
that is part of it,
for the check to pass.
{-@ doPrefix :: h : Hunk c
-> {v : [ValidListDiff c c] | noFFSS v
&& ... other auxiliary post-conditions ... } / [len h, 0] @-}
Essentially, this function traverses a given Hunk and chops and splits Both elements to a context size argument.
After doing so the Hunk “stutters” on such elements,
so it stops being a Hunk in the refined sense,
even though the Haskell types match.
Note the regular type synonym and the refinement type synonym don’t coalesce:
At the Haskell level the synonym is just a renaming,
but in the specification it is shadowed by the refinement synonym (thus enforcing its invariants).
The noFFSS helper characterizes the resulting list;
it is like noStuttering, but just for the other PolyDiff constructors: First and Second.
Other auxiliary post-conditions (not shown) stating that input and output lists shared head constructors were also necessary for this check.
The verification of these and other invariants followed a similar outline:
Identify and document the invariant
Encode it in refinements
Write the specifications
Please the compiler
Pleasing the compiler after adding a new specification was trickier for me than the usual Haskell type error propagation and fix workflow.
Figuring out exactly what LH is aware of when checking a specification requires an intuition of how it builds a context;
then it’s a matter of making the missing information available.
For instance,
the last step to get back a Hunk after the doPrefix-doSuffix operation required passing a lemma within a local dead binding for the specification to be verified.
{-@ assume lemmaReverseNoStuttering
:: xs:_ -> { noStuttering (reverse xs) = noStuttering xs } @-}lemmaReverseNoStuttering::Hunkc->()lemmaReverseNoStuttering_=()-- | Split a 'Diff' list at consecutive 'Both'-'Both' boundaries.{-@ splitBothBoth :: {ds:[ValidListDiff c c] | noFFSS ds} -> [Hunk c] @-}splitBothBoth::[Diff[c]]->[Hunkc]splitBothBoth=go[]where{-@ go
:: g:Hunk c
-> {xs : [ValidListDiff c c] | noFFSS xs && not (headAlike g xs) }
-> [Hunk c] / [len xs]
@-}go::Hunkc->[Diff[c]]->[Hunkc]gog(x@Both{}:y@Both{}:xs)=reverse(x:g):go[](y:xs)wherelemma=lemmaReverseNoStuttering(x:g)gog(x:xs)=go(x:g)xsgog[]=[reverseg]wherelemma=lemmaReverseNoStutteringg
This binding ultimately gets optimized away by GHC, but LH requires it to satisfy the static checks.
LH didn’t have a means to know that reverse preserves the noStuttering of a PolyDiff list,
so I provided it.
I decided to assume the lemma above on the rationale that its validity is straight-forward,
while its proof would probably not be,
making the disease not worth the medicine.
Lifting a dam
After this work I’m flooded with many thoughts and feelings about LH from the user perspective,
but also ideas for important future developments.
One particular source of difficulty I found is differentiating between the existing means of lifting a Haskell function into the logic:
reflect, inline, measure and define.
By default, Haskell functions like wfDiag cannot be used in the refinement type predicates.
They have to be accompanied by an annotation that indicates how to make them available in the predicates,
which I omitted in my examples for the sake of argument.
Existing documentation does a good job at explaining their requirements and purpose.
Nevertheless, subtle differences in constraint generation and logical expression unfolding aren’t documented,
and these details matter when choosing between them in certain cases.
Addressing this could lead to unifying or deprecating some functionality,
but at least specifying them at a finer grain and adding some use case examples could go a long way.
A more salient difficulty are the error messages.
They can be baffling,
featuring not very human friendly variable names spread across enormous lists of bindings forming their “context”.
Skimming through this context is a skill that I would love to deprecate.
Looking first at the “inferred type” and the “required type” part at the start of the message is a useful technique,
which can provide a lead to the source of the problem.
I find refinement types appealing because they are powerful yet non-sophisticated enough to be intuitive.
Nevertheless, getting a function specification checked can become intricate,
requiring additional proving machinery like
function definitions exclusively intended for refinement predicates,
lemmas in dead bindings to pass additional constraints
or even heavy refactoring.
However,
I think the upfront cost of entry can be easily balanced out by using the escape hatches to focus the effort investment.
In the Diff package, for instance,
some low hanging fruit could be picked right away after disabling the checks on error triggering functions,
e.g. refining integer values to naturals or enforcing clear-cut relations between record fields,
adding immediate value without additional machinery.
A drawback is that polymorphism seems at odds with the simplicity of refinements:
the more we want to specify about a value or function, the more we narrow its type.
That said,
there seems to be a correlation between code complexity and LH verification complexity that is worth investigating further:
changes that simplified the verification of an invariant tended to benefit the code quality independently of it.
Choosing between fight or flight for a given invariant is ultimately about balancing safety gains with added complexity,
and in my experience the code structure is what tips the scale:
it determined both the refactorings I needed and the checks I had to forgo.
My guess is that the whole equation changes when refinement types are a first class consideration during design.
Clearing up the waters
Hopefully this little epic amounts to a useful case study that,
by showing what using LH is like today,
encourages you to add static checks to an existing codebase
or experiment in your next project with LH in your toolbox,
and the techniques I’ve shared help prioritize the approach.
I discussed some of LH pain points to offer a balanced view and propose further DX improvements.
There’s much to be done, but it’s steadily getting there.
My opinion is that Liquid Haskell is a viable option today to add formal guarantees to an unsuspecting codebase at a reasonable cost,
as long as the palette of shapes and extent this can take is kept in mind during design.
Know that you’re welcome to contribute to LH development and that we’re ready to help strengthen your codebase.
Just reach out!
Finally, I would like to express my gratitude to Aleksandr Vershilov, Arnaud Spiwack and Christopher Harrison for reviewing this text,
and notably to Facundo Domínguez whose close collaboration was instrumental to streamline this work.
At the time of writing, the static checks are about to be proposed for upstream integration. But they can be found in the Liquid Haskell test suite as well.↩
A nice perk of working at Tweag is being supported to do open source contributions during or in-between client projects.↩
The coordinates of a node in the edit grid represent the size of the prefix consumed from the first input and the size of the produced prefix of the other input, respectively. Thus, the endpoint has coordinates matching both input lengths. The grid’s most relevant feature is that, in addition to vertical and horizontal edges (corresponding to deletions and additions, respectively), there are “free” diagonal edges wherever both inputs have matching elements.↩
After retiring last July, the University Senate have approved my emeritus status. I'm grateful to Julian Bradfield for his work drafting the generous minute that accompanied the approval.
Special Minute
Professor Philip Wadler BSc, MSc, PhD, FRSE, FACM, FRS
Emeritus Professor of Theoretical Computer Science
We are pleased to nominate Professor Philip Wadler for the title of Emeritus Professor at the University of Edinburgh. Professor Wadler is a popular educator and has had an extensive career in both academia and industry, with seminal contributions to the field of computer science, particularly in the theory and practice of programming languages. Philip Wadler obtained a BSc with honours in mathematics from Stanford University in 1977, followed by a MSc and PhD in computer science in 1979 and 1984 from Carnegie-Mellon University. He took up a postdoc at Oxford University, and in 1987 he was appointed as a lecturer at the University of Glasgow. In 1996, Phil switched to industry, working at Bell Labs and Avaya Labs. He returned to academia in 2003, taking up the Chair of Theoretical Computer Science at the University of Edinburgh.
Professor Wadler’s research centres on the theory and practice of programming languages. He served as first editor of the Haskell report, and introduced what are arguably its two main innovations, type classes and monads. Haskell saw widespread use, and type classes and monads were adopted by a wide variety of other programming languages and proof assistants. He contributed to the design of the programming language Java, and introduced a model of it widely used by researchers. By influencing the design of popular programming languages, Phil has had a profound impact not only on programmers, but also on the users of the systems those programmers build. If you’ve used Facebook or X, Android or iPhone, you’ve run code that exploits concepts Phil pioneered.
Professor Wadler has published many seminal monographs and textbooks throughout his illustrious career. His contribution has been honoured in many ways. He served as chair of the ACM Special Interest Group on Programming Languages (SIGPLAN) from 2009–2012 and received its Distinguished Service Award in 2016. He was appointed a Fellow of the Royal Society of Edinburgh in 2005, a Fellow of the Association for Computing Machinery in 2007, and a Fellow of the Royal Society in 2022. He regularly delivers keynotes at both academic and developer conferences. In 2016, his sixtieth birthday was marked by a two-day Wadlerfest, and an accompanying festschrift published by Springer.
Phil is a passionate and popular teacher. On moving to Edinburgh in 2003, he introduced a first-year programming languages course based on Haskell and was shortlisted for the EUSA Teaching Award (Overall Best Performer) in 2009. His Honours courses on programming language theory have been among the most popular theoretical courses. Phil is widely known for theatrical performance and applies this talent outside academia, often performing stand- up comedy via Bright Club, and appeared in the Fringe via the Cabaret of Dangerous Ideas in 2024.
Since 2017, Phil has worked closely with industry, including consulting for IOG where he helped to design the smart contract system for its Cardano blockchain and applied formal methods to ensure its reliability. After retirement from Edinburgh, he plans to write a version of his online text for the proof assistant Agda updated to the proof assistant Lean. He will appear again this summer at the Fringe.
To conclude, Professor Philip Wadler's career is characterised by groundbreaking research, impactful teaching, and significant professional service. His work has shaped the landscape of programming languages and computer science education. Conferring the title of Emeritus Professor on Professor Wadler would honour his substantial contributions to the University of Edinburgh and the broader scientific community.
Thomas Piketty is at it again. He and his colleagues at the World Inequality Lab have produced a report outlining, with quantitative modelling, what a just world might look like and how to get there. A summary appears in the Guardian, and their full report is online.
Imagine a future in which everyone enjoys high levels of wellbeing; where 90% of the world’s population doubles their income but works half the hours we work today. A world in which the bottom half of humanity sees its share of global wealth rise from just 2% today to 30%; a world where we consume enough, but nobody over-consumes. And imagine achieving this on a planet that can comfortably sustain human life without its climate breaking down.
Against the bleak techno-authoritarian futures now being sold to us, a radical new vision for global progress in the 21st century feels urgently needed. ...
What would this transition deliver? At its heart is convergence between countries. Average per capita national income, today separated by a 16-fold gap between the poorest (€290 a month in sub-Saharan Africa) and richest (€4,590 in North America/Oceania) regions of the world, would rise towards a common level of about €5,000 a month in all countries by 2100.
But this convergence is not just monetary. Annual working hours per employed person would fall from roughly 2,100 to about 1,000, continuing the long shift towards shorter working time; while the share of global working hours devoted to education and health would rise from 11% to 43%. Women and men would converge on equal pay and on an equal share of economic and domestic labour.
All of this would unfold within a habitable climate. Thanks to sustainable convergence and fast decarbonisation, global heating would reach 1.8C, against more than 4C on current trends.
None of this will be possible without a deep contraction of inequality. The income scale between individuals would narrow to a ratio of one to five and the wealth scale to one to 10, prolonging what western and Nordic Europe achieved over the 20th century. The share of global wealth held by the poorest half of humanity would rise from 2% to 30%, while the share held by the billionaire class would fall from 6% to 0.05%.
TL;DR Build your Haskell projects 10-15% faster with this one simple trick!
(Spoiler: the simple trick is to wait for the next major cabal-install release.)
In previous work (paid for by the Sovereign Tech Fund) we
did a lot of heavy lifting to make a major architectural change to Cabal. That
work is now paying off with practical benefits. This post covers follow-on
architectural improvements to cabal-install which then enable us to eliminate
redundant work in the configure phase, yielding significant reductions in
build times.
The changes will be available to everyone in the next major cabal-install
release. For a large project like pandoc (including all of its dependencies)
we measure a 10% (std.dev. 0.6pp) reduction in wall clock time for a 16-way
parallel build with --semaphore. No user changes are needed to take advantage
of this improvement.
History: Cabal and cabal-install
The genesis: the Cabal specification
First, there was Cabal. Its design was laid out in A Common Architecture for Building Applications
and Tools. Fundamentally, it defines the notion of a package, with
each package being built and installed with the following sequence of commands:
Each package must be built in dependency order, with hc-pkg registering each
installed library into a package database.
Orchestrating the build of multiple packages
cabal-install was then born to plan and execute a build plan consisting of
many packages. With its solver, it determines a build plan, which is then
orchestrated by running the above sequence of commands for each package,
in dependency order.
There is however one architectural mismatch: for the solver to be able to
compute a build plan, it already needs a lot of information about the current
system:
What Haskell compiler are we using?
What system libraries are available (pkgconfig-depends)?
What build tools are available (build-tool-depends)?
This means that cabal-install already has in its hands most of the information
necessary for configuring a package; in particular it has already resolved all
the conditionals in every package description. We should thus be able to skip
most of the steps in the package’s ./Setup configure phase. However,
the command-line interface of ./Setup configure makes it practically
impossible to do so: passing a fully resolved dependency graph would require many
additions to the already bloated ConfigFlags datatype,
and a lot more data being serialised/deserialised.
Because of this limitation, cabal-install’s approach was to take its hard-won
build plan and convert it into ConfigFlags that specify exact dependency
versions and flag assignments. This amounts to passing ./Setup configure
an already fully constrained configuration; the configure step would then
re-probe the system, re-read package databases… only to re-discover exactly
what cabal-install already knew!
A new architecture for cabal-install
The paradigm shift proposed in our Sovereign Tech Fund proposal
is that cabal-install should be responsible for orchestrating the whole build
process instead of running the conceptually independent build systems provided by
each package. With cabal-install now in control, it can directly call Cabal
library functions, which in turn allows skipping steps in the configure phase
that waste time re-discovering information that cabal-install is already
aware of.
To implement such a change, we first needed to prepare the terrain: when invoking
an external executable such as the Setup executable – say via the
process library as Cabal uses – we can set the working
directory, environment variables and redirect input/output handles.
It was not possible to do this directly via the Cabal library, so we first
needed to add Cabal library support for setting the working directory
and for choosing logging handles. Once this was done,
it allowed us to refactor cabal-install to directly call Cabal library functions to build packages.
Performance impact
This architectural change provides a solid foundation for further improvements.
The two main time sinks in the Cabalconfigure phase were determined to be
(using a new --build-timings flag to cabal-install):
(~50% of configure time) Re-configuring the compiler program database.
The compiler and hc-pkg were already pre-configured, but other programs
such as haddock, ar, ld etc were re-configured anew for each package.
(~40% of configure time) Re-probing the installed package database, via hc-pkg dump.
While most of the time in builds is unsurprisingly spent… actually compiling
Haskell code [citation needed], the impact on full builds is still rather
significant. For example, when compiling aeson with -j1, we saw a reduction
in total build time of ~16.6% (std.dev. 1.9pp) in our benchmarks.
The fact that the configure phase is inherently serial also means that these
improvements have a notable impact when combined with the -jsem feature.
This is because the -jsem feature allows us to assign more capabilities to
the build phase. As per Amdahl’s law, this results in the
configure phase becoming more of a bottleneck. For example, when compiling
pandoc with cabal install pandoc -j16 --semaphore, we saw a reduction in
total build time of ~10% (std.dev. 0.6pp).
Further improvements
These improvements provide a small glimpse of what is possible after our changes
to cabal-install’s architecture. A more ambitious long-term goal would be for
cabal-install to manage a “giant build graph” on a finer granularity level
than whole Cabal components. For example, if package q depends only
on module P1 from package p, we could imagine starting to compile q after
compiling P1 but before we have finished compiling the rest of p. This
would unlock build-time reductions by increasing available parallelism,
and also enable more accurate progress and error reporting.
Today the 17 October 2019 I discussed a very remarkable fixed point theorem discovered by the Ukrainian mathematician Oleksandr Micholayovych Sharkovsky.
We recall that a periodic point of period for a function is a point such that . With this definition, a periodic point of period is also periodic of period for every which is a multiple of . If but for every from 1 to , we say that is the least period of .
Theorem 1. (Sharkovsky’s “little” theorem)Let be an interval and a continuous function. If has a point of least period 3, then it has points of arbitrary least period; in particular, it has a fixed point.
Note that no hypothesis is made on being open or closed, bounded or unbounded.
Our proof of Sharkovsky’s “little” theorem follows the one given in (Sternberg, 2010), and could even be given in a Calculus 1 course: the most advanced result will be the intermediate value theorem.
Lemma 1.Let be a compact interval of the real line and a continuous function. Suppose that for some compact interval it is . Then has a fixed point in .
Proof. Let and be the minimum and the maximum of in , respectively. As , it is and . Choose such that and . Then is nonpositive at and nonnegative at . By the intermediate value theorem applied to , must have a fixed point in the closed and bounded interval (possibly reduced to a single point) delimited by and , which is a subset of .
Lemma 2.In the hypotheses of Lemma 1, let be a closed and bounded interval contained in . Then there exists a closed and bounded subinterval of such that .
Proof. Let . We may suppose , otherwise the statement is trivial. Let be the largest such that . Two cases are possible.
There exists such that . Let be the smallest such , and let . Then surely , but if for some we had either or , then by the intermediate value theorem, for some  we would also have either or , against our choice of and .
for every . Let then be the largest such that , and let . Then for reasons similar to those of the previous point.
Proof of Sharkovsky’s “little” theorem. Let be such that , , and . Up to cycling between these three values and replacing with , we may suppose . Fix a positive integer : we will prove that there exists such that and for every .
Let and be the “left” and “right” side of the closed and bounded interval : then and by the intermediate value theorem. In particular, , and Lemma 1 immediately tells us that has a fixed point in . Also, , so also has a point of period 2 in , again by Lemma 1: call it . This point cannot be a fixed point, because then it would also belong to as , but which has period 3. As we can obviously take , we only need to consider the case .
By Lemma 2, there exists a closed and bounded subinterval of such that . In turn, as , there also exists a closed and bounded subinterval of such that , again by Lemma 2: but then, . By iterating the procedure, we find a sequence of closed and bounded intervals such that, for every , and .
We stop at and recall that : we are still in the situation of Lemma 2, with in the role of . So we choose as a closed and bounded subinterval not of , but of , such that . In turn, as , there exists a closed and bounded subinterval of such that . Following the chain of inclusions we obtain . By Lemma 1, has a fixed point in , which is a periodic point of period for .
Can the least period of for be smaller than ? No, it cannot, for the following reason. If has least period , then so has , and in addition is divisible by . But while for every . Consequently, if has least period , then . But this is impossible, because by construction as , while .
Theorem 1 is a special case of a much more general, and complex, result also due to Sharkovsky. Before stating it, we need to define a special ordering on positive integers.
Definition. The Sharkovsky ordering between positive integers is defined as follows:
Identify the number , with odd integer, with the pair .
Sort the pairs with in lexicographic order.
That is: first, list all the odd numbers larger than 1, in increasing order; then, all the doubles of the odd numbers larger than 1, in increasing order; then, all the quadruples of the odd numbers larger than 1, in increasing order; and so on.
For example, and
Set for every and .
That is: the powers of 2 follow, in the Sharkovskii ordering, any number which has an odd factor.
For example, .
Sort the pairs of the form —i.e., the powers of 2—in reverse order.
The set of positive integer with the Sharkowsky ordering has then the form:
Note that is a total ordering.
Theorem 2. (Sharkovsky’s “great” theorem)Let be an interval on the real line and let be a continuous function.
If has a point of least period , and , then has a point of least period . In particular, if has a periodic point, then it has a fixed point.
For every integer it is possible to choose and so that has a point of minimum period and no points of minimum period for any . In particular, there are functions whose only periodic points are fixed.
Bibliography:
Keith Burns and Boris Hasselblatt. The Sharkovsky theorem: A natural direct proof. The American Mathematical Monthly118(3) (2011), 229–244. doi:10.4169/amer.math.monthly.118.03.229
Robert L. Devaney, An Introduction to Chaotic Dynamical Systems, Second Edition, Westview Press 2003.
We talked to Fraser Tweedale. Fraser works at Red Hat, and is on the Haskell Security Response Team. We talked about security in the context of Haskell, both technical and organizational issues, and also the political issues involved. Fraser's work is both really important and not well-known in the Haskell ecosystem, so it was high time for him to come on the show.
I’ve also been experimenting with agent sandboxes lately. redoubtful is a work-in-progress sandbox that supports:
Linux-only sandboxes: I’m focusing on what Linux supports, specifically, rather than trying to support the lowest-common-denominator features that work cross platform.
Modular configuration profiles: See below.
Isolation using pasta and bwrap.
A shadow filesystem that looks like your home directory, so things like git worktree actually work correctly. You can also selectively mount existing parts of your filesystem in read-only or read-write mode.
Network port forwarding and filtering proxy server.
TODO: Proxy credential support.
But first, a warning: Nearly 100% of this code was written by coding agents, much of it by a local Qwen3.6 27B. I am, however, keeping a very close eye on the output—one of my goals here is to see just what a small agent like this can do. This is maybe only 80% as good as my handwritten code would be a similar point in a project.
And finally, this is an incomplete work-in-progress, and it has not been packaged nicely for anyone besides me yet.
Modular configuration “profiles”
One of the slightly novel parts of all this is the ability to define modular configuration. This allows us to invoke a sandbox with a specific set of credentials:
redoubtful run --uses pi --uses llama-server pi
Here, we’re running the pi.dev coding agent with a locally-served Qwen3.6 27B via llama-server. Qwen3.6 27B is a fantastic lightweight coding model, and it works very well with pi.dev’s minimalist prompt. And since we’re running in a sandbox, we don’t care that pi.dev provides no sandbox and no confirmation before acting.
To set up these two profiles, we first define a node profile:
# Standard Node setup. If you're using `nvm`, you'll need to fix the path_add# entry to point to the correct nvm version.## We might want some kind of plugin system to handle messy things like nvm.[profile.node]mounts=[{host="~/.npm-global"},{host="~/.local/share/nvm",access="rw"},]path_add=["~/.npm-global/bin","~/.local/share/nvm/v24.15.0/bin"]
Then let’s make Rust work:
# A Rust setup, with optional rustup and advisory support.[profile.rust]mounts=[{host="~/.rustup"},{host="~/.cargo"},# Cargo audit/deny support, which needs to take a lock to update the# advisory database.{host="~/.cargo/advisory-dbs/",access="rw"},]path_add=["~/.cargo/bin"]
And then basic git is easy—we just need enough config to read user.name and user.email:
# Things you will likely want for git.[profile.git]mounts=[{host="~/.gitconfig"}]
And then finally, we can set up pi itself:
# Profile for the pi coding agent. Run with:## redoubtful run -u pi pi[profile.pi]uses=["node","rust","git"]mounts=[{host="~/.pi",access="rw"}]
# Pass through llama-server connections.[profile.llama-server]forwards=[{host_port=8080}]proxies=[{host="127.0.0.1"}]
What’s left?
The biggest missing piece is teaching the proxy server how to inject real credentials into network connections. This isn’t a new idea. The goal is to provide access to things like GitHub without giving an agent actual credentials.
After that, it’s just packaging everything up nicely and writing some docs, so that other people (or agents) can easily configure it for different purposes.
I continue to be interested in late-2024-era edit completion, the “Fill in the Middle” (FIM) models. You know, what Copilot used to do, back before it started generating “mini diffs.” Why?
The new-school edit completion offered by Copilot and Zed’s Zeta2 actually slows me down. It overlays diffs on my buffer, which is visually disorienting at speed. And it proposes edits further from the current cursor, which take me longer to mentally process. Personally, the new style feels like hunt-and-peck. The older style felt like really fast touch typing.
Mind you, I’m a very specific sort of user. I want to know how my code works. I want my code to be clean. And I can read a half-page code completion in moments, thanks to way too many years of reading PRs.
Initial experiments
All experiments performed in Zed, which does less post-processing of the raw model output than some tools. All evaluations are purely subjective.
New-school models (generating diffs). Zeta2 is honestly pretty underwhelming right now. The completions are very generic. And Zeta2 seems to be bad about taking the context into account. It will complete a function, sure. But I’d swap Zeta2 for late 2024 Copilot in a heartbeat.
Old-school models (FIM, inserting at cursor). Let’s go down the list so far:
ggml-org/Qwen2.5-Coder-7B-Q8_0-GGUF:Q8_0: The classic, default choice. This isn’t terrible, and it gives more context-aware completions than Zeta2. But it’s generations old, and I want to know if anything is new and shiny.
mradermacher/Seed-Coder-8B-Base-i1-GGUF:Q6_K. This is the raw base that went into Zeta2, I think? It doesn’t seem to be useful in Zed, because the inserted text feels pretty raw. This might work better in a smarter harness. But I’m dropping it for now.
JetBrains/Mellum-4b-base-gguf:Q8_0. Downloaded, but not yet tested.
unsloth/Qwen3.6-35B-A3B-GGUF:IQ4_XS. This is unexpectedly good! Worth further experimentation.
Refining Qwen3.6 35B A3B: Changing order from PSM to SPM
Qwen typically uses FIM, “Fill in the Middle” completion. This uses 3 magic tokens:
/// Qwen FIM prefix marker.constPRE:&str="<|fim_prefix|>";/// Qwen FIM suffix marker.constSUF:&str="<|fim_suffix|>";/// Qwen FIM middle marker (model generates after this).constMID:&str="<|fim_middle|>";
We have two possible flavors. The original is “PSM” compeletion, “prefix, suffix, middle”:
{PRE}{prefix}{SUF}{suffix}{MID}
But since the prefix grows with each keystroke, we can’t cache the entire message. We could get much better caching with “SPM” order:
{SUF}{suffix}{PRE}{prefix}{MID}
Here, we can cache everything up to the final {MID} character, and resume generation with a longer prefix. Whooo, speed!
But Zed doesn’t support SPM completion, only PSM. So I fired up a copy of Claude Code (as one does), and asked, “Hey, write me a Rust proxy server (using my standard conventions) that intercepts /completion, and translates PSM to SPM please.”
Results: Extremely disappointing. SPM format confuses Qwen3.6 35B A3B pretty badly. But then I thought, “Hey, even if we’re running in /completion mode, this is still an instruction-tuned model. Can we prompt it?” One unscientific tweak later:
You are a code-completion tool. You receive input in
fim_suffix+fim_prefix+fim_middle order, and your job
is to generate what the user would be likely to type
next. When in doubt, keep it short. Think of this like
generating a diff in agentic coding mode. You're trying
to insert the right text to make a working program that
does what the user wants. If there's no obvious next
step, generate nothing.
{SUF}{suffix}{PRE}{prefix}{MID}
This is still pretty bad, but it’s better. You can tell it’s trying to be an SPM autocompleter, though it’s still the worst of the bunch.
Possible next steps:
What if we modify the proxy to transform /completion into a /chat/completions request, with a real prompt, real text inputs, and tool for insert_at_cursor(text)? Can we access more of the model’s intelligence?
Qwen3.6 35B A3B is small enough to fine-tune! We could look up file completion data sets, and try to create a LoRA adapter. We could even use something like tree-sitter to generate custom completion examples. Would that give us something useful?
I also notice that FIM-style models are notoriously bad at choosing a good stopping place. This can be fixed with a lot of regexes. But what if our fine-tuning data took care to demonstrate good stopping places?
About three months ago, I bought the Onyx BOOX 25.3” Mira Pro Color, an e-ink monitor for desktop use. I’ve used it as my primary monitor since, and I’ve had a lot of questions about it. This is my experience report, from the perspective of a working, still mostly typing, programmer.
This is not a sponsored post, and it is not a product review. I wrote a very similar post about the Daylight DC-1 last year.
Neovim in the morning sunlight.
As explained in last year’s post, the reason I persist with these monitors is because it makes me energetic and happy. Sunlight, direct or indirect, helps me stay clear and focused during my workday. I find spaces illuminated by natural light beautiful and inspiring.
I’m not going to recommend that you buy one of these devices. They’re expensive, about $2000, and the experience is quite different from LCD. Even if this looks cool, it seems to me very possible that most people would not like it in practice. With that said, I am happy with it, and I’ll probably keep investing in these tools as they get even better with time.
Spending a workday in the garden.
Using the Mira Pro as a primary monitor is a continuation of the experiments with my e-ink tablets and Termux as coding environments. But now, with far fewer compromises. I’m running my regular NixOS environment on my work laptop. No SSH and tmux needed, no Android terminal emulator to customize.
What I have done, though, is spent quite some time on making my system more suited for this monitor. The Mira Pro does not work well with dark themes. In fact, it only works well with high contrast light themes.
Luckily, I’m bent towards minimalism, so I already used near-monochrome themes, relying more on typographic syntax highlighting rather than coloring. I now have custom themes for Neovim, Zed, and Ghostty with a few vivid colors for things like selection, comments, and constants. Otherwise it’s largely black on white.
It’s trickier with other applications. In Firefox, I’ve started using the high contrast setting. That works pretty much like an inverse of DarkReader. I now run Spotify in the browser in order to avoid its dark theme.
The monitor has a clunky menu system with which you can change rendering modes; things like contrast and speed. I found an open-source reverse-engineered NodeJS package that I use with Hyprland keybindings to easily change rendering modes and manually refresh. No need for the built-in menu.
In practice I use two modes:
Reading:
This mode renders colors most vividly and text sharply, but typing with it is agony. I use it when reading text documents, web pages, or code diffs.
Writing:
This is by far the most commonly used mode, which compromises colors and sharpness for way better latency. I use this for everything in the terminal, chat, general web browsing, and probably most other things not covered by the reading mode.
See the following photos for a close-up comparison:
Reading mode, where colored regions are pretty smooth and text looks sharp.Writing mode, where colored regions (light gray, red, green) are grainy and text is a bit blurry.
What about latency? Here’s the two short clips of me typing with the reading and writing modes:
Reading mode, with horrible latency for typing.Writing mode, with some but acceptable latency.
Ghosting? In my writing mode it’s minimal. It really doesn’t bother me.
About the color panel: I don’t like it very much to be honest. It was the only version of the Mira Pro available from the Swedish retailer at the time, so I went with it. I think I would’ve been happier with a monochrome panel, because the coloring technology makes it considerably darker.
Here’s a comparison between the Palma 2 Pro (using a similar but smaller Kaleido color panel) and my old Tab Ultra (with a monochrome panel):
Color vs Monochrome e-ink panels without backlight.
Unless the room has great diffuse lighting, natural or otherwise, the color panel does require some backlight. In direct sunlight or outdoors it works without. I might spend more time optimizing the lighting in my office to make this work during the winter months.
So, what’s to make of it? Personally, I enjoy using this monitor a lot, even if it’s not perfect. Should you buy an expensive 25” e-ink monitor? I cannot say. But if you do, let me know how it works out.
My custom themes and keybindings can be found here.
This blog is ancient, in blog years. The first post was on June 30, 1998, and it featured a randomized emboss for MathMap. Back in those days, it was a mix of neat little snippets like that and interesting links. The site was a single, hand-edited HTML file in reverse chronological order. It ran on a Linux mini-tower built from parts from the MIT Swapfest, and it lived under my desk.
Google hadn’t been incoporated yet. The Internet bubble was still inflating.
Over the years, the tech stack changed: for a while, this site used SGML-based rendering via a custom script (or was it XML?), then it was a nice interactive Typo site with comments, and then eventually it migrated to the current Jekyll architecture. Which seems to be about 12 years old. I’m pretty proud to have kept nearly all the inbound links working for decades now.
Around 2007 or so, I did a fun series of high effort posts about probability monads. But high-effort posts are a trap. Soon I started feeling like every post ought to be high effort. And then I wrote less and less.
But blogs are a bit of a retro endeavour these days. RSS readers still exist, but I imagine nearly all my subscribers have disappeared since the heady days of 2007. And apparently it’s trendy to work with the garage door up.
So maybe it’s time to get back this site’s roots. I don’t have any MathMap snippets for you today, sadly, because the last release seems to have been in 2004. But here’s a cool trick!
Do you miss the old-style Copilot completions? The ones where it inserted grey text at the cursor? There’s an open version of this called “FIM completion”. And the classic model for doing this is Qwen2.5 Coder 7B.
But it turns out that Qwen3.6 35B A3B is can also do autocompletion! The fact that it has 3B active parameters means that it’s fast. And the 35B total parameters means it’s smarter than the smaller models.
--no-mmproj says to disable the vision mode. --cache-type-k q8_0 --cache-type-v q8_0 reduces the cache precision, since we’re not really using the cache. You might also need to grab a smaller quant, depending on your available VRAM.
So how good is this? Well, the completions aren’t too bad at all, but Zed doesn’t seem to do much post-processing. So the completions to be too long. At lot of this could likely be improved with a proxy that did some pre- and post-processing, and maybe a bit of fine tuning.
But this is an actual, working, 100% local autocomplete. And it’s close to being actually good.
One neat thing about Bombadil’s specification language is that it’s plain TypeScript, with access to external NPM packages. I’ve written a specification that spell-checks my website — what you’re reading now — and I want to share how that turned out.
The inner loop (spell-checking):
Bombadil randomly walks the website and collects misspelled words as property violations. The specification uses nspell with American and British English dictionaries and a personal word list in the repository. This is fast and strict.
The outer loop (triage):
I’m running Claude Code with a spell-checking skill, a triage loop that goes something like this:
Run Bombadil against the local development server for 5 minutes and capture the output. If no words flagged, we’re done.
Collect each flagged word and the URL it appeared on.
Triage each word into one of these buckets:
Real typo: fix the markdown source
Legitimate common word: add to the custom dictionary
Legitimate uncommon or very technical word: mark inline with spellcheck="false"
Extraction noise: add a unit test and fix the word extractor
Run Bombadil against each failing URL to confirm the corrections.
Go to step 1.
This is slow and loose.
The hybrid model seems to work well; it has flagged words in almost every blog post. It has fixed 13 real typos and added 130+ words to my personal dictionary. Example typos include “forseeable”, “similiar”, “perculiar”, “occured”. Some of these were 10 years old.
Claude doesn’t have to waste tokens spell-checking everything over and over. Right now I’m just running this locally, but you could imagine a more elaborate setup for large websites where the “inner loop” runs as a nightly job, invoking the “outer loop” only on violations. You could involve a human where needed, and build up a domain-specific dictionary over time.
Note that using an LLM is entirely optional. It just saves me some time. You can do triage on your own.
Why not spell-check the sources directly? Yes, that is often preferable, and I use spell in Neovim all the time. But it’s not always practical. At least in my experience, the tooling trips up on syntax and templating in more complicated setups. Maybe your editor handles this better than mine does, or maybe you’re fine with tools like typos and codespell, but I like the fact that this approach is external and checks the rendered output. Given that Bombadil interacts with web applications, you could even run this against dynamic applications to spell-check states deep in the UI.
Speaking of source-level checking: since the custom dictionary is a plain word list, I point Neovim’s spellfile at it and use zg to add words while I edit. A single source of truth that both tools write to.
Being able to use NPM packages in specifications has turned out to be more useful than I expected. In addition to nspell, I’m using tlds to identify URLs. Bombadil is built for property-based testing of web applications, but with a specification language and package ecosystem at hand, its uses might be broader than my original vision.
If you’re interested in setting up something like this on your own, you’ll find the sources in my Bombadil playground.
Disclosure: I’m the original author and lead for the Bombadil project at Antithesis.
Exception annotations were introduced in GHC 9.10, and can be an invaluable tool
for debugging thorny problems. The initial implementation had some important
limitations that made them less useful in practice than one might hope, but
fortunately the situation has since been much improved. In this blog post we
will give a detailed overview of the status quo as of GHC 9.12/9.14, identify
some gotchas you should be aware and provide advise on how to deal with them,
and briefly look ahead to what will change in GHC 10.0. We will also dedicate a
section to discussing the problems in GHC 9.10, for those who cannot yet
upgrade.
Before we look at the general framework for exception annotations, let’s first
briefly recap the concept of backtraces, which is GHC’s answer to stack
traces in other languages. The situation is more complicated in Haskell due
laziness, and there are actually four different kinds of backtraces:
based on HasCallStack annotations
based on cost-centres (which will require compiling your program with
profiling enabled)
In this blog post we will use the first two only, but for the purposes of our
main discussion here the choice actually does not matter much; see GHC
proposal
Decorate exceptions with backtrace information
for details. If you’re interested in IPE backtraces specifically, you might also
be interested in our blog post
Better Haskell stack traces via user annotations,
which discusses some recent extensions we implemented to improve these.
HasCallStack backtraces
Consider this simple Haskell program, where main calls top calls middle
calls bottom:
A HasCallStack is essentially an additional function argument which is
automatically populated by GHC at call sites with information about where the
function was called. When we run this program, we see something like this:
HasCallStack backtrace:
collectBacktraces, called at exe/DemoCallStack.hs:13:11 in (..)
bottom, called at exe/DemoCallStack.hs:18:10 in (..)
middle, called at exe/DemoCallStack.hs:22:7 in (..)
top, called at exe/DemoCallStack.hs:25:8 in (..)
The only thing worth noting here is that the moment a HasCallStack chain is
broken, the backtrace is cut off there. For example, if middle does not have a
HasCallStack constraint, we can no longer see where middle was called from:
HasCallStack backtrace:
collectBacktraces, called at exe/DemoCallStack.hs:19:11 in (..)
bottom, called at exe/DemoCallStack.hs:24:10 in (..)
The fact that top still has a HasCallStack constraint does not matter: the
callstack is cut at the first missing link.
Cost centre backtraces
Cost centres are how GHC implements profiling: very roughly, the cost of a
computation is attributed to its enclosing cost centre (see chapter
Profiling of the GHC manual). Like HasCallStack,
this relies on source code annotations:
Unlike HasCallStack, however, GHC offers ways for inserting such annotations
automatically, which can often make cost centre based callstacks more practical
than HasCallStack. The most common flag to do this is -fprof-auto or (in
recent GHC) -fprof-late (see Late Cost Centre
Profiling). This inserts cost centres around all
top-level functions, as we did manually above.
Cost centre backtraces must be explicitly enabled by calling
setBacktraceMechanismState, and you need
to compile your code with profiling enabled; the
cabal option --enable-profiling
both enables profiling as well as automatic cost centre insertion. The backtrace
for this example might look something like
Be aware however that optimizations can delete cost centres, especially in
simple examples like this (#27225).
Cost centres vs exception handling
Consider the following example: as before, main calls top calls middle
calls bottom, which prints a backtrace; however bottom then throws an
excepton. Meanwhile, main installs an exception handler called handlerTop,
which in turn calls handlerMiddle calls handlerBottom, which prints its
own backtrace:
HasCallStack backtrace:
collectBacktraces, called at exe/DemoCCS.hs:24:11 in (..)
bottom, called at exe/DemoCCS.hs:29:10 in (..)
middle, called at exe/DemoCCS.hs:32:7 in (..)
top, called at exe/DemoCCS.hs:41:5 in (..)
as before; the HasCallStack printed by handlerBottom is very similar:
HasCallStack backtrace:
collectBacktraces, called at exe/DemoCCS.hs:13:11 in (..)
handlerBottom, called at exe/DemoCCS.hs:17:19 in (..)
handlerMiddle, called at exe/DemoCCS.hs:20:16 in (..)
handlerTop, called at exe/DemoCCS.hs:41:18 in (..)
For the cost-centre based backtrace, the one shown in bottom is as before:
Whether or not this is expected/correct behaviour is arguable, but the rule is
this: the cost centre stack is not restored until we leave the scope of
catch. Put another way: the cost centre stack reflects the fact that bottom
“calls” handlerTop, however indirectly. This applies transitively: if
handlerTop would throw an exception, which would then be caught by some other
exception handler, then its backtrace would reflect that top “called”
handlerTop “called” that other exception handler. This kind of situation can
arise quite naturally, for example when using handlers that deallocate some
resources and then rethrow the exception.
Basic definitions
Before we look at the subtleties that arise from actually catching and throwing
(or rethrowing) exceptions, we’ll first get the basic definitions out of the
way. These have not changed much between recent GHC versions and are hopefully
uncontroversial.
Exception annotations
Exceptions annotations can basically be anything at all; the only requirement is
that that we can display them:
classTypeable a =>ExceptionAnnotation a where displayExceptionAnnotation :: a ->String
An important instance of this class is Backtraces, which
wraps a set of different kinds of backtraces:
An exception context is essentially just a list of exception annotations. However,
since those annotations may be of different types, we need to wrap them in an
existential:
dataExceptionContext=ExceptionContext [SomeExceptionAnnotation]dataSomeExceptionAnnotation=forall a.ExceptionAnnotation a =>SomeExceptionAnnotation a
There are functions for manipulating the exception context. The most important
are emptyExceptionContext and
addExceptionAnnotation, for creating an
empty context and inserting an annotation into an existing context respectively.
emptyExceptionContext ::ExceptionContextaddExceptionAnnotation ::ExceptionAnnotation a => a ->ExceptionContext->ExceptionContext
Pivotal change: SomeException
The pivotal change in all of this is in the definition of SomeException which,
starting in GHC 9.10, now has an associated list of annotations:
dataSomeException=forall e. (Exception e, HasExceptionContext) =>SomeException etypeHasExceptionContext= (?exceptionContext ::ExceptionContext)
The use of an implicit parameter means that pattern
matching on SomeException remains possible in the same way as before (though
the annotations would be silently dropped).
There are various functions for extracting and manipulating the exception
context associated with an exception, such as
someExceptionContext and
addExceptionContext:
someExceptionContext ::SomeException->ExceptionContextaddExceptionContext ::ExceptionAnnotation a => a ->SomeException->SomeException
However, probably the most important function for extending exception contexts
is annotateIO, which installs an exception handler that
extends any exception that is thrown with the specified annotation:
annotateIO ::forall e a.ExceptionAnnotation e => e ->IO a ->IO aannotateIO ann (IO io) =IO (PrimOp.catch# io handler)where handler se = PrimOp.raiseIO# (addExceptionContext ann se)
It is important to emphasize that this is implemented with
primops, not with the regular catch and throwIO
functions, which do considerably more than merely catching and throwing, as we
shall see.
Exception type class
The Exception type class is a central abstraction in Haskell’s exception
ecosystem. As part of the exception annotation work, it has received one minor
extension, and it was changed in two not-so-minor-but-rather-subtle ways. Let’s
first get the part out of the way which has not changed: exceptions are no
good if we cannot see them:
class (Typeable e, Show e) =>Exception e where displayException :: e ->String displayException =show-- (..)
backtraceDesired
The minor extension is a new function called
backtraceDesired, which indicates if a backtrace
should be attached to exceptions of this type; we will see how this function is
used when we discuss the implementation of throwIO.
class (Typeable e, Show e) =>Exception e where-- (..) backtraceDesired :: e ->Bool backtraceDesired _ =True
The argument to backtraceDesired is already fully constructed exception; the
question is whether a backtrace should be added to that exception. In most
cases the argument can simply be ignored, but it doesn’t have to be. For all
but a handful of specialized cases the default implementation (indicating that
yes, we want a backtrace) will be fine.
fromException
The not-so-minor-but-rather-subtle changes are in fromException and
toException, which remove and add the SomeException wrapper around
exceptions respectively. Let’s first look at fromException:
class (Typeable e, Show e) =>Exception e where-- (..) fromException ::SomeException->Maybe e fromException (SomeException e) = cast e
This may look no different from the implementation
prior to 9.10,
but recall that SomeException now has an additional field: the exception
annotations. As mentioned above, a pattern match like this will silently discard
those annotations.
toException
The final function in the Exception class is toException, which is intended
to add the SomeException wrapper.
class (Typeable e, Show e) =>Exception e where-- (..) toException :: e ->SomeException
Prior to 9.10, the default implementation literally just added the
SomeException constructor:
-- implementation prior to 9.10 toException =SomeException
However, starting in 9.10 we also need to give an initial value for the
exception context. The default implementation, reasonably enough, chooses the
empty context:
-- implementation in 9.10, 9.12, 9.14, and 10.0 toException e =let?exceptionContext = emptyExceptionContext inSomeException e
SomeExceptionitself is also an instance of Exception; fromException is
trivial, and backtraceDesired and displayException piggy-back on the
definition of whatever exception is wrapped:
The definition of toException is more problematic, however. Prior to 9.10,
calling toException on SomeException was just an identity:
instanceExceptionSomeExceptionwhere-- (..)-- Prior to 9.10 toException se = se
Now, however, the implementation must clear the existing context in order to
satisfy the contract:
instanceExceptionSomeExceptionwhere-- (..) toException (SomeException e) =let?exceptionContext = emptyExceptionContext inSomeException e
I think this is simply wrong; at the very least, it is highly counter-intuitive,
and it also does not match
the original proposal;
I don’t know why this was changed. We will see some
consequences of this design choice
when we discuss throwing exceptions.
Newtype helpers
There are two auxiliary types, with their own Exception instances, that can be
helpful when throwing or catching exceptions in specific ways. We haven’t
discussed either throwing or catching yet, but we will nonetheless discuss these
auxiliary types first as we will need them in the subsequent sessions.
NoBacktrace
NoBacktrace can be used to override backtraceDesired:
newtypeNoBacktrace e =NoBacktrace einstanceException e =>Exception (NoBacktrace e) where fromException =fmapNoBacktrace. fromException toException (NoBacktrace e) = toException e backtraceDesired _ =False-- displayException left at its default implementation
ExceptionWithContext
The other, arguably more imporant, auxiliary type is ExceptionWithContext.
The definition itself is straight-forward: it simply pairs some value with an
exception context:
dataExceptionWithContext a =ExceptionWithContextExceptionContext a
The idea is that this type gives us a way to catch exceptions of specific types (rather than catching SomeException), and still get access to the exception context. For example:
The implementation is reasonably straight-forward:
instanceException a =>Exception (ExceptionWithContext a) where toException (ExceptionWithContext ctxt e) =case toException e ofSomeException c ->let?exceptionContext = ctxtinSomeException c fromException se =do e <- fromException sereturn (ExceptionWithContext (someExceptionContext se) e) backtraceDesired (ExceptionWithContext _ e) = backtraceDesired e displayException = displayException . toException
That said, the devil is very much in the detail with these kinds of definitions,
and as we shall see, it was defined incorrectly in GHC
9.10.
Throw
The primary function for throwing an exception is throwIO, which is defined
as1
throwIO :: (HasCallStack, Exception e) => e ->IO athrowIO e =do se <- toExceptionWithBacktrace eIO (PrimOp.raiseIO# se)
Most of the actual work happens in toExceptionWithBacktrace:
toExceptionWithBacktrace :: (HasCallStack, Exception e) => e ->IOSomeExceptiontoExceptionWithBacktrace e =if backtraceDesired e thendo bt <- Base.collectBacktracesreturn (addExceptionContext bt (toException e))elsereturn (toException e)
That is, if a backtrace is desired, we collect one and add it as an annotation
to the exception that we’re about to throw.
Generalization
In GHC 9.14 toExceptionWithBacktrace was generalized to
toExceptionWithBacktrace :: (HasCallStack, Exception e) => e ->IOSomeExceptiontoExceptionWithBacktrace e =if backtraceDesired e thendoSomeExceptionAnnotation ea <- collectExceptionAnnotationreturn (addExceptionContext ea (toException e))elsereturn (toException e)
This is an experimental API (not yet part of base); see CLC #348
for details. The idea is that you can use
setCollectExceptionAnnotation to
register your own function to be run to construct an annotation whenever an
exception is thrown anywhere. For example, if you’re worried that some IO faults
are happening due to your CPU overheating, you might use
By default, the collection callback is collectBacktraces, so unless you
register a different callback the behaviour is the same as in 9.10 and 9.12.
⚠️ Caution: Throwing SomeException
Because throwIO calls toException, and since toException for
SomeExceptionclears the exception context,
you probably don’t want to call throwIO on an argument of type
SomeException: any exception annotations that might be embedded in that
exception will be lost.
The most common case for throwing SomeException is inside an exception
handler; we will cover this specific case of rethrowing exceptions when we
discuss onException, but we can
reuse the same combinators also to define a general “throw precisely this
exception” function:
The most important change in GHC 9.12 from 9.10 is in the definition of catch, which now implements the WhileHandling proposal. The idea is that
when we throw a new exception while handling another, we annotate that new
exception with the old exception: the new exception arose while handling
the old exception:
dataWhileHandling=WhileHandlingSomeExceptionderivingShowcatch ::Exception e =>IO a -> (e ->IO a) ->IO acatch (IO io) handler =IO$ PrimOp.catch# io handler'where handler' se =case fromException se ofJust e' -> PrimOp.catch# (unIO (handler e')) (handler'' se)Nothing-> PrimOp.raiseIO# se handler'' se se' = PrimOp.raiseIO# (addExceptionContext (WhileHandling se) se')
⚠️ Caution: Rethrowing the same exception
An important combinator for dealing with exceptions is onException, which
runs some specified action when an exception occurs (typically some resource
cleanup) and then rethrows the exception again:
onException ::IO a ->IO b ->IO aonException io what = io `catch` \e ->do _ <- what throwIO (e ::SomeException)
As written, this is suboptimal: for every layer of onException, we re-throw
the annotation stripped from its original annotations (due to throwIO and
toException for SomeException), and with a new WhileHandling annotation
with the original exception (due to catch). This result in unnecessary noise:
all the information is still there, but it’s buried. When we rethrow the same
exception, there is no need for WhileHanding: we should just throw the
original exception as-is.
To solve this, base now offers new functions specifically to
catch-and-rethrow: catchNoPropagate2 is like the old catch, without
the handler that adds the WhileHandling annotation; and rethrowIO, which
avoids adding a backtrace (using NoBacktrace; moreover, both
of these explicitly preserve contexts (using
ExceptionWithContext):
catchNoPropagate ::Exception e =>IO a -> (ExceptionWithContext e ->IO a) ->IO acatchNoPropagate (IO io) handler =IO$ PrimOp.catch# io handler'where handler' se =case fromException se ofJust e' -> unIO (handler e')Nothing-> PrimOp.raiseIO# serethrowIO ::Exception e =>ExceptionWithContext e ->IO arethrowIO e = throwIO (NoBacktrace e)
This then enables the following improved implementation of onException:
onException ::IO a ->IO b ->IO aonException io what = io `catchNoPropagate` \e ->do _ <- what rethrowIO (e ::ExceptionWithContextSomeException)
⚠️ Caution: Displaying exceptions
The final pitfall we need to discuss is displaying exceptions. Usually we call
displayException to do so, but this does not show annotations. The idea is
that displayException is meant to render an exception for users, not
necessarily developers.3 Starting withGHC 9.14 there is a separate function
displayExceptionWithInfo, but that is not
available in GHC 9.12; moreover, even in GHC 9.14 I would advise against using
it when you are debugging, as it only shows the top-level annotations, making
things like WhileHandling much less useful.
Personally, I like to use my own custom exception handler which shows the full
exception, and makes a few other improvements also: it makes the nesting
structure clearer, and reorders annotations to improve readability; you can find
an example implementation on GitHub .
GHC 9.10
If you cannot upgrade from GHC 9.10, unfortunately the exception annotation
infrastructure has some important limitations. Upgrade if you can; if not, this
section will explain what you need to be aware of.
Lost annotations
As we remarked when we discussed catch, the WhileHandling proposal
only got implemented in GHC 9.12. In GHC 9.10 the definition of catch was still
unchanged from its definition before the exception annotation proposal:
catch ::Exception e =>IO a -> (e ->IO a) ->IO acatch (IO io) handler =IO$ PrimOp.catch# io handler'where handler' se =case fromException se ofJust e' -> unIO (handler e')Nothing-> PrimOp.raiseIO# se
However, the
Exception instance for SomeExceptionwas already changed, so that toException clears the exception context.
This means that if an exception with annotations is ever caught and rethrown
anywhere, in a pattern such as
someAction `catch` \(e ::SomeException) -> throwIO e
those annotations will be lost. Similarly, since onException had not yet been
changed either, any call to onException, and by implificationbracket,
anywhere in your callstack would also lose any annotations:
bracket ::IO a -> (a ->IO b) -> (a ->IO c) ->IO cbracket before after thing = mask $ \restore ->do a <- before r <- restore (thing a) `onException` after a _ <- after areturn ronException ::IO a ->IO b ->IO aonException io what = io `catch` \e ->do _ <- what throwIO (e ::SomeException)
In both cases, throwIOwill insert a new backtrace, but that backtrace will
point to where the exception was rethrown, not to where it was thrown
originally. What’s worse, neither bracket nor onException have a
HasCallStack constraint, so all we see in the callstack is the call to
throwIO from onException itself.
Cost centre stacks do help a bit here (provided you enable profiling): at least
you’ll get to see the full backtrace to the exception handler, and with a bit of
luck even to the original call to throw, due to the semantics of semantics of
cost centres in exception handlers. That
won’t always be the case though (for example, in the case of asynchronous
exceptions), and you won’t see any of the additional annotations that might have
been added to the exception.
Duplicated annotations
The Exception instance for ExceptionWithContext in GHC 9.10 has an
incorrect definition for toException:
instanceException a =>Exception (ExceptionWithContext a) where-- (..)-- implementation in GHC 9.10 toException (ExceptionWithContext ctxt e) =let?exceptionContext = ctxt inSomeException e
It does not use toException of the underlying type (the a type
parameter); in most cases this does not matter, because toException
rarely does anything interesting. Even in the case of SomeException, where
toException does something “interesting” (if perhaps ill-advised), to wit
clear the exception context, that doesn’t matter here because we are
overriding that context anyway. However, there might be types where
toException genuinely does something important (even if I am not aware of
any such cases currently).
In the specific case that aisSomeException, this will create a
nestedSomeException: SomeException (SomeException someOtherException)
with two copies of the context (the annotations).
The second point here is more important: if we later have exception handlers
that manipulate the exception context, they will manipulate the outer context
but not the inner. Indeed, if that “manipulation” is “clear the context”
(see previous section), we might end up in the somewhat bizarre situation
where these two problems cancel out: if we have
someAction `catch` \(ExceptionWithContext ctxt (e ::SomeException)) throwIO $ExceptionWithContext ctxt e
then this exception handler will duplicate the annotations, a later exception
handler might lose the outermost annotations (previous section) but not the
inner, and all of a sudden annotations that were lost mysteriously re-appear;
see GHC ticket #27194.
Unfortunately, this is not a viable workaround for the lost annotation problem,
as it changes the type of the exception nested in the (outer) SomeException
from whatever it really should have been to (the inner) SomeException, which
will break any exception handlers for that specific type.
GHC 10.0
The upcoming GHC 10.0 releases makes a few improvements to the exception
annotation infrastructure. The first important improvement is that exception
handling in STM was lagging behind a bit; this will be rectified
(#25365).
onException ::IO a ->IO b ->IO aonException io what = io `catchNoPropagate` \e ->do _ <- what rethrowIO (e ::ExceptionWithContextSomeException)
We mentioned that that catchNoPropagate does not install an exception
handler that installs a WhileHandling annotation, because we are rethrowing
the very same exception. However, if what throws an exception that is no
longer the case! The definition of onException is therefore modified to
onException io what = io `catchNoPropagate` \e ->do _ <- annotateIO (whileHandling e) what rethrowIO (e ::ExceptionWithContextSomeException)
See CLC Proposal #397 for details. As an example, consider what happens if the release callback
of bracket itself throws an exception:
With the new definition onException (and my custom exception display function, which is still needed), we get
demo-bracket-release-fail: Uncaught exception of type ReleaseFailed
ReleaseFailed
HasCallStack backtrace:
throwIO, called at exe/DemoBracketReleaseFail.hs:42:38 in (..)
middle, called at exe/DemoBracketReleaseFail.hs:46:7 in (..)
top, called at exe/DemoBracketReleaseFail.hs:55:5 in (..)
WhileHandling
MyException
MyException
MyAnnotation 123456789
HasCallStack backtrace:
throwIO, called at exe/DemoBracketReleaseFail.hs:38:48 in (..)
bottom, called at exe/DemoBracketReleaseFail.hs:42:70 in (..)
middle, called at exe/DemoBracketReleaseFail.hs:46:7 in (..)
top, called at exe/DemoBracketReleaseFail.hs:55:5 in (..)
Very nice!
Conclusions
Exception annotations can be invaluable when debugging difficult problems. While
the initial implementation in GHC 9.10 had some important limitations, the
situation has since been much improved. Provided you use GHC 9.12 or later,
there are two things to pay attention to in your own code (these apply to 9.12,
9.14 and 10.0):
Define your own custom function to display exceptions, which shows all
annotations, not just the top-level ones (or use mine).
Be cautious with throwing SomeException: toException for SomeException
will clear the exception context, which is almost certainly not what you want.
For catch-and-rethrow, use the combinators available specifically for that
purpose.
That said, there are still a few minor shortcomings to be aware of:
GHC 9.12 and 9.14:
Exception handling in STM has not yet been updated: throwSTM does not
collect a backtrace, and catchSTM does not add any WhileHandling
annotations (#25365).
onException does not add any WhileHandling exceptions; as a result, if
the resource deallocation callback to bracketitself throws an
exception, the original exception will be lost.
Both of these will be addressed in GHC 10.0.
exceptions-0.10.9: this is the version of exceptions that is bundled
with GHC 9.12, but lags behind a bit. For example, the definition
of generalBracket in exceptions-0.10.9
does not use any of the abstractions for rethrowing; this is fixed in
exceptions-0.10.12.
The impact is however limited: it merely means that there are some extraneous
WhileHandling annotations, resulting in unnecessary noise.
Any catch-and-rethrow patterns implemented in other packages should not
lose any annotations, provided that they use catch from base.
We will ignore calls to withFrozenCallStack, which hide some internal
functions from the HasCallStack backtrace. This makes the backtrace slightly
more readable, but does not otherwise change anything. See
CLC #387.↩︎
Some versions of base distinguish
between catchExceptionNoPropagate and catchNoPropagate, which differ only in
some strictness annotations. Strictness can make a big difference, especially
when IO actions are undefined rather than throwing an exception. However, this
is its own can of worms, and outside the scope of this blog post. See CLC
proposal #383 for some discussion.↩︎
In GHC 9.10, displayExceptiondid show
annotaitons, but this got rolled back in 9.12; see CLC #285 for a
detailed discussion.↩︎
Seven years ago I wrote a post about compatibility packages. It is now highly outdated, so let us revisit the matter.
Recently there have been a small push towards reinstallable base. While it's still far from being a thing, it made me remember that using impl(ghc >= 7.9)-like conditionals to guard against different base versions is semantically wrong.
Also recently there is increasing? interest in MicroHs. While I personally don't care about that compiler, I realized that I can make its users experience at least slightly nicer though still somewhat ignoring MicroHs existence.
An example
Luckily there is a solution, and it was around for a long time: automatic flags. Here is a complete example:
flag base-ge-4-16description: @base >=4.16@ (GHC-9.2)default: Truemanual: Falseflag base-ge-4-17description: @base >=4.17@ (GHC-9.4)default: Truemanual: Falselibrary ...build-depends: base >=4.12.0.0&&<4.23if!flag(base-ge-4-16)build-depends: OneTuple >=0.4.2&&<0.5if!flag(base-ge-4-17)build-depends: data-array-byte >=0.1.0.1&&<0.2if flag(base-ge-4-16)build-depends: base >=4.16elsebuild-depends: base <4.16if flag(base-ge-4-17)build-depends: base >=4.17elsebuild-depends: base <4.17
First we declare the flags. I chose to use a naming scheme reminiscing the condition: base-ge-4-17 for base >=4.17.
Then we make the flag selection deterministic:
if flag(base-ge-4-17)build-depends: base >=4.17elsebuild-depends: base <4.17
Because the base >=4.17 and base <4.17 conditions are disjoint, there is at most one valid flag assignment for any given install plan which includes base - but because base is a direct dependency it has to be in the install plan. This is why I call such flag deterministic1.
And finally we use the flag value to add a conditional dependency:
but as I mentioned in an introduction that is semantically wrong. In this case Data.Array.Byte module is introduced in base-4.17, which just happen to be available in GHC-9.4. In the future there might not be one-to-one correspondence between (major) GHC and base versions.
Moving to use automatic flags removes the direct mention of GHC. This also (hopefully) helps MicroHS users: we don't need to edit
- if !impl(ghc >=9.4)+ if !impl(ghc >=9.4) && !impl(mhs)
as there are no direct mention of compilers. The library compatibility conditions are expressed using library version vocabulary.
Low-level tools for high level concept
It is worth mentioning that the three parts: defining the flag, making flag selection deterministic and using the flag value as a condition is indirect way to say something like
In other words we use "low-level" tools to express a high level concept.
Maybe some future version of .cabal format would include the high-level way directly. However, the low-level "desugaring" makes it impossible to scrutinize flag selection on indirect dependencies, e.g. we do add dependency to base
if flag(base-ge-4-17)build-depends: base >=4.17elsebuild-depends: base <4.17
Viewing it from that perspective if a consturct like depends(base >=4.17) is added to .cabal format, it should also add a constraint for install plan to include base, though not necessarily adding it direct dependency. That way the conditional will be deterministic. But such implicit dependency might feel unnatural.
Conclusion
I already rewrote impl(ghc) conditionals to use automatic flags in few packages, and will continue to do that as I'm doing other maintenance tasks.
It seems that OneTuple and data-array-byte are the only few relevant compatibility packages at the moment (using GHC 9); there were a lot of compatibility packages in the last decade (tagged, nats, void, fail, semigroups, bifunctors, contravariant, bifunctor-classes-compat, type-equality, foldable1-classes-compat), but if you don't need to support very old bases & GHCs, we don't need to depend on them for their compatibility shims anymore.
The library part of compatibility story is relatively good, even without having higher level construct like if depends (lib >= x.y) construct. However, the compatibility of language level constructs is lacking. There is no way to ask in .cabal file whether compiler support DeriveGeneric or TemplateHaskell. We can require these extensions, but we cannot ask whether they exist at all. Neither we can differentiate between different versions. Is compiler's ImpredicativeTypes "broken" or not, does LambdaCase include \cases etc. Some part of me wishes the MicroHs a great success, so those issues become more pressing and eventually solved. Solved in some other ways than maintainers hardcoding compiler versions in the package definitions.
In my opinion all automatic flags have to be deterministic. For example having automaticdebug flag is IMO just wrong. There are also a bit edge cases related to pkg-config, and I think it's a "bug" in .cabal format that we cannot make pkg-config based library version selection deterministic.↩︎
Recently I realised that it'd be really nice if jumping to errors would store
the previous location in the Evil jump list. These definitions do just that
(evil-define-motionmes/evil-goto-next-error(count):jump t
(unless(bound-and-true-p flymake-mode)(signal 'search-failed nil))(flymake-goto-next-error count))(evil-define-motionmes/evil-goto-prev-error(count):jump t
(unless(bound-and-true-p flymake-mode)(signal 'search-failed nil))(flymake-goto-prev-error count))
and for now I've bound them to C-j and C-k (because that's what
evil-collection does)
I was under the impression that when using elpaca you needed to disable
use-package, and that when using elpaca-use-package, you were redefining the
macro. I’m not 100% sure about this, but the documentation has an example of
use-package and how it actually expands to an elpaca command.
I wouldn't know. All I can say is that it would be nice if package managers that
hook into, or completely redefines use-package, would document if they deviate
from the behaviour of "vanilla use-package" in some way.
Part two
Given that, use-package’s documentation is always going to be a little off,
since elpaca is doing everything async. The only way I’ve found to reliably
manage some dependencies is to use the elpaca-after-init hook, so they don’t
even try to run until elpaca is finished loading everything.
I'd say it sometimes seems like the documentation for use-package is a little
off for use-package itself 🙂
The README for Elpaca says that
Add configuration which relies on after-init-hook, emacs-startup-hook, etc to
elpaca-after-init-hook so it runs after Elpaca has activated all queued
packages.
but that seems like a very big hammer and as I understand it I'd have to move
the whole :init block for python-mode into the hook in that case. Playing
around with the various blocks for use-package isn't too time consuming and I
think it's a good first thing to try.
I should have dealt with comments I got to my posts on how I deal with secrets
in my work notes, here, and here. Better late than never though, I hope.
Comment from Stefano R
The first one is a link to post titled How I use :dbconnection in org files. It
describes a nice way of setting sql-connection-alist based on the contents of
a file, in his case ~/.pgppass.
Comment from Harald J
The other starts with a function for searching ~/.authinfo.gpg for entries of
the form
and then setting sql-password-search-wallet-function and sql-password-wallet
to tell sql-mode to use it
(defunmy/sql-auth-source-search-wallet(wallet product user server database port)"Read auth source WALLET to locate the USER secret.
Sets `auth-sources' to WALLET and uses `auth-source-search' to locate the entry.
The DATABASE and SERVER are concatenated with a slash between them as the
host key."(when-let(results (auth-source-search :host(concat server "/" database):user user
:port(number-to-string port)))(when(and(= (length results) 1)(plist-member (car results):secret))(plist-get (car results):secret))))(setq sql-password-search-wallet-function #'my/sql-auth-source-search-wallet)(setq sql-password-wallet "~/.authinfo.gpg")
The value for sql-connection-alist is then as normal
Last week at Bug Bash 2026, I had a bunch of interesting discussions about testing non-web interfaces with Bombadil, our new property-based testing framework for user interfaces. One direction that I already wanted to explore is terminal user interfaces (TUIs), and the hallway discussions gave me a nudge to get going. I started hacking on the flight back home, and a few days later that embryo of a TUI fuzzer started to emerge.
The fuzzer in action, finding a bug in vitetris. (CW: flashing!)
It’s built on top of two key crates:
portable-pty, a pseudo-teletype in Rust that runs the program under test, and
libghostty-vt, a Rust wrapper around the Zig library, which interprets the output of the PTY and provides a virtual terminal API from which you can read cell contents, styles, scroll through the scrollback, etc.
With these two in place, I built a very basic fuzzer for TUIs: it runs the command you give it, polls its output, and writes interleaved random input sequences (printable ASCII characters and ANSI escape sequences). It also scrolls and resizes the terminal occasionally. Timing is a bit tricky, but it seems the current approach works fine: polling reads until the terminal is idle, capture state, then apply new inputs. Regarding speed, it depends a lot on the program being tested, but it looks capable of capturing at least 300 states per second.
I tried finding some basic TUI programs and terminal games to test. Much to my surprise, within the first few days I had found four seemingly real bugs in real software:
vitetris has a bug where if you enter just a number in the host name (e.g. 6) and try to connect to a remote game, the UI freezes.
rlwrap got into a segfault which I haven’t yet been able to troubleshoot.
Pretty cool. Today, I merged this work to main in Bombadil. It’s not yet released, but if you’re curious you can try it already by downloading a bombadil-terminal binary from the CI artifacts. On macOS you’ll need to remove the quarantine bit to bypass GateKeeper.
Now, the work remains to make this a solid tool. Here are some future goals:
Integrate it with the specification framework in Bombadil, so that you can define custom properties and action generators. It’d be neat to provide an API akin to querySelector that could parse and traverse panels drawn with box-drawing characters. You probably also want to validate that those borders line up correctly.
Generate a lot more diverse input and terminal actions. For instance, generate sequences from the Kitty keyboard protocol.
Make the test runner’s user interface better. Perhaps a TUI?!
Make this part of the ordinary bombadil binary, I think. There could be subcommands for browser and terminal testing tools.
Run it in Antithesis to see what that fuzzer can find.
All right, short post today — I just wanted to share my excitement and early results.
A huge thanks to Uzair Aftab, maintainer of libghostty-rs, for helping me get libghostty-vt building under Nix!
One of my favourite Haskell papers is McIlroy’s wonderful “Power
Series, Power Serious� (1999). The paper is about power
series, which are a type of infinite sums that behave like
(infinite) polynomials. For example,
<semantics>cos<annotation encoding="application/x-tex">\cos</annotation></semantics>
can be represented by the following power series:
A power series is characterised fully by its coefficients, meaning
that we can represent one as an infinite stream of rational numbers. In
Haskell, we often use lazy lists to represent streams, so we can encode
a power series with the following type:
typePowerSeries= [Rational]
In this encoding, we can write
<semantics>cos<annotation encoding="application/x-tex">\cos</annotation></semantics>
as the following:
cos ::PowerSeriescos=zipWith (*) (cycle [1,0,-1,0]) (scanl (/) 1 [1..])>>>cos[1,0,-1/2,0,1/24,0,-1/720,...
We can also build
<semantics>sin<annotation encoding="application/x-tex">\sin</annotation></semantics>:
While it can be difficult and unintuitive to work with infinite
series like the ones above, happily we can define all of the normal
numeric operations on power series as (lazy) list-manipulation
programs:
(if you try and put this code into a Haskell interpreter you’ll get
all sorts of warnings; I’ll put the full code for this post below with
all of the imports and pragmas you need to get it to work)
McIlroy (1999)
goes through the various algorithms and numeric operations that can be
implemented on this representation, but at this point I would like to
diverge from the paper and turn our focus to finite polynomials. Like a
power series, a finite polynomial can be represented by a list of
coefficients:
typePolynomial= [Rational]
And, even though the underlying list is finite rather than infinite,
the numeric operations work basically the same way as they do on power
series. We just need to add clauses in each function to handle the empty
list:
The definition of a power series above suggests that we should
implement evaluation using exponentiation and indices:
eval ::Polynomial->Rational->Rationaleval p x =sum (zipWith (\a i -> a * x^i) p [0..])
And this does in fact give us the correct answer. Consider the
polynomial
<semantics>4+2x+5x2−x3<annotation encoding="application/x-tex">4 + 2x + 5x^2 - x^3</annotation></semantics>:
poly = [4,2,5,-1] -- 4 + 2x + 5x² - x³eval poly x = eval [4,2,5,-1] x=sum (zipWith (\a i -> a * x ^ i) [4,2,5,-1] [0..])=4*x^0+2*x^1+5*x^2+ (-1)*x^3=4+2*x +5*x^2- x^3
However, this evaluation algorithm is unsatisfactory in one respect:
it performs a lot of multiplication. In numeric programs, we
generally want to minimise the number of multiplications performed,
since multiplication is a relatively expensive operation (when compared
to addition or subtraction). In the example above, it takes six
multiplications to compute the result: one for
<semantics>2x=2×x<annotation encoding="application/x-tex">2x = 2 \times x</annotation></semantics>,
two for
<semantics>5x2=5×x×x<annotation encoding="application/x-tex">5x^2 = 5 \times x \times x</annotation></semantics>,
and three for
<semantics>−x3=−1×x×x×x<annotation encoding="application/x-tex">-x^3 = -1 \times x \times x \times x</annotation></semantics>.
In general, for a polynomial of degree
<semantics>n<annotation encoding="application/x-tex">n</annotation></semantics>,
the above implementation of eval
will perform
<semantics>�(n2)<annotation encoding="application/x-tex">\mathcal{O}(n^2)</annotation></semantics>
multiplications.
There is, however, a trick that can bring the number of
multiplications down to
<semantics>�(n)<annotation encoding="application/x-tex">\mathcal{O}(n)</annotation></semantics>:
Horner’s rule. The basic idea is to rewrite the expanded polynomial
<semantics>4+2x+5x2−x3<annotation encoding="application/x-tex">4 + 2x + 5x^2 - x^3</annotation></semantics>
into a factorised form:
<semantics>4+x(2+x(5+x(−1)))<annotation encoding="application/x-tex">4 + x(2 + x(5 + x(-1)))</annotation></semantics>.
If we evaluate this expression directly, we will only have to
perform three multiplications (and we don’t even have to perform any
extra additions as compensation). While Horner’s rule is really quite a
simple trick, the generalised pattern is surprisingly powerful (Gibbons
2011). Indeed, the representation I develop in this post is
basically a data structure encoding of Horner’s rule.
Before getting there, however, let’s return to our list-based
polynomial, and look at using Horner’s rule to implement eval. Interestingly, the list-based
representation has kind of already performed our factorisation for us.
As a result, Horner’s rule evaluation is actually more natural to
implement than the expanded version above.
eval ::Polynomial->Rational->Rationaleval xs x =foldr (\a p -> a + x * p) 0 xs
Multiple Variables
A cool trick with this representation is that if you want to support
multiple variables you can smuggle them in through the coefficients. A
polynomial in two variables is the same as a polynomial with
coefficients drawn from another polynomial.
typeTwoVar= [Polynomial]
To save us having to write a separate Num instance
for TwoVar, we can
instead generalise the Num instance
on Polynomial
above:
instanceNum a =>Num [a] where
The rest of the instance is the same. Now, we can write 5^2 ::Polynomial
or 6 ::TwoVar
and it will just work.
We also have to generalise the type of eval slightly:
eval ::Num a => [a] -> a -> a
but again, the implementation remains the same.
With this machinery, we can now write and evaluate polynomials in 2
variables:
eval2 ::TwoVar->Rational->Rational->Rationaleval2 p x y = eval (eval p [x]) yvar ::Num a => [a]var = [0,1]x = vary = [var]poly =2* x ^2- y ^3+4>>> poly[[4,0,0,-1],[0],[2]]>>> eval2 poly 23-15
We can even use some typeclass shenanigans to build a generalised
evaluator that works with any fixed number of variables.
Implementation of an Evaluator for Polynomials in Arbitrary Variables
instanceNum n =>Num (e -> n) wherefromInteger=const.fromInteger (f + g) x = f x + g x (f * g) x = f x * g xabs= (abs.)signum= (signum.)negate= (negate.)classNum r =>Poly p r | p -> r, r -> p where evalN :: p -> rinstancePolyIntegerIntegerwhere evalN =idinstancePoly p r =>Poly [p] (Integer-> r) where evalN xs x =foldr (\a s -> evalN a +fromInteger x * s) 0 xs
While the above representation is elegant, it is inefficient, and
perhaps a little unintuitive. In most implementations I have seen,
variables are represented simply with a type for names, rather than the
kind of implicit de Bruijn indices used above. One natural
representation uses a list of terms:
newtypePoly v c =Poly { terms :: [([v], c)] }
Here, a value of type Poly v c is a
polynomial with coefficients drawn from c and variables from v. It is a list of monomials, where
the outer list represents a sum, and each monomial represents a product
of variables with a single coefficient.
This representation perhaps maps more closely to the description of
multivariate polynomials that many of us will have encountered in
secondary school: it’s straightforward to see how a polynomial like
<semantics>2xy+y2−3<annotation encoding="application/x-tex">2xy + y^2 - 3</annotation></semantics>
corresponds to the value Poly [([X,Y],2),([Y,Y],1),([],-3)].
The previous representation (TwoVar) would
represent the same expression as the enigmatic [[-3,0,1],[0,2]].
However, there are some wrinkles to this type that are worth noting.
First we can see that multiplication is not commutative (even
after normalisation).
x =Poly [([X],1)]y =Poly [([Y],1)]x * y ==Poly [([X,Y],1)]y * x ==Poly [([Y,X],1)]x * y /= y * x
This is in contrast to TwoVar, where
both
<semantics>xy<annotation encoding="application/x-tex">xy</annotation></semantics>
and
<semantics>yx<annotation encoding="application/x-tex">yx</annotation></semantics>
would be represented as [[0,0],[0,1]].
Conceptually, polynomials are a kind of free structure: they
represent the normalised and quotiented syntax of an algebraic theory.
The fact that Poly above
doesn’t have commutative multiplication just tells us that the
underlying algebraic theory in question here is noncommutative
rings, rather than commutative rings.
The second thing to note about this type is actually two related
observations about inefficiency. Because I didn’t implement
normalisation on any of the numeric operations, we might expect the size
of the underlying list of Poly to blow
up:
And indeed it does, as you can see above. To counteract this, we can
represent our polynomial as a mapping from monics (strings of
variables) to coefficients:
newtypePoly v c =Poly { terms ::Map [v] c }
Num
instance for Map-based
polynomial
instance (Ord v, Num c) =>Num (Poly v c) wherefromInteger n =Poly (Map.singleton [] (fromInteger n))Poly xs +Poly ys =Poly (Map.unionWith (+) xs ys) xs * ys =Poly (Map.fromListWith (+) [ (xv ++ yv, xc * yc)| (xv,xc) <- Map.toList (terms xs) , (yv,yc) <- Map.toList (terms ys) ])negate=Poly.fmapnegate. terms
While this new representation is an improvement over the
un-normalised list, it’s still not really “efficient�. In particular,
we’re using lists as keys in the map; Haskell’s Map is a
binary search tree (though this caveat applies to most mapping
structures), so search is always going to have to perform comparisons on
the keys. When those keys are lists, that comparison takes time
proportional to the length of each list. This is wasted effort that
could be cached with a cleverer data structure.
This also brings the second observation about inefficiency into
focus: we have lost our neat evaluation with Horner’s rule.
eval ::Num c =>Poly v c -> (v -> c) -> ceval (Poly mp) v = Map.foldrWithKey (\vs c s ->foldr ((*) . v) c vs + s) 0 mp
We’re back to performing
<semantics>n<annotation encoding="application/x-tex">n</annotation></semantics>
multiplications per term.
Both of these inefficiencies are actually the same pattern, and can
be solved with a general form of Horner’s rule. We need to cache
prefixes: the data structure that does that best is a trie.
A Trie
Horner’s rule saved us from performing redundant multiplications by
factoring out common terms to the left. That was simple to implement in
the single-variable case, but it can still apply for multiple variables.
Take an expression like
<semantics>(2+3x−5y)2<annotation encoding="application/x-tex">(2 + 3x - 5y) ^ 2</annotation></semantics>,
and multiply it out to
<semantics>4+12x+9x2−15xy−20y−15yx+25y2<annotation encoding="application/x-tex">4 + 12x + 9x^2 - 15xy - 20y - 15yx + 25y^2</annotation></semantics>.
We can still factor this expression to remove common prefixes, like
so:
The difference between this factorisation and the list-based
polynomial we started with is that the tree representing the polynomial
only had one child. Here, we have a child for each leading term. In
terms of the data structure, where a list has a single tail in
the cons case,
dataList a =Nil|Cons a (List a)
The multivariate version of the same thing will be a
tree
dataTree a =Nil|Cons a [Tree a]
Or, more specifically, a trie, where the subtree mapping is
based on variables.
dataPoly v c = c :<+Map v (Poly v c)
A polynomial is a constant coefficient c plus the sum of variables drawn from
v each multiplied by another
polynomial. The polynomial above is represented with this type as the
following:
This trie type (with some improvements I’ll describe below) is the
focus of this post; I think it’s a cool data structure for representing
polynomials.
The numeric functions on
Tries
Let’s first write evaluation:
eval ::Num c => (v -> c) ->Poly v c -> ceval f (c :<+ vs) = c + Map.foldrWithKey (\v p s -> f v * eval f p + s) 0 vs
Notice that we have retrieved Horner’s rule: the evaluation of each
term only performs a single multiplication; we don’t have to repeat
multiplications for terms that share prefixes any more.
(for those concerned with performance, it might be worth swapping out
foldrWithKey with a strict
variant. (also, this is somewhat unrelated but a bit of a pet peeve of
mine: this is not a place where foldl' is the best option! foldl' is not a panacea!))
The numeric operations on this data structure can be implemented as
follows:
derivinginstanceFunctor (Poly v)instance (Ord v, Num c, Eq c) =>Num (Poly v c) wherefromInteger n =fromInteger n :<+ Map.empty (n :<+ ns) + (m :<+ ms) = (n + m) :<+ Map.unionWith (+) ns ms (n :<+ ns) * ms =fmap (n*) ms + (0:<+fmap (*ms) ns)negate=fmapnegate
It’s worth taking a moment to note how efficient these operations are
(for a pointer-ridden high-level language like Haskell, that is). We
don’t have to compare any strings; we can use Data.Map’s
efficient unionWith on single
variables; and multiplication doesn’t have to expand out any Cartesian
product.
I will note that we do have to perform a little bit of normalisation
for the derived Eq instance to
be correct: we have to remove terms that multiply to zeros. Pruning dead
branches like this is a pretty standard procedure on tries; in
polynomial terms, that just means we have to get rid of entries in the
map that evaluate to zero (so
<semantics>x(2+y)+y(0)<annotation encoding="application/x-tex">x(2 + y) + y(0)</annotation></semantics>
should be pruned to
<semantics>x(2+y)<annotation encoding="application/x-tex">x(2 + y)</annotation></semantics>).
This can be done without really changing the efficiency of the
operations above, but it does make them slightly more verbose.
0<+? ns | Map.null ns =Nothingn <+? ns =Just (n :<+ ns)instance (Ord v, Num c, Eq c) =>Num (Poly v c) wherefromInteger n =fromInteger n :<+ Map.empty a + b = fromMaybe 0 (add a b)where add (n :<+ ns) (m :<+ ms) = (n + m) <+? Map.merge Map.preserveMissing Map.preserveMissing (Map.zipWithMaybeMatched (const add)) ns ms _ * (0:<+ ms) | Map.null ms =0:<+ Map.empty (0:<+ ns) * ms =0:<+fmap (*ms) ns (n :<+ ns) * ms =fmap (n*) ms + (0:<+fmap (*ms) ns)negate=fmapnegateabs=fmapabssignum (n :<+ _) =signum n :<+ Map.empty
Anyways, when we have all of the above instances, we can manipulate
polynomials using the API you might expect, and the normalisation
behaviour happens automatically.
dataVar=X|Yderiving (Eq, Ord, Show)var ::Num c => v ->Poly v cvar v =0:<+ Map.singleton v (1:<+ Map.empty)x,y ::PolyVarIntegerx = var Xy = var Ypoly = (2+3* x -5* y) ^2>>> poly4+Y*(-20+Y*25+X*(-15)) +X*(12+Y*(-15) +X*9)
Lenses and Division
Lenses in
Haskell are very cool, and personally I think one of the best
demonstrations of their power is tries. A few years ago, when I was
still on Twitter, I posted an implementation of a trie that fit in a
tweet (gist
link).
Tweet Trie
{-# LANGUAGE RankNTypes #-}importControl.Comonad.CofreeimportControl.Lenshiding ((:<))importqualifiedData.MapasMapimportData.Map (Map)importPreludehiding (lookup)importData.Maybe (isJust)importTest.QuickChecktypeTrie a b =Cofree (Map a) (Maybe b)string ::Ord a => [a] ->Lens' (Trie a b) (Maybe b)string =foldr (\x r -> _unwrap . at x . anon (Nothing:<mempty) (\(v :< m) ->null v &&null m) . r) _extractinsert ::Ord a => [a] -> b ->Trie a b ->Trie a binsert xs x = string xs .~Just xlookup ::Ord a => [a] ->Trie a b ->Maybe blookup= view . stringdelete ::Ord a => [a] ->Trie a b ->Trie a bdelete xs = string xs .~Nothing
Lenses are what allowed this very terse implementation. The original
purpose of lenses was to facilitate deep access in nested records and
data structures: a trie is effectively a nested map, so it’s no great
surprise that lenses are a good fit.
It turns out that lenses are also useful for manipulating polynomial
tries. At first, it might be difficult to see why: in the trie
implementation above, a lens was used to build getters and setters for a
mapping from strings to payloads. But what does that translate to in the
context of a polynomial? What does it mean to “look up� a string of
variables in some expression like
<semantics>2x2+y<annotation encoding="application/x-tex">2x^2 + y</annotation></semantics>?
It turns out that lookups corresponds to division. For
example, dividing the polynomial
<semantics>2x2+y<annotation encoding="application/x-tex">2x^2 + y</annotation></semantics>
by the monic
<semantics>xx<annotation encoding="application/x-tex">xx</annotation></semantics>
gives us a quotient
<semantics>2<annotation encoding="application/x-tex">2</annotation></semantics>
and remainder
<semantics>y<annotation encoding="application/x-tex">y</annotation></semantics>.
>>>divMod (2* x ^2+ y) [X,X](2, y)
This is already quite similar to a lens: before the van Laarhoven
encoding, lenses were usually thought of as functions that took a data
structure and returned a pair of the “focus� of the lens and the “rest�
of the structure. In polynomial terms, that “focus� is the quotient, and
the “rest� is the remainder.
But that’s a little vague. Let’s construct the actual lenses here, in
the van Laarhoven style:
constant ::Lens' (Poly v c) cconstant f (c :<+ vs) =fmap (:<+ vs) (f c)vars ::Lens (Poly v c) (Poly v' c) (Map v (Poly v c)) (Map v' (Poly v' c))vars f (c :<+ vs) =fmap (c :<+) (f vs)isZero :: (Num c, Eq c) =>Poly v c ->BoolisZero (n :<+ ns) = (0== n) && Map.null nsfactored :: (Ord v, Num c, Eq c) => [v] ->Lens' (Poly v c) (Poly v c)factored =foldr (\v vs -> vars . at v . anon 0 isZero . vs) id
This last lens does indeed give us an interface that looks like
division:
If we want to define an actual division function, we can define it in
terms of factored, in a fun
example of the kind of golfy code that lens enables.
divMod :: (Ord v, Num c, Eq c) =>Poly v c -> [v] -> (Poly v c,Poly v c)divMod p vs = factored vs (,0) p>>> (2*x^2+ y) `divMod` [X,X](2,Y)
Gröbner Bases
While the interface above lets us do some basic computer algebra, to
do any serious work with polynomials we will have to at some point
compute Gröbner bases. A Gröbner basis is… somewhat hard to define,
actually. I’ll quote an explainer on the topic by Sturmfels (2005):
A Gröbner basis is a set of multivariate polynomials that has
desirable algorithmic properties
Basically, in several algorithms over polynomials (division, Gaussian
elimination, etc.) it becomes necessary at some point to compute this
thing called a Gröbner Basis.
There is a lot of published literature on computing Gröbner bases in
different settings. However, the trie polynomial I have built above is
fundamentally noncommutative, and the literature on computing
Gröbner bases for noncommutative rings is comparatively smaller. I have
been following Xiu’s thesis (2012) for this project. It outlines a
noncommutative version of Buchberger’s algorithm, and a few
optimisations that I was able to implement.
One slightly annoying aspect of these algorithms is that they tend to
use monomials as a primitive. In other words, instead of
working with the polynomial directly, the algorithms tend to describe
operations with the assumption that your representation is basically a
list of monomials. In particular, the algorithms will frequently extract
the “leading� monomial, and it becomes important for performance that
the polynomial representation can provide that leading monomial quickly.
Unfortunately, extraction of the leading monomial is slightly awkward on
the trie representation (or certainly less natural than the
implementation on a listed representation); so we will need to do some
work to implement it.
Monomial Orderings
The first important concept to implement for Gröbner bases is an
admissible monomial ordering. This is a total order on strings of
variables that is “admissible�; meaning that it respects concatenation
on both sides, and it also is a well-ordering, meaning that any strictly
descending chain is finite.
<semantics>a<b⟹a•c<b•c<annotation encoding="application/x-tex">a < b \implies a \bullet c < b \bullet c</annotation></semantics>
<semantics>a<b⟹c•a<c•b<annotation encoding="application/x-tex">a < b \implies c \bullet a < c \bullet b</annotation></semantics>
These constraints rule out the usual lexicographic ordering on
strings. Instead, we’ll go with graded lexicographic. This
means we first compare strings for length, and only in the case where
they’re equal do we move to the normal lexicographic comparison.
We can improve the efficiency of the above function somewhat by using
one of my favourite monoids: the monoid instance on Ordering.
grlex ::Ord a => [a] -> [a] ->Orderinggrlex = go EQwhere go !a [] [] = a go !a [] (_:_) =LT go !a (_:_) [] =GT go !a (x:xs) (y:ys) = go (a <>compare x y) xs ys
This version performs just one pass through each list, and does the
correct comparison without additionally calculating the length. It’s
also nonstrict: if one of the lists passed is infinite, this comparison
will still terminate.
Another admissible order we could use is reverse grlex,
which basically amounts to reversing the lists before the comparison.
The trie structure means that we’re basically forced to use grlex, but I will include an
implementation of grevlex here
because I think it’s cute.
Implementations of grevlex
grevlex ::Ord a => [a] -> [a] ->Orderinggrevlex [] [] =EQgrevlex (_:_) [] =GTgrevlex [] (_:_) =LTgrevlex (x:xs) (y:ys) = grevlex xs ys <>compare x y-- This version is tail-recursive, but it also might unnecessarily compare-- elements. However, that should be cheaper than building up the list of-- comparisons.grevlex ::Ord a => [a] -> [a] ->Orderinggrevlex = go EQwhere go !a [] [] = a go !a (_:_) [] =GT go !a [] (_:_) =LT go !a (x:xs) (y:ys) = go (compare x y <> a) xs ys
Enumerating Monomials
The problem with all the admissible monomial orderings is that they
need to see the entire monomial before they can decide whether it’s
ordered before or after another. This is at odds with the trie, which
tends to prefer computations that can be described in terms of
prefix/suffix decompositions.
To demonstrate the problem, let’s take a look at an algorithm that
enumerates the monomials of a polynomial in lexicographic order:
monos :: (Num c, Eq c) =>Poly v c -> [([v],c)]monos p = search [] p []where cons vs 0 ms = ms cons vs c ms = (reverse vs,c) : ms search sv (n :<+ ns) ms = cons sv n (Map.foldrWithKey (search . (:sv)) ms ns)>>> monos ((2+3*x -5*y) ^2)[([],4),([X],12),([X,X],9),([X,Y],-15),([Y],-20),([Y,X],-15),([Y,Y],25)]
Notice that the function search emits the monomial (reverse sv, n)
straight away (if n /=0),
when it encounters it: for a proper admissible monomial ordering, it
would instead want to first emit monomials of higher degree; that is,
those monomials in the map ns.
However, we can’t just flip the order of consing in search: notice that even if we
reversed the output, we still wouldn’t get an admissible monomial
ordering (the singleton list [Y] should be
grouped with the other singleton lists). The problem is that monos is performing a
depth-first search. What we need is breadth-first.
I happen to be a little obsessed with
breadth-first search, so I probably spent too much time on this
particular implementation, but I do always get excited when I see a
breadth-first traversal pop up in the wild.
For this case, I started with the levels function.
levels :: (Num c, Eq c) =>Poly v c -> [[([v],c)]]levels p = search [] p []where cons _ 0 ms = ms cons vs c ms = (reverse vs,c) : ms search sv (n :<+ ns) [] = cons sv n [] : Map.foldrWithKey (search . (:sv)) [] ns search sv (n :<+ ns) (q:qs) = cons sv n q : Map.foldrWithKey (search . (:sv)) qs ns>>> levels ((2+3*x -5*y) ^2)[[([],4)],[([X],12),([Y],-20)],[([X,X],9),([X,Y],-15),([Y,X],-15),([Y,Y],25)]]
I think it’s a good fit here because it lets us build the prefix
string for each monomial in a natural way (that prefix string is the
sv that’s passed to search).
However, one flaw of this function is that it produces a list of
lists: one inner list for each degree of polynomial. The output that I
actually want, however, is the concatenation of the whole thing.
In reality, this isn’t actually a flaw: we can just call concat and
move on. I had a feeling, though, that there was probably some annoying
circular program that would let us avoid the second traversal to
concatenate the inner lists. Inspired by Geraint Jones’ cyclic
breadth-first traversal (1993), I finally arrived at the
following solution:
dataKnots a=Knot { tied ::!Bool , yank :: [a] , ends ::Knots a }tighten ::Knots a ->Knots atighten ~(Knot t y e) =KnotFalse (if t then y else []) (tighten e)monos :: (Eq c, Num c) =>Poly v c -> [([v],c)]monos p = ywhereKnot _ y e = tie [] p (tighten e) cons sv 0 ms = ms cons sv c ms = (reverse sv, c) : ms tie sv (n :<+ m) (Knot _ ms ps) =KnotTrue (cons sv n ms) (Map.foldrWithKey (tie . (:sv)) ps m)>>> monos ((2+3* x -5* y) ^2)[([],4),([X],12),([Y],-20),([X,X],9),([X,Y],-15),([Y,X],-15),([Y,Y],25)]
While this does order the output according to grlex, it’s ordered
from smallest to largest, which is the reverse of what we want.
And yes, while we could just reverse the output, I didn’t write the
circular abomination above to throw away the single-pass traversal at
such a small hurdle. Any (list-based) algorithm written in a fold-like
fashion can usually be reversed by swapping out right-folds for
left.
pull ::Knots a -> [a]pull (KnotTrue _ e) = pull epull (KnotFalse y _) = ymonosDesc :: (Eq c, Num c) =>Poly v c -> [([v],c)]monosDesc p = pull rwhere r = tie [] p (KnotFalse [] (tighten r)) cons sv 0 ms = ms cons sv c ms = (reverse sv, c) : ms tie sv (n :<+ m) (Knot _ ms ps) =KnotTrue (cons sv n ms) (Map.foldlWithKey (\a v p -> tie (v:sv) p a) ps m)
Efficiently Popping
the Leading Monomial
Unfortunately, as fun as monosDesc is, it doesn’t really do
what we need it to for most of the Gröbner basis algorithms. While it is
pretty efficient if we want all of the monomials of a
polynomial, usually we just want the first one. And sadly,
while monosDesc is linear
overall, it’s not lazy in the right way, meaning that we have to pay
that full linear cost even if we only inspect the first element of the
list it produces.
The solution here will require us to use a new data structure in
place of the Map that we
have currently. To avoid traversing the whole tree to find the largest
monomial, we need to cache the depth of each subterm so that we can just
descend into the subterm which contains the monomial of the highest
degree. But we don’t want to just swap out our Map v (Poly v c)
for a Map v (Word, Poly v c):
that solution would require us to walk over every entry in the map to
find the largest Word. While it
would be an improvement in practical terms, it would still incur an
<semantics>�(width×depth)<annotation encoding="application/x-tex">\mathcal{O}(\text{width} \times \text{depth})</annotation></semantics>
cost to find the leading monomial.
Instead, we need the map itself to be able to efficiently provide the
entry with the largest degree. We need our map to simultaneously act as
a priority queue.
Luckily, the combination of these two structures has been researched
before: Hinze (2001)
wrote about “priority search trees�, a data structure that allows for
<semantics>�(logn)<annotation encoding="application/x-tex">\mathcal{O}(\log n)</annotation></semantics>
lookup and insertion based on some ordered key, and separately allows
for a
<semantics>�(logn)<annotation encoding="application/x-tex">\mathcal{O}(\log n)</annotation></semantics>
popMin operation, based on some
separate priority. The psqueues package provides a few
implementations of this technique. The API isn’t quite as extensive as,
say, containers, so some functions will
be slightly less efficient (we don’t get a nice general merge function, for example), but we
can basically drop in the OrdPSQ as a
replacement for Map.
typeSubTerms v c =OrdPSQ (Down v) (DownWord) (Poly v c)dataPoly v c = c :<+SubTerms v c
I’m using the Down
wrapper here because I want a max heap, rather than a
min-heap. I’m using that wrapper on both the keys and priorities because
OrdPSQ
breaks priority ties according to the keys, and I also want greater keys
returned first, to follow the grlex ordering.
The priority here is the depth of the tree. It tells us the
length of the longest monomial contained:
depth ::Poly v c ->Worddepth (_ :<+ ns) =maybe0 (\(_,Down p,_) ->succ p) (Map.findMin ns)
This operation is
<semantics>�(1)<annotation encoding="application/x-tex">\mathcal{O}(1)</annotation></semantics>,
since finding the minimum entry in OrdPSQ is
<semantics>�(1)<annotation encoding="application/x-tex">\mathcal{O}(1)</annotation></semantics>.
I’ll also use the following isomorphism, for the lensy things:
entry :: (Num c, Eq c) =>Iso' (Maybe (DownWord, Poly v c)) (Poly v c)entry = iso (maybe (0:<+ Map.empty) snd) (\p ->if isZero p thenNothingelseJust (Down (depth p), p))
This lets us chain together lenses that index into an OrdPSQ.
factored :: (Ord v, Num c, Eq c) => [v] ->Lens' (Poly v c) (Poly v c)factored =foldr (\v ls -> vars . at (Down v) . entry . ls) id
Finally, we can implement a function that pops the leading monomial
from a polynomial, efficiently:
leading :: (Num c, Eq c, Ord v) =>Poly v c ->Maybe (([v],c),Poly v c)leading p | isZero p =Nothingleading (n :<+ ns) =Just (retrie (Map.alterMin step ns))where retrie ((r,n'),ns') = (r, n' :<+ ns') step Nothing= ((([],n),0),Nothing) step (Just (Down v, _, p)) = (((v:vs,c),n), subTrie)whereJust ((vs,c),p') = leading p subTrie | isZero p' =Nothing|otherwise=Just (Down v, Down (depth p'), p')
And it matches the earlier enumeration that we built:
prop_leadingMonos ::PolyVarWord->Propertyprop_leadingMonos p = monosDesc p === unfoldr leading p
Next Steps
I think this is an interesting data structure, and representation of
polynomials. However, I am not very familiar with the computer algebra
literature, so I can’t yet tell how this kind of representation relates
to the other systems out there. Furthermore, most of the algorithms I
have read seem to work implicitly with “leading monomials� etc., leading
to the following kind of implementation of division:
divModPrefM :: (Fractional c, Eq c, Ord v) =>Poly v c -> ([v],c) -> (Poly v c, Poly v c)divModPrefM p (vs, i) = factored vs ((, 0) .fmap (/i)) pdivModPref :: (Fractional c, Eq c, Ord v) =>Poly v c ->Poly v c -> (Poly v c, Poly v c)divModPref num divisor =case leading divisor ofNothing->error"Divide by zero"Just (lt, rest) -> go 0 numwhere go !quot!rem=case divModPrefM rem lt of (0, _) -> (quot, rem) (q, rem') -> go (quot+ q) (rem' - rest * q)
I feel that this doesn’t make use of the benefits of the trie-based
representation. I have implemented Buchberger’s algorithm (with most of the
improvements from Xiu 2012), but I have yet to really
research in depth what competitively fast systems do these days (Heisinger and
Hofstadler 2025; Cohen and Knopper 2026; Levandovskyy, Schönemann, and Zeid
2020). I’m also interested in seeing what kinds of
applications there are for this stuff: I started this project with Weyl
algebras in mind, but after looking into it a little more it seems clear
that a trie is not a good fit for Weyl algebras.
I have looked a little bit at some other Haskell work on polynomials
and similar things; Zucker (2018)
implemented listed polynomials very similar to the ones I had at the
start of this post, as did Manzyuk (2012)
and Buteau
(2013). I’ve seen some bigger Haskell
packages that work with polynomials (Malaquias
and Lopes 2007; Ishii 2018; Laurent 2024), though none seem to use a
representation similar to the trie here. I also had a look at calculi
(Barton
2024), but I think that that project mainly works with
commutative rings (although it’s pretty big project, so I wouldn’t be
surprised if there was some module I missed).
I would actually be interested to hear if anyone has any pointers to
work that has a similar approach to polynomials, or on the kinds of
things that people use these noncommutative polynomials for. I find most
of the descriptions of these algorithms difficult to parse (since
they’re usually written by and for mathematicians rather than computer
scientists, and almost never for functional programmers), so I am sure
I’m missing some major projects.
Levandovskyy, Viktor, Hans Schönemann, and Karim Abou Zeid. 2020.
“Letterplace: A subsystem of singular for computations with free
algebras via letterplace embedding.� In Proceedings of the
45th International Symposium on Symbolic and
Algebraic Computation, 305–311. ISSAC
’20. New York, NY, USA: Association for Computing Machinery. doi:10.1145/3373207.3404056.
I want to return to something I've mentioned a couple of times in the past - the fact that applying certain type constructors performs a tensor product.
First some admin stuff:
> {-# LANGUAGE DeriveFunctor #-}
> {-# LANGUAGE FlexibleInstances #-}
> {-# LANGUAGE MultiParamTypeClasses #-}
> {-# LANGUAGE UndecidableInstances #-}
> {-# LANGUAGE TypeApplications #-}
> {-# LANGUAGE KindSignatures #-}
> {-# LANGUAGE ScopedTypeVariables #-}
> {-# LANGUAGE AllowAmbiguousTypes #-}
> import Data.Proxy
> import Data.Kind (Type)
> infixr 7 ⊗
Suppose you define a type like so:
> data Complex a = C a a
> deriving (Eq, Show, Functor)
> instance Num a => Num (Complex a) where
> fromInteger n = C (fromInteger n) 0
> C a b + C c d = C (a + c) (b + d)
> C a b - C c d = C (a - c) (b - d)
> C a b * C c d = C (a * c - b * d) (a * d + b * c)
> negate (C a b) = C (negate a) (negate b)
> abs = error "abs doesn't make sense here"
> signum = error "signum makes no sense here"
It seems straightforward. You've defined complex numbers in a way that allows a choice of base type to represent the real numbers. For example you could use Complex Float or Complex Double as representations of \(\mathbb{C}\).
In actual fact you've done quite a bit more! That code has another reading - it implements a tensor product both in the category of vector spaces, and, less trivially, in the category of algebras. So if A is a suitable algebraic structure then, if you allow me to mix code and mathematics notation,
I took this for granted when I mentioned it previously but I thought I'd look into it in a little bit more detail.
Tensor Products
I want to start from the definition of the tensor product given by its universal property, but to make that slightly less fearsome I'll use an English sketch of it.
Suppose you have a pair of vector spaces \(X\) and \(Y\) over some base field \(k\). A bilinear function \(X\times Y\rightarrow Z\) is a function that is linear in \(X\) and linear in \(Y\). Now suppose we know that at some point in the future we are going to need some bilinear function on \(X\times Y\) but don't yet know what it is. Can we make a structure, \(T\), that contains precisely the information we need so that we can compute any bilinear function we want - with the proviso that we compute these bilinear functions by applying a linear function to \(T\)? We don't want \(T\) to be lacking anything we might need to compute a future bilinear product, but we also don't want it to contain any extraneous data.
For example, imagine working with \(V\), the vector space of 3D vectors. Some examples of bilinear functions we might want are the dot product \(V\cdot V\rightarrow\mathbb{R}\) and the cross product \(V\times V\rightarrow V\). What should \(T\) look like?
We can write the dot product as \((x, y, z)\cdot(x', y', z') = xx'+yy'+zz'\). Note how it's made of products of coordinates from \((x, y, z)\) and coordinates from \((x', y', z')\). Similarly \((x, y, z)\times(x', y', z')=(yz'-zy',\ldots)\). Again, it's a linear combination of products of coordinates, one from each vector. You can prove that any bilinear product will be some linear combination of such products.
By thinking about all possible bilinear products you I hope you can see that \(T\) should be a 9-dimensional vector space and a suitable way to represent a pair of vectors \((x, y, z), (x', y', z')\) for future application of a bilinear function is as \((xx', xy', xz', yx', yy', yz', zx', zy', zz')\). Any bilinear product is a linear combination of these 9 quantities and so is given by some linear operation on \(T\). It is commonplace to arrange the 9-dimensional vector as a \(3\times 3\) matrix in which case the map from the pair is called the outer product. But it doesn't really matter as all 9-dimensional vector spaces over a given field are isomorphic.
In this case I chose to consider bilinear functions on \(V\times V\), but you can reason similarly for any pair of vector spaces \(X\) and \(Y\). When working with finite-dimensional vector spaces, the structure we need will be \(mn\)-dimensional where \(m\) is the dimension of \(X\) and \(n\) is the dimension of \(Y\). The structure is called the tensor product and is written as \(X\otimes Y\). The bilinear map from the original vectors into the tensor product is also called the tensor product and as written as a binary operator \(x\otimes y\). And once you have the tensor product, every bilinear function on the original pair of spaces can be expressed uniquely as a linear function on the tensor product.
So, for example, the dot product can be written as
\[
x\cdot y = \phi(x\otimes y)
\]
where \((x, y, z)\otimes(x', y', z')=(xx',xy',\ldots zz')\) and so the linear function is \(\phi(x_0, x_1,\ldots,x_8) = x_0+x_4+x_8\).
It's a confusing use of terminology, but the term "algebra (over \(k\))" is used specifically to mean a vector space \(A\) (over \(k\)) equipped with a bilinear product \(A\times A\rightarrow A\) which is compatible with the vector space structure. And in addition I'm assuming my algebras contain a multiplicative unit element. Other people may call this a "unital algebra". I'll use the word "unital" when I want to stress that there is a unit.
An example is the algebra of complex numbers \(\mathbb{C}\) over \(\mathbb{R}\). It's a 2-dimensional vector space over \(\mathbb{R}\). We can, for example, scale complex numbers by elements of the base field. We also have properties like \((au)v = u(av)\) for \(a\in\mathbb{R}\) and \(u,v\in\mathbb{C}\). We can scale either argument of the complex product by a real and it makes no difference which we choose. See Wikipedia for all the properties an algebra must satisfy.
Vector spaces come with an addition operation and a zero but we're going to share the work out a little differently because our Num instance already has those. So our VectorSpace class is just going to have the scale operation:
> class VectorSpace k v where
> scale :: k -> v -> v
> instance VectorSpace Double Double where
> scale = (*)
You can think of the definition of Complex above as a container for the coordinates in a choice of basis. Because I use deriving Functor I can get the VectorSpace instance for all similar types for free:
> instance (Functor c, VectorSpace k a) => VectorSpace k (c a) where
> scale k = fmap (scale k)
Because fmap composes through nested functors, scale descends recursively through arbitrarily nested structures like Complex (Complex Double).
And now we can concretely implement the bilinear tensor product operation in our choice of basis. It works by descending through the construction of \(x\) until it reaches its individual coordinates and then uses each one to scale \(y\). A special case of this is our 9-dimensional vector construction above: each batch of 3 coordinates is s scaling of one vector by a coordinate from the other.
> (⊗) :: (Functor c, VectorSpace k a) => c k -> a -> c a
> x ⊗ y = fmap (`scale` y) x
We're literally just recursively building a table of all products of coordinates of c k and coordinates of a.
Any bilinear function f :: U -> V -> W can now be implemented as f x y = phi (x ⊗ y) for a unique choice of phi.
Algebras too
But there's more, and this is the point of me writing this article. Algebras also have a tensor product defined on them. The underlying carrier space is the tensor product of algebras considered as vector spaces. The product structure is defined by \((x\otimes y)(x'\otimes y')=(xx')\otimes(yy')\) and linear combinations thereof. But what's neat here is that we don't have to write any more code to implement this, our Num instance is already doing the work.
We need to check that our definition of Complex satisfies this property. In fact, I want to prove it more generally for any type like Complex that has a multiplication that looks like
C a b * C c d = C (a * c - b * d) (a * d + b * c)
ie. I'll assume we have a type F that is an instance of Num, with constructor F, and whose multiplication is constructed from a linear combination of terms of the form a * a'.
Something like:
(F ... a ...) * (F ... a' ...) = F ... (... + a * a' + ...) ...
so I can suppose that a is in Double (or whatever we use to represent the reals).
Assuming * is such a product:
(x ⊗ y) * (x' ⊗ y')
== fmap (`scale` y) x * fmap (`scale` y') x'
-- definition of tensor
== fmap (`scale` y) (F ... a ...) * fmap (`scale` y') (F ... a' ...)
-- stating our assumptions about the form of x and x'
== (F ... (scale a y) ...) * (F ... (scale a' y') ...)
-- this is what derived fmap looks like
== F ... (... + scale a y * scale a' y' + ...) ...
-- our assumption about the form that multiplication takes
== F ... (... + scale (a * a') (y * y') + ...) ...
-- multiplication is bilinear all the way down
== fmap (`scale` (y * y')) (F ... (... + a * a' + ...))
-- same fact about fmap used above
== fmap (`scale` (y * y')) (x * x')
-- again our assumption about how multiplication is implemented
== (x * x') ⊗ (y * y')
-- definition of tensor again
Anyway, my motivation here is that quite a while back someone (on Mastodon) I think pushed back on my claim that we have a tensor product so I thought I'd give some more detail.
I could say more. The tensor product of algebras has the nice property that you can embed the original algebras in it in a way that the two images commute with each other. In fact, if you can define the tensor product to be the initial algebra with this property. But this is too long already.
Also, I used Haskell above but it carries over straightforwardly to other languages, even C++.
Mike and Andres sat down with Torsten Grust, who is a professor of DB systems at the University of Tübingen. Even though Torsten loves SQL, he's used functional programming and Haskell to inform his work on query language design and compilation. We talked about the best way to program databases, how to bridge the gap between regular programming languages and databases, and compiling just about everything to SQL.
In those articles I showed how you could build up the Clifford algebras like so:
type Cliff1 = Complex R
type Cliff1' = Split R
type Cliff2 = Quaternion R
type Cliff2' = Matrix R
type Cliff3 = Quaternion Cliff1'
type Cliff3' = Matrix Cliff1
type Cliff4 = Quaternion Cliff2'
type Cliff4' = Matrix Cliff2
type Cliff5 = Quaternion Cliff3'
...
I used CliffN as the Clifford algebra for a negative definite inner product and
CliffN' for the positive definite case.
It's not a completely uniform sequence in the sense that CliffN is built from CliffN' for dimension two lower and you use a mix of Matrix and Quaternion.
The core principle making this work is that for type constructors implemented like Matrix, Quaternion etc. we have the property that
eg. Matrix (Quaternion Float) is effectively the same thing as Matrix FloatQuaternion Float.
But John Baez pointed out to me that you can build up the CliffN algebras much more simply enabling us to use these definitions:
> type Cliff1 = Complex Float
> type Cliff2 = Complex Cliff1
> type Cliff3 = Complex Cliff2
> type Cliff4 = Complex Cliff3
> type Cliff5 = Complex Cliff4
...
Or even better:
> type family Cliff (n :: Nat) :: * where
> Cliff 0 = Float
> Cliff n = Complex (Cliff (n - 1))
But there's one little catch.
We have to work, not with the tensor product, but the super tensor product.
We define Complex the same way as before:
> data Complex a = C a a deriving (Eq, Show)
Previously we used a definition of multiplication like this:
instance Num a => Num (Complex a) where
C a b * C c d = C (a * c - b * d) (a * d + b * c)
We can think of C a b in Complex R as representing the element \(1\otimes a+i\otimes b\). The definition of multiplication in a tensor product of algebras is
This means that line of code we wrote above defining * for Complex isn't simply a definition of multiplication of complex numbers, it says how to multiply in an algebra tensored with the complex numbers.
Let's go Super!
A superalgebra is an algebra graded by where is the ring of integers modulo 2.
What that means is that we have some algebra that can be broken down as a direct sum (the subscripts live in ) with the property that multiplication respects the grading, ie. if is in and is in then is in .
The elements of are called "even" (or bosonic) and those in "odd" (or fermionic). Often even elements commute with everything and odd elements anticommute with each other but this isn't always the case. (The superalgebra is said to be supercommutative when this happens. This is a common pattern: a thing X becomes a superX if it has odd and even parts and swapping two odd things introduces a sign flip.)
The super tensor product is much like the tensor product but it respects the grading.
This means that if is in and is in then is in .
From now on I'm using to mean super tensor product.
Multiplication in the super tensor product of two superalgebras and is now defined by the following modified rule:
if is in and is in then .
Note that the sign flip arises when we shuffle an odd left past an odd .
The neat fact that John pointed out to me is that
\[Cliff_n=\mathbb{C}\otimes\mathbb{C}\otimes\ldots\text{ n times }\ldots\otimes\mathbb{C}.\]
We have to modify our definition of * to take into account that sign flip.
I initially wrote a whole lot of code to define a superalgebra as a pair of algebras with four multiplication operations and it got a bit messy.
But I noticed that the only specifically superalgebraic operation I ever performed on an element of a superalgebra was negating the odd part of an element.
So I could define SuperAlgebra like so:
class SuperAlgebra a where
conjugation :: a -> a
where conjugation is the negation of the odd part.
(I'm not sure if this operation corresponds to what is usually called conjugation in this branch of mathematics.)
But there's a little efficiency optimization I want to write.
If I used the above definition, then later I'd often find myself computing a whole lot of negates in a row.
This means applying negate to many elements of large algebraic objects even
though any pair of them cancel each other's effect.
So I add a little flag to my conjugation function that is used to say we want an extra negate and we can
accumulate flips of a flag rather than flips of lots of elements.
> class SuperAlgebra a where
> conjugation :: Bool -> a -> a
Here's our first instance:
> instance SuperAlgebra Float where
> conjugation False x = x
> conjugation True x = negate x
This is saying that the conjugation is the identity on Float but if we
want to perform an extra flip we can set the flag to True.
Maybe I should call it conjugationWithOptionalExtraNegation.
And now comes the first bit of non-trivial superalgebra:
> instance (Num a, SuperAlgebra a) => SuperAlgebra (Complex a) where
> conjugation e (C a b) = C (conjugation e a) (conjugation (not e) b)
We consider to be even and to be odd. When we apply the conjugation to then we can just apply it directly to .
But that flips the "parity" of (because tensor product respects the grading) so we need to swap when we use the conjugation.
And that should explain why conjugation is defined the way it is.
Now we can use the modified rule for defined above:
> instance (Num a, SuperAlgebra a) => Num (Complex a) where
> fromInteger n = C (fromInteger n) 0
> C a b + C a' b' = C (a + a') (b + b')
> C a b * C c d = C (a * c - conjugation False b * d)
> (conjugation False a * d + b * c)
> negate (C a b) = C (negate a) (negate b)
> abs = undefined
> signum = undefined
For example, conjugation False is applied to the first on the RHS because implicitly represents an term and when expanding out the product we shuffle the (odd) in left of . It doesn't get applied to the second because and remain in the same order.
That's it!
Tests
I'll test it with some examples from Cliff3:
> class HasBasis a where
> e :: Integer -> a
> instance HasBasis Float where
> e = undefined
> instance (Num a, HasBasis a) => HasBasis (Complex a) where
> e 0 = C 0 1
> e n = C (e (n - 1)) 0
> make a b c d e f g h =
> C (C (C a b) (C c d))
> (C (C e f) (C g h))
The implementation of multiplication looks remarkably like it's the Cayley-Dickson construction.
It can't be (because iterating it three times gives you a non-associative algebra but the Clifford algebras are associative).
Nonetheless, I think comparison with Cayley-Dickson may be useful.
Efficiency
As mentioned above, before I realised I just needed the conjugation operation I wrote the above code with an explicit split of a superalgebra into two pieces intertwined by four multiplications.
I think the previous approach may have a big advantage - it may be possible to use variations on the well known "speed-up" of complex multiplication that uses three real multiplications instead of four.
This should lead to a fast implementation of Clifford algebras.
Also be warned: you can kill GHC if you turn on optimization and try to multiply elements of high-dimensional Clifford algebras.
I think it tries to inline absolutely everything and you end up with a block of code that grows exponentially with .
Note also that this code translates directly into many languages.
TL;DR The behaviour of a certain kind of delay component has a formal similarity to Löb's theorem which gives a way to embed part of provability logic into electronic circuits.
If it's false then it's true and if it's true then it's false.
Here's a paradoxical electronic circuit:
The component in the middle is an inverter. If the output of the circuit is high then its input is high and then it's output must be low, and vice versa.
There's a similarity here.
But with a bit of tweaking you can turn the similarity into an isomorphism of sorts.
In the first case we avoid paradox by noting that in the mathematical frameworks commonly used by mathematicians it's impossible, in general, for a statement to assert it's own falsity.
Instead, a statement can assert its own unprovability and then we get Gödel's incompleteness theorems and a statement that is apparently true and yet can't be proved.
In the second case we can't model the circuit straightforwardly as a digital circuit.
In practice it might settle down to a voltage that lies between the official high and low voltages so we have to model it as an analogue circuit.
Or instead we can introduce a clock and arrange that the feedback in the circuit is delayed.
We then get an oscillator circuit that can be thought of as outputting a stream of bits.
The observation I want to make is that if the feedback delay is defined appropriately, these two scenarios are in some sense isomorphic.
This means that we can model classic results about provability, like Gödel's incompleteness theorems, using electronic circuits.
We can even use such circuits to investigate what happens when logicians or robots play games like Prisoner's Dilemma.
I'll be making use of results found in Boolos' book on The Logic of Provability and some ideas I borrowed from Smoryński's paper on Fixed Point Algebras.
I'll be assuming the reader has at least a slight acquaintance with ithe ideas behind provability logic.
Provability Logic
There are many descriptions of provability logic (aka GL) available online, so I'm not going to repeat it all here.
However, I've put some background material in the appendix below and I'm going to give a very brief reminder now.
Start with (classical) propositional calculus which has a bunch of variables with names like \(a, b, c, d, \ldots\) and connectives like \(\wedge\) for AND, \(\vee\) for OR, \(\neg\) for NOT and \(\rightarrow\) for implication. (Note that \(a\rightarrow b = \neg a\vee b\).)
Provability logic extends propositional calculus by adding a unary operator \(\Box\).
(I apologise, that's meant to be a □ but it's coming out like \(\Box\) in LaTeX formulae.
I think it's a bug in Google's LaTeX renderer.)
The idea is that \(\Box p\) asserts that \(p\) is provable in Peano Arithmetic, aka PA.
In addition to the axioms of propositional calculus we have
as well as a rule that allows us to deduce \(\Box p\) from \(p\).
We also have this fixed point property:
Let \(F(p)\) be any predicate we can write in the language of GL involving the variable \(p\), and suppose that every appearance of \(p\) in \(F(p)\) is inside a \(\Box\), e.g. \(F(p)=\Box p\vee\Box(\neg p)\). Then there is a fixed point, i.e. a proposition \(q\) that makes no mention of \(p\) such that \(q\leftrightarrow F(q)\) is a theorem.
In effect, for any such \(F\), \(q\) is a proposition that asserts \(F(q)\).
See the appendix for a brief mention of why we should expect this to be true.
From the fixed point property we can deduce Löb's theorem: \(\Box(\Box p\rightarrow p)\rightarrow\Box p\).
There is a proof at wikipedia that starts from the fixed point property.
We can also deduce the fixed point property from Löb's theorem so it's more usual to take Löb's theorem as an axiom of GL and show that the fixed point property follows.
You can think of Löb's theorem as a cunning way to encode the fixed point property.
In fact you can argue that it's a sort of Y-combinator, the function that allows the formation of recursive fixed points in functional programming languages.
(That's also, sort of, the role played by the loeb function I defined way back.
But note that loeb isn't really a proof of Löb's theorem, it just has formal similarities.)
Back to electronic circuits
In order to make digital circuits with feedback loops well-behaved I could introduce a circuit element that results in a delay of one clock cycle.
If you insert one of these into the inverter circuit I started with you'll end up with an oscillator that flips back and forth between 0 and 1 on each clock cycle.
But I want to work with something slightly stricter.
I'd like my circuits to eventually stop oscillating.
(I have an ulterior motive for studying these.)
Let me introduce this component:
It is intended to serve as a delayed latch and I'll always have the flow of data being from left to right.
The idea is that when it is switched on it outputs 1.
It keeps outputting 1 until it sees a 0 input.
When that happens, then on the next clock cycle its output drops to 0 and never goes back up to 1 until reset.
Because the output of our delay-latch isn't a function of its current input, we can't simply describe its operation as a mathematical function from \(\{0,1\}\) to \(\{0,1\}\).
Instead let's think of electronic components as binary operators on bitstreams, i.e. infinite streams of binary digits like ...00111010 with the digits emerging over time starting with the one written on the right and working leftwards.
The ordinary logic gates perform bitwise operations which I'll represent using the operators in the C programming language.
For example,
...001110 & ...101010 = ...001010
and
~...101 = ...010
and so on.
Let's use □ to represent the effect of latch-delay on a bitstream.
We have, for example,
□...000 = ...001
and
□...11101111 = ...00011111.
The operator □ takes the (possibly empty) contiguous sequence of 1's at the end of the bitstream, extends it by one 1, and sets everything further to the left to 0.
If we restrict ourselves to bitstreams that eventually become all 0's or all 1's on the left, then bitstreams are in one-to-one correspondence with the integers using the twos complement representation.
For example ...111111, all 1's, represents the number -1.
I'll simply call the bistreams that represent integers integers.
With this restriction we can use a classic C hacker trick to write □p=p^(p+1) where ^ is the C XOR operator.
The operator □ outputs the bits that get flipped when you add one.
Let's use the symbol → so that a → b is shorthand for ~a|b.
Here are some properties of □:
1. □(-1) = -1
2. □p → □□p = -1
3. □(p → q) → □p → □q = -1
In addition we have the fixed point property:
Let F(p) be any function of p we can write using □ and the bitwise logical operators and such that all occurrences of p occur inside □.
Then there is a unique bitstream q such that q=F(q).
We can make this clearer if we return to circuits.
F(p) can be thought of as a circuit that takes p as input and outputs some value.
We build the circuit using only boolean logic gates and delay-latch.
We allow feedback loops, but only ones that go through delay-latches.
With these restrictions it's pretty clear that the circuit is well-behaved and deterministically outputs a bitstream.
We also have the Löb property:
4. □(□p → p) → □p = -1
We can see this by examining the definition of □.
Intuitively it says something like "once □ has seen a 0 input then no amount of setting input bits to 1 later in the stream make any different to its output".
I hope you've noticed something curious.
These properties are extremely close to the properties of \(\Box\) in GL.
In fact, these electronic circuits form a model of the part of GL that doesn't involve variable names, i.e. what's known as letterless GL.
We can formalise this:
1. Map \(\bot\) to a wire set to 0, which outputs ...000 = 0.
2. Map \(\top\) to a wire set to 1, which outputs ...111 = -1.
3. Map \(p \circ q\), where \(\circ\) is a binary connective, by creating a circuit that takes the outputs from the circuits for \(p\) and \(q\) and passes them into the corresponding boolean logic gate.
4. Map \(\Box p\) to the circuit for \(p\) piped through a delay-latch.
For example, let's convert \(\Box(\Box\bot\rightarrow\bot)\rightarrow\Box\bot\) into a circuit. I'm translating \(a\rightarrow b\) to the circuit for \(\neg a\vee b\).
I'm using red wires to mean wires carrying the value 1 rather than 0.
I hope you can see that this circuit eventually settles into a state that outputs nothing but 1s.
We have this neat result:
Because delay-latch satisfies the same equations as \(\Box\) in provability logic, any theorem, translated into a circuit, will produce a bistream of just 1s, i.e. -1.
But here's a more surprising result: the converse is true.
If the circuit corresponding to a letterless GL proposition produces a bistream of just 1s then the proposition is actually a theorem of GL.
I'm not going to prove this.
(It's actually a disguised form of lemma 7.4 on p.95 of Boolos' book.)
In the pictured example we got ...1111, so the circuit represents a theorem.
As it represents Löb's theorem for the special case \(p=\bot\) we should hope so.
More generally, any bitstream that represents an integer can be converted back into a proposition that is equivalent to the original proposition.
This means that bitstreams faithfully represent propositions of letterless GL.
I'm not going to give the translation here but it's effectively given in Chapter 7 of Boolos.
I'll use \(\psi(p)\) to represent the translation from propositions to bitstreams via circuits that I described above.
Use \(\phi(b)\) to represent the translation of bitstream \(b\) back into propositions.
We have \(p\leftrightarrow\phi(\psi(p))\).
But I haven't given a full description of \(\phi\) and I haven't proved here that it has this property.
Circuits with feedback
In the previous section I considered letterless propositions of GL.
When these are translated into circuits they don't have feedback loops.
But we can also "solve equations" in GL using circuits with feedback.
The GL fixed point theorem above says that we can "solve" the equation \(p\leftrightarrow F(p)\), with one letter \(p\), to produce a letterless proposition \(q\) such that \(q\leftrightarrow F(q)\).
Note here that \(p\) is a letter in the language of GL.
But I'm using \(q\) to represent a proposition in letterless GL.
If we build a circuit to represent \(F\), and feed its output back into where \(p\) appears, then the output bitstream represents the fixed point.
Here's a translation of the equation \(p \leftrightarrow \neg(\Box p \vee \Box\Box\Box p)\):
I'll let you try to convince yourself that such circuits always eventually output all 0's or all 1's.
When we run the circuit we get the output ...1111000 = -8.
As this is not -1 we know that the fixed point isn't a theorem.
If I'd defined \(\phi\) above you could use it to turn the bitstream back into a proposition.
The same, syntactically (optional section)
I have a Haskell library on github for working with GL: provability.
This uses a syntactic approach and checks propositions for theoremhood using a tableau method.
We can use it to analyse the above example with feedback.
I have implemented a function, currently called value', to perform the evaluation of the bitstream for a proposition.
However, in this case the fixedpoint function computes the fixed point proposition first and then converts to a bitstream rather than computing the bitstream directly from the circuit for F:
> let f p = Neg (Box p \/ Box (Box (Box p)))
> let Just p = fixedpoint f
> p
Dia T /\ Dia (Dia T /\ Dia (Dia T /\ Dia T))
> value' p
-8
(Note that Dia p means \(\Diamond p = \neg\Box\neg p\).)
The function fixedpoint does a lot of work under the hood.
(It uses a tableau method to carry out Craig interpolation.)
The circuit approach requires far less work.
Applications
1. Programs that reason about themselves
In principle we can write a program that enumerates all theorems of PA.
That means we can use a quine trick to write a computer program that searches for a proof, in PA, of its own termination. Does such a program terminate?
We can answer this with Löb's theorem.
Let \(p =\) "The program terminates".
The program terminates if it can prove its termination.
Formally this means we assume \(\Box p\rightarrow p\).
Using one of the derivation rules of GL we get \(\Box(\Box p\rightarrow p)\).
Löb's theorem now gives us \(\Box p\).
Feed that back into our original hypothesis and we get \(p\).
In other words, we deduce that our program does in fact terminate.
(Thanks to Sridhar Ramesh for pointing this out to me.)
But we can deduce this using a circuit.
We want a solution to \(p\leftrightarrow \Box p\).
Here's the corresponding circuit:
It starts by outputting 1's and doesn't stop.
In other words, the fixed point is a theorem.
And that tells us \(p\) is a theorem.
And hence that the program terminates.
2. Robots who reason about each others play in Prisoner's Dilemma
For the background to this problem see Robust Cooperation in the Prisoner's Dilemma at LessWrong.
We have two robot participants \(A\) and \(B\) playing Prisoner's Dilemma.
Each can examine the other's source code and can search for proofs that the opponent will cooperate.
Suppose each robot is programmed to enumerate all proofs of PA and cooperate if it finds a proof that its opponent will cooperate.
Here we have \(p =\) "A will cooperate" and \(q =\) "B will cooperate".
Our assumptions about the behaviour of the robots are \(p \leftrightarrow \Box q\) and \(q \leftrightarrow \Box p\), and hence that \(p \leftrightarrow \Box\Box p\).
This corresponds to the circuit:
This outputs ...1111 = -1 so we can conclude \(p\) and hence that these programs will cooperate.
(Note that this doesn't work out nicely if robot B has a program that doesn't terminate but whose termination isn't provable in the formal system A is using.
That means this approach is only good for robots that want to cooperate and want to confirm such cooperation. See the paper for more on this.)
At this point I really must emphasise that these applications are deceptively simple.
I've shown how these simple circuits can answer some tricky problems about provability.
But these aren't simply the usual translations from boolean algebra to logic gates.
They work because circuits with delay-latch provide a model for letterless provability logic and that's only the case because of a lot of non-trivial theorem proving in Boolos that I haven't reproduced here.
You're only allowed to use these simple circuits once you've seen the real proofs :-)
Things I didn't say above
1. I described the translation from propositions to circuits that I called \(\psi\) above.
But I didn't tell you what \(\phi\) looks like.
I'll leave this as an exercise.
(Hint: consider the output from the translation of \(\Box^n\bot\) into a circuit.)
2. The integers, considered as bistreams, with the bitwise operators, and the unary operator □p=p^(p+1), form an algebraic structure.
For example, if we define ⋄p=~□~p we have a Magari algebra.
Structures like these are intended to capture the essential parts of self-referential arguments in an algebraic way.
3. Because of the interpretation of □ as a delayed latch in a circuit you could view it as saying "my input was always true until a moment ago".
This surely embeds provability logic in a temporal logic of some sort.
4. (Deleted speculations about tit-for-tat that need rethinking.)
5. For even the most complex letterless proposition in Boolos you could check its theoremhood with a pretty small circuit.
You could even consider doing this with a steam powered pneumatic circuit.
I had to say that to fulfil a prophecy and maintain the integrity of the timeline.
Appendix on provability
The modern notion of a proof is that it is a string of symbols generated from some initial strings called "axioms" and some derivation rules that make new strings from both axioms and strings you've derived previously.
Usually we pick axioms that represent "self-evident" truths and we pick derivation rules that are "truth-preserving" so that every proof ends at a true proposition of which it is a proof.
The derivation rules are mechanical in nature: things like "if you have this symbol here and that symbol there then you can replace this symbol with that string you derived earlier" etc.
You can represent strings of symbols using numbers, so-called Gödel numbers.
Let's pick a minimal mathematical framework for working with numbers: Peano Arithmetic, aka PA.
Let's assume we've made some choice of Gödel numbering scheme and when \(p\) is a proposition, write \([p]\) for the number representing \(p\).
You can represent the mechanical derivation rules as operations on numbers.
And that makes it possible to define a mathematical predicate \(Prov\) that is true if and only if its argument represents a provable proposition.
In other words, we can prove \(Prov([p])\) using PA if and only if \(p\) is a proposition provable in PA.
The predicate \(Prov\) has some useful properties:
1.If we can prove \(p\), then we can prove \(Prov([p])\).
We take the steps we used to prove \(p\), and convert everything to propositions about numbers.
If \(Prov\) is defined correctly then we can convert that sequence of numbers into a sequence of propositions about those numbers that makes up a proof of \(Prov(p)\).
2.\(Prov([p\rightarrow q])\) and \(Prov([p])\) imply \(Prov([q])\)
A fundamental step in any proof is modus ponens, i.e. that \(p\rightarrow q\) and \(q\) implies \(p\).
If \(Prov\) does its job correctly then it had better know about this.
3.\(Prov([p])\) implies \(Prov([Prov([p])])\)
One way is to prove this is to use Löb's theorem.
4. \(Prov([\top])\)
The trivially true statement had better be provable or \(Prov\) is broken.
Constructing \(Prov\) is conceptually straightforward but hard work.
I'm definitely not going to do it here.
And there's one last thing we need: self-reference.
If \(p\) is a proposition, how can we possibly assert \(Prov([p])\) without squeezing a copy of \([p]\) inside \(p\)?
I'm not going to do that here either - just mention that we can use a variation of quining to achieve this.
That allows us to form a proposition \(p\) for which we can prove \(p\leftrightarrow Prov([p])\).
In fact, we can go further.
We can find propositions that solve \(p\leftrightarrow F(p)\) for any predicate \(F(p)\) built from the usual boolean operations and \(p\) as long as all of the occurrences of \(p\) are inside the appearances of \(Prov\).
Even though we can't form a proposition that directly asserts its own falsity, we can form one that asserts that it is unprovable, or one that asserts that you can't prove that you can't prove that you can prove it, or anything along those lines.
Anyway, all that \([]\) and \(Prov\) business is a lot of hassle.
Provability logic, also known as GL, is intended to capture specifically the parts of PA that relate to provability.
GL is propositional calculus extended with the provability operator \(\Box\).
The intention is that if \(p\) is a proposition, \(\Box p\) is a proposition in GL that represents \(Prov([p])\) in PA.
The properties of \(Prov\) above become the axioms and derivation rules of GL in the main text.
Google have stopped supporting the Chart API so all of the mathematics notation below is missing. There is a PDF version of this article at GitHub.
There are many introductions to the Expectation-Maximisation algorithm.
Unfortunately every one I could find uses arbitrary seeming tricks that seem to be plucked out of a hat by magic.
They can all be justified in retrospect, but I find it more useful to learn from reusable techniques that you can apply to further problems.
Examples of tricks I've seen used are:
Using Jensen's inequality. It's easy to find inequalities that apply in any situation. But there are often many ways to apply them. Why apply it to this way of writing this expression and not that one which is equal?
Substituting \(1=A/A\) in the middle of an expression. Again, you can use \(1=A/A\) just about anywhere. Why choose this \(A\) at this time? Similarly I found derivations that insert a \(B-B\) into an expression.
Majorisation-Minimisation. This is a great technique, but involves choosing a function that majorises another. There are so many ways to do this, it's hard to imagine any general purpose method that tells you how to narrow down the choice.
My goal is to fill in the details of one key step in the derivation of the EM algorithm in a way that makes it inevitable rather than arbitrary.
There's nothing original here, I'm merely expanding on a stackexchange answer.
Generalities about EM
The EM algorithm seeks to construct a maximum likelihood estimator (MLE) with a twist: there are some variables in the system that we can't observe.
First assume no hidden variables.
We assume there is a vector of parameters \(\theta=(\theta_i)\) that defines some model.
We make some observations \(x=(x_j)\).
We have a probability density \(P(x|\theta)\) that depends on \(\theta\).
The likelihood of \(\theta\) given the observations \(x\) is \(l(\theta|x)=P(x|\theta)\).
The maximum likelhood estimator for \(\theta\) is the choice of \(\theta\) that maximises \(l(\theta|x)\) for the \(x\) we have observed.
Now suppose there are also some variables \(z=(z_k)\) that we didn't get to observe.
We assume a density \(P(x,z|\theta)\).
We now have
\(P(x|\theta)=\sum_z P(x,z|\theta)\)
where we sum over all possible values of \(z\).
The MLE approach says we now need to maximise
\(l(\theta|x)=\sum_z P(x,z|\theta).\)
One of the things that is a challenge here is that the components of \(\theta\) might be mixed up among the terms in the sum.
If, instead, each term only referred to its own unique block of \(\theta_i\), then the maximisation would be easier as we could maximise each term independently of the others.
Here's how we might move in that direction.
Consider instead the log-likelihood
\(\log l(\theta|x)=\log\sum_z P(x,z|\theta).\)
Now imagine that by magic we could commute the logarithm with the sum.
We'd need to maximise
\(\sum_z \log P(x,z|\theta).\)
One reason this would be to our advantage is that \(P(x,z|\theta)\) often takes the form \(\exp(f(x,z,\theta))\) where \(f\) is a simple function to optimise.
In addition, \(f\) may break up as a sum of terms, each with its own block of \(\theta_i\)'s.
Moving the logarithm inside the sum would give us something we could easily maximise term by term.
What's more, the \(P(x,z|\theta)\) for each \(z\) is often a standard probability distribution whose likelihood we already know how to maximise.
But, of course, we can't just move that logarithm in.
Maximisation by proxy
Sometimes a function is too hard to optimise directly.
But if we have a guess for an optimum, we can replace our function with a proxy function that approximates it in the neighbourhood of our guess and optimise that instead.
That will give us a new guess and we can continue from there.
This is the basis of gradient descent.
Suppose \(f\) is a differentiable function in a neighbourhood of \(x_0\).
Then around \(x_0\) we have
\(f(x) \approx f(x_0) f'(x_0)\cdot (x-x_0).\)
We can try optimising \(f(x_0) f'(x_0)\cdot (x-x_0)\) with respect to \(x\) within a neighbourhood of \(x_0\).
If we pick a small circular neighbourhood then the optimal value will be in the direction of steepest descent.
(Note that picking a circular neighbourhood is itself a somewhat arbitrary step,
but that's another story.)
For gradient descent we're choosing \(f(x_0) f'(x_0)\cdot (x-x_0)\) because it matches both the value and derivatives of \(f\) at \(x_0\).
We could go further and optimise a proxy that shares second derivatives too, and that leads to methods based on Newton-Raphson iteration.
We want our logarithm of a sum to be a sum of logarithms.
But instead we'll settle for a proxy function that is a sum of logarithms.
We'll make the derivatives of the proxy match those of the original function
precisely so we're not making an arbitrary choice.
So the procedure is to take an estimated \(\theta_0\) and obtain a new estimate
by optimising this proxy function with respect to \(\theta\).
This is the standard EM algorithm.
It turns out that this proxy has some other useful properties.
For example, because of the concavity of the logarithm,
the proxy is always smaller than the original likelihood.
This means that when we optimise it we never optimise ``too far''
and that progress optimising the proxy is always progress optimising the
original likelihood.
But I don't need to say anything about this as it's all part of the standard literature.
Afterword
As a side effect we have a general purpose optimisation algorithm that has nothing to do with statistics. If your goal is to compute
A popular question in mathematics is this: given a function \(f\), what is its "square root" \(g\) in the sense that \(g(g(x)) = f(x)\).
There are many questions about this on mathoverflow but it's also a popular subject in mathematics forums for non-experts.
This question seems to have a certain amount of notoriety because it's easy to ask but hard to answer fully.
I want to look at an approach that works nicely for formal power series, following from the Haskell code I wrote here.
There are some methods for directly finding "functional square roots" for formal power series that start as \(z a_2z^2 a_3z^3 \ldots\), but I want to approach the problem indirectly.
When working with real numbers we can find square roots, say, by using \(\sqrt{x}=\exp(\frac{1}{2}\log{x})\).
I want to use an analogue of this for functions.
So my goal is to make sense of the idea of the logarithm and exponential of a formal power series as composable functions.
Warning: the arguments are all going to be informal.
Notation
There's potential for a lot of ambiguous notation here, especially as the usual mathematical notation for \(n\)th powers of trig functions is so misleading.
I'm going to use \(\circ\) for composition of functions and power series, and I'm going to use the notation \(f^{\circ n}\) to mean the \(n\)th iterate of \(f\).
So \(f^{n 1}(x) = f(x)f^n(x)\) and \(f^{\circ n 1}(x) = f(f^{\circ n}(x))\).
As I'll be working mostly in the ring of formal power series \(R[\![z]\!]\) for some ring \(R\), I'll reserve the variable \(z\) to refer only to the corresponding element in this ring.
I'll also use formal power series somewhat interchangeably with functions. So \(z\) can be thought of as representing the identity function.
To make sure we're on the same page, here are some small theorems in this notation:
\(z^mz^n = z^{m n}\)
\(f^{\circ m}\circ f^{\circ n} = f^{\circ m n}\)
\((1 z)^n = \sum_{i=0}^n{n\choose i}z^n\)
\((1 z)^{\circ n}=n z\).
That last one simply says that adding one \(n\) times is the same as adding \(n\).
As I'm going to have ordinary logarithms and exponentials sitting around, as well as functional logarithms and exponentials, I'm going to introduce the notation \(\operatorname{LOG}\) for functional logarithm and \(\operatorname{EXP}\) for functional exponentiation.
Preliminaries
The first goal is to define a non-trivial function \(\operatorname{LOG}\) with the fundamental property that \(\operatorname{LOG}(f^{\circ n})=n\operatorname{LOG}(f)\)
First, let's note some basic algebraic facts.
The formal power series form a commutative ring with operations and \(\cdot\) (ordinary multiplication) and with additive identity \(0\) and multiplicative identity \(1\).
The formal power series form a ring-like algebraic structure with operation and partial operation \(\circ\) with additive identity \(0\) and multiplicative identity \(z\).
But it's not actually ring or even a near-ring.
Composition isn't defined for all formal power series and even when it's defined, we don't have distributivity.
For example, in general \(f\circ(g h)\ne f\circ g f\circ h\), after all there's no reason to expect \(f(g(x) h(x))\) to equal \(f(g(x)) f(h(x))\).
We do have right-distributivity however, i.e.
\((f g)\circ h = f\circ g f\circ h\),
because
\((f g)(h(x))=f(h(x)) g(h(x))\),
more or less by definition of .
We can't use power series on our power series
There's an obvious approach, just use power series of power series.
So we might tentatively suggest that
Note that I consider \(\operatorname{LOG}(z f)\) rather than \(\operatorname{LOG}(1 f)\) because \(z\) is the multiplicative identity in our ring-like structure.
Unfortunately this doesn't work.
The reason is this: if we try to use standard reasoning to show that the resulting function has the fundamental property we seek we end up using distributivity.
We don't have distributivity.
Sleight of hand
There's a beautiful trick I spotted on mathoverflow recently that allows us to bring back distributivity.
(I can't find the trick again, but when I do I'll come back and add a link and credit here.)
Consider the function \(R(g)\) defined by \(R(g)(f) = f\circ g\).
In other words \(R(g)\) is right-composition by \(g\).
(Ambiguity alert, I'm using \(R\) here to mean right.
It has nothing to do with the ring underlying our formal power series.)
Because we have right-distributivity, \(R(g)\) is a bona fide linear operator on the space of formal power series.
If you think of formal power series as being infinitely long vectors of coefficients then \(R(g)\) can be thought of as an infinitely sized matrix.
This means that as long as we have convergence, we can get away with using power series to compute \(\log R(g)\) with the property that \(\log(R(g)^n) = n\log R(g)\).
Define:
But does it converge?
Suppose \(f\) is of the form \(x a_2x^2 a_3x^3 \ldots\).
Then \((R(f)-1)g = g\circ f-g\).
The leading term in \(g\circ f\) is the same as the leading term in \(g\).
So \(R(f)-1\) kills the first term of whatever it is applied to, which means that when we sum the terms in \(\operatorname{LOG}(f)\), we only need \(n\) to get a power series correct to \(n\) coefficients.
Reusing my code from here, I call \(\operatorname{LOG}\) by the name flog.
Here is its implementation:
> import Data.Ratio
> flog :: (Eq a, Fractional a) => [a] -> [a]
> flog f@(0 : 1 : _) =
> flog' 1 (repeat 0) (0 : 1 : repeat 0)
> where flog' n total term = take (n+1) total ++ (
> drop (n+1) $
> let pz = p term
> in flog' (n+1) (total-map (((-1)^n / fromIntegral n) *) pz) pz)
> p total = (total ○ f) - total
The take and drop are how I tell Haskell when the first \(n 1\) coefficients have been exactly computed and so no more terms are necessary.
Does it work?
Here's an example using the twice iterated sin function:
> ex1 = do
> let lhs = flog (sin (sin z))
> let rhs = 2*flog (sin z)
> mapM_ print $ take 20 (lhs-rhs)
Works to 20 coefficients. Dare we try an inverse function?
> ex2 = do
> let lhs = flog (sin z)
> let rhs = flog (asin z)
> mapM_ print $ take 20 (lhs+rhs)
Seems to work!
Exponentials
It's no good having logarithms if we can't invert them.
One way to think about the exponential function is that
We get better and better approximations by writing the expression inside the limit as a product of more and more terms.
We can derive the usual power series for \(\exp\) from this, but only if right-distributivity holds.
So let's try to use the above expression directly:
This is something we can implement using the power series for ordinary \(\exp\):
\(\operatorname{EXP}(f) = z f \frac{1}{2!}f\frac{df}{dz} \frac{1}{3!}f\frac{d}{dz}(f\frac{df}{dz}) \ldots\).
In code that becomes:
> fexp f@(0 : 0 : _) = fexp' f 0 z 1
> fexp' f total term n = take (n-1) total ++ drop (n-1)
> (fexp' f (total+term) (map (/fromIntegral n) (f*d term)) (n+1))
Note how when we differentiate a power series we shift the coefficients down by one place.
To counter the effect of that so as to ensure convergence we need \(f\) to look like \(a_2z^2 a_3a^3 \ldots\).
Luckily this is exactly the kind of series \(\operatorname{LOG}\) gives us.
But does it successfully invert \(\operatorname{LOG}\)?
Let's try:
> ex3 = do
> let lhs = sin z
> let rhs = fexp (flog (sin z))
> mapM_ print $ take 20 (lhs-rhs)
Now we can start computing fractional iterates.
Square root first:
> ex4 = do
> mapM_ print $ take 20 $ fexp (flog (sin z)/2)
And this gives an alternative to Lagrange inversion for computing power series for inverse functions:
> ex6 = do
> let lhs = fexp (-flog (sin z))
> let rhs = asin z
> mapM_ print $ take 20 (lhs-rhs)
What's really going on with \(\operatorname{EXP}\)?
Let's approach \(\operatorname{EXP}\) in a slightly different way.
In effect, \(\operatorname{EXP}\) is the composition of \(n\) lots of \(z \frac{f}{n}\) with \(z\).
So let's try composing these one at a time, with one composition every \(\frac{1}{n}\) seconds.
After one second we should have our final result.
We can write this as:
\(g(0) = z\) and \(g(t \frac{1}{n}) = g(t) \frac{1}{n}f(g(t))\) to first order.
So we're solving the differential equation:
\(g(0) = z\) and \(\frac{dg}{dt} = f(g(t))\)
with \(\operatorname{EXP}(g) = g(1)\).
So \(\operatorname{EXP}\) is the function that solves one of the most fundamental differential equations.
This also means I can use Mathematica to solve symbolically and check my results.
For example, Mathematica says that the solution to
\(\frac{dg}{dt}=sin(g(t))^2\) and \(g(0)=x\)
at \(t=1\) is
\(g(1) = \frac{\tan z}{1-\tan z}\)
so let's check:
> ex7 = do
> let lhs = fexp ((sin z)^2)
> let rhs = atan (tan z/(1-tan z))
> mapM_ print $ take 20 (lhs-rhs)
I like this example because it leads to the generalized Catalan numbers A004148:
> ex8 = do
> mapM_ print $ take 20 $ fexp (z^2/(1-z^2))
That suggests this question: what does \(\operatorname{EXP}\) mean combinatorially?
I don't have a straightforward answer but solving this class of differential equation motivated the original introduction, by Cayley, of the abstract notion of a tree.
See here.
What is going on geometrically?
For those who know some differential geometry,
The differential equation
\(g(0) = z\) and \(\frac{dg}{dt} = f(g(t))\)
describes a flow on the real line (or complex plane).
You can think of \(f\) as being a one-dimensional vector field describing how points move from time \(t\) to \(t dt\).
When we solve the differential equation we get integral curves that these points follow and \(\operatorname{EXP}\) tells us where the points end up after one unit of time.
So \(\operatorname{EXP}\) is the exponential map.
In fact, \(\operatorname{EXP}(f)=\exp(f\frac{d}{dz})z\) is essentially the exponential of the vector field \(f\frac{d}{dz}\) where we're now using the differential geometer's notion of a vector field as a differential operator.
Final word
Unfortunately the power series you get from using \(\operator{LOG}\) and \(\operator{EXP}\) don't always have good convergence properties.
For example, I'm not sure but I think the series for \(\sin^{\circ 1/2} z\) has radius of convergence zero.
If you truncate the series you get a half-decent approximaion to a square root in the vicinity of the origin, but the approximation gets worse, not better, if you use more terms.
And the rest of the code
> (*!) _ 0 = 0
> (*!) a b = a*b
> (!*) 0 _ = 0
> (!*) a b = a*b
> (^+) a b = zipWith (+) a b
> (^-) a b = zipWith (-) a b
> ~(a:as) ⊗ (b:bs) = (a *! b):
> ((map (a !*) bs) ^+ (as ⊗ (b:bs)))
> (○) (f:fs) (0:gs) = f:(gs ⊗ (fs ○ (0:gs)))
> inverse (0:f:fs) = x where x = map (recip f *) (0:1:g)
> _:_:g = map negate ((0:0:fs) ○ x)
> invert x = r where r = map (/x0) ((1:repeat 0) ^- (r ⊗ (0:xs)))
> x0:xs = x
> (^/) (0:a) (0:b) = a ^/ b
> (^/) a b = a ⊗ (invert b)
> z :: [Rational]
> z = 0:1:repeat 0
> d (_:x) = zipWith (*) (map fromInteger [1..]) x
> integrate x = 0 : zipWith (/) x (map fromInteger [1..])
> instance (Eq r, Num r) => Num [r] where
> x+y = zipWith (+) x y
> x-y = zipWith (-) x y
> ~x*y = x ⊗ y
> fromInteger x = fromInteger x:repeat 0
> negate x = map negate x
> signum (x:_) = signum x : repeat 0
> abs (x:xs) = error "Can't form abs of a power series"
> instance (Eq r, Fractional r) => Fractional [r] where
> x/y = x ^/ y
> fromRational x = fromRational x:repeat 0
> sqrt' x = 1 : rs where rs = map (/2) (xs ^- (rs ⊗ (0:rs)))
> _ : xs = x
> instance (Eq r, Fractional r) => Floating [r] where
> sqrt (1 : x) = sqrt' (1 : x)
> sqrt _ = error "Can only find sqrt when leading term is 1"
> exp x = e where e = 1+integrate (e * d x)
> log x = integrate (d x/x)
> sin x = integrate ((cos x)*(d x))
> cos x = [1] ... negate (integrate ((sin x)*(d x)))
> asin x = integrate (d x/sqrt(1-x*x))
> atan x = integrate (d x/(1+x*x))
> acos x = error "Unable to form power series for acos"
> sinh x = integrate ((cosh x)*(d x))
> cosh x = [1] ... integrate ((sinh x)*(d x))
> asinh x = integrate (d x/sqrt(1+x*x))
> atanh x = integrate (d x/(1-x*x))
> acosh x = error "Unable to form power series for acosh"
> pi = error "There is no formal power series for pi"
> lead [] x = x
> lead (a:as) x = a : (lead as (tail x))
> a ... x = lead a x
> (//) :: Fractional a => [a] -> (Integer -> Bool) -> [a]
> (//) a c = zipWith (\a-> \b->(if (c a :: Bool) then b else 0)) [(0::Integer)..] a
A direct functional square root that doesn't use \(\operatorname{LOG}\) and \(\operatorname{EXP}\):
> fsqrt (0 : 1 : fs) =
> let gs = (fs-(0 : gs*((0 : delta gs gs)+((2 : gs)*(gs*g)))))/2
> g = 0 : 1 : gs
> delta (g : gs) h = let g' = delta gs h
> in (0 : ((1 : h) * g')) + gs
> in g
You’ve got some nice code. That’s a nice trie.
I see those PRs. But no README?
Everybody knows documentation is essential to any software engineering
enterprise. And fo’ shizzle, everybody knows it gets deprioritised. An
afterthought; written by engineers who are thinking, “I should probably
write docs”. Nah. What they should be thinking is, “I get to write
docs, cuz!” Because when you doc it right, it ain’t a chore. It’s what
separates a project people use from a project people lose.
In this post, I’m walkin’ you through three real projects I’ve been
involved in at Tweag; each one levelling up the documentation game.
First, fixing docs that got out of hand: the reactive play. Then,
planning docs from day one: the proactive play. And finally,
making docs part of the code itself: the integrated play. By the end, I
think you’ll agree: to doc it like it’s hot is the only way to gizzo.
When your README’s a monolith
Doc it like it’s hot
Sometimes the docs are already a mess and you gotta clean house. That’s
the reactive play.
That was the case with Topiary, Tweag’s universal formatting engine.
It uses Tree-sitter grammars and queries to format code; encoded in what
Tree-sitter calls “capture names”. All of our formatting capture names
needed to be documented, with their semantics described.
Moreover, our documentation covered usage instructions, which were
checked against the --help output of each subcommand. Then there was
our project motivation and design philosophy, language support,
installation instructions, configuration details, usage guides…
…All in a single README.md which had grown to over 7,000 words. Way
too big for the crib, homes. Ain’t nobody reading all that!
Drift and inconsistency were creeping in, making it harder for the team
to maintain. Worse, it was straight-up hostile to users: how you gonna
expect someone to sift through all that noise just to find what they
need?
Topiary OG Erin started work reconstructing the monolith into a book
format using — as it’s a Rust project — mdBook. I picked up where he
left off and finished it for Topiary v0.6.1. Yo, the Topiary Book was
born!
But the move here wasn’t just splitting up the README.md and calling
it a day. You need a crew and every member needs a role. That means a
framework; something to keep it tight, maintainable and user-friendly.
We rolled with Diátaxis, which identifies four distinct documentation
types based on what the reader actually needs:
Tutorials, for learners. For example, Yann’s step-by-step
guides walk readers through creating a
formatter from scratch for a toy language, starting from zero. Its aim
is to actively reach understanding through engagement, rather than
just passive reading.
How-to guides, for readers who want to accomplish a specific goal.
“Adding a new language” assumes you already know
Topiary and gets straight to the point: register the grammar, create a
query file, update the test suite, rinse and repeat.
Explanation, for those who need a deeper understanding. For
example, “Tree-sitter and its queries” explains
the conceptual foundation — what Tree-sitter is, why Topiary uses it
and how queries relate to formatting — without asking the reader to
do anything.
Reference, which describes what exists and how it behaves. Our
capture names chapter documents every formatting
directive Topiary recognises, what it does, its syntax and its edge
cases. You’re not meant to read it cover-to-cover; it’s just there to
look up whenever you need it.
Structure is a prerequisite for usefulness and frameworks exist so you
don’t have to invent your own. Rolling your own ain’t gangsta, use
what’s already out there…that’s real game.
When you have varied audiences
Doc it like it’s hot
Cleaning up after the fact is one thing, but why not come correct from
the start? That’s the proactive play: before you write a line of
documentation, you ask who’s gonna read it and what they need. Then you
build the structure around that.
So, while Topiary is a developer productivity tool with, broadly, a
developer audience, the second project I want to chop it up about is
different: an omics data acquisition tool for a pharmaceutical
client’s computational biology needs.
This one had a whole different crowd to please. Bioinformaticians
running data processing pipelines, IT staff handling installation and
access control, administrators guiding users through workflows and
developers who might extend the project down the line…including,
potentially, yours truly, after returning from a long absence and having
forgotten how everything works!
Their needs, vocabulary and assumptions barely overlap, so a single set
of docs couldn’t serve them all without becoming an unfocused sprawl.
So I split the documentation three ways:
A technical manual, covering every subcommand, flag and
configuration key. The kind of thing a user reaches for mid-pipeline,
an administrator references when guiding colleagues, or IT consults
when setting up the environment.
A developer manual, as its mirror image: module architecture, type
hierarchies, testing methodology and contribution workflow. All you
need to dig the codebase, but were too shook to ask!
A user manual sat between the two, covering key concepts, how-to
guides and troubleshooting. Diátaxis was again the guiding framework
here: the concepts section is explanation, the how-to guides are
exactly that and the troubleshooting page addresses the practical edge
cases that tripped people up during user acceptance testing.
Within the user manual, I also got to indulge in what you’ve probably
gathered is my favourite move. I weaved in a narrative through the
examples that borrowed — with some artistic licence — from Stevenson’s
Strange Case of Dr. Jekyll and Mr. Hyde: An external
collaborator’s data arrives from Dr. Jekyll’s lab, making oblique
references to the novella throughout, and ultimately identifying the
evil-transcriptome for downstream analysis.
Does this make the documentation sillier than it needs to be? Maybe. But
it makes the examples stick…and that ain’t just a vibe, it’s science,
dawg: our brains are straight-up wired to retain information delivered
through narrative far better than through
isolated facts. A reader who skimmed the manual a month ago can still
go, “that’s the example where forward and reverse reads are named ‘front
door’ and ‘back door’” and find the section again. The story gives
continuity across otherwise disconnected examples; where each section
could stand alone, the recurring characters give readers a reason to
follow the arc from data acquisition to analysis. And the scenario is
deliberately awkward, which exercises more features than a vanilla
example ever could.
Different people need different things, that’s just how it is. A
bioinformatician never needs to know how the S3 client interface is
structured, just as a future developer doesn’t need a walkthrough of
dataset creation from NCBI metadata. When your audiences are distinct
enough, the realest thing you can do is acknowledge that up front,
rather than forcing everyone to wade through what ain’t for them…and
there’s never any harm in bringing a little levity into the world!
When you need to have clarity
Doc it like it’s hot
Planning ahead is smooth, but the smoothest move of all? Making the docs
and the code one and the same. That’s the integrated play.
The previous case study included a developer manual, but my final
example? That’s all developer; front to back. Scrawls is a Rust
library implementing a verifiable file format for Cardano ledger
state, as an independent implementation alongside a Haskell
reference. Its users are Rust developers pulling in the
crate as a dependency, so the documentation strategy needed to reflect
that.
In Rust, the idiomatic answer to this is rustdoc: in-band
documentation that lives alongside the types, functions and invariants
it describes. Then, while there is still a README.md, it functions
more as a landing page than a manual: a brief orientation, a feature
summary and a handful of examples to get a new user from zero to
something.
Docstrings ain’t new, of course — Doxygen has been around since the
’90s — but Rust’s ecosystem raises the bar. Between docs.rs
publishing your crate’s documentation automatically and a community that
straight-up expects thorough doc comments, skipping them feels less like
a shortcut and more like showing up empty-handed. So, when the API
changes, the respective documentation change should be right there in
the diff, for reviewers to keep it real.
And here’s the thing: during implementation, the specification was still
maturing and encoding its requirements into Rust exposed ambiguities
that were lurking in the prose. Should certain orderings be strict? How
should the Merkle tree be rolled up? Is this field optional, or merely
absent? Each ambiguity became a clarification fed back into the spec.
And each clarification, a documented precondition in the API.
A specification is, at the end of the day, documentation too…and the
same principle applies: vagueness is a bug. This ain’t documentation as
prose; it’s documentation as a contract, forged on the streets between
spec and implementation. Sometimes the most valuable work you can do is
keep it tight, not make it long.
Document your code, ma
That’s how you get ahizzead
Reactive. Proactive. Integrated. Three different plays for three
different games…though ideally you won’t need the first! And what ties
them all together is that none of the documentation I’ve described was
written reluctantly. It wasn’t tacked on after the fact because someone
asked, “Where are the docs?” It was thought about — its structure, its
audience, its precision — as part of the work itself.
That’s the shift I want to put you on to. Documentation ain’t a tax you
pay for writing code; it is part of writing code. And when you
approach it that way — when you reach for a framework instead of a
blank page; when you ask “who’s this for?” before you start typing; when
you treat ambiguity as a bug — then you’re doc’ing it like it’s hot!
The result is something you’re genuinely proud of, not something you
hope nobody reads too carefully.
Now if documentation alongside code is good, then documentation before
code — as a design tool; a sketch in prose before you commit to
implementation — is the next level. While I ain’t taken that step
myself, my Scrawls experience, where the spec and the code kept each
other honest, showed me how close that workflow already is.
In practice, pure docs-first has the same problem as pure test-driven
development: you can’t document what you don’t know yet. But that
feedback loop — where the docs sharpen the code and the code sharpens
the docs — that’s the real endgame right there. You might notice this
sounds a bit like vibe-coding, and it is…in the same way that an
architect’s blueprint is a bit like a napkin sketch. Same ‘hood,
different zip codes, dawg. Something to aspire to, fo’ shizzle.
So now, just like my man S-to the N-to the double O-P, you too can
say…
I got a Rollie on my arm and I’m pourin’ Chandon
And I write the best docs, ‘cause I got it goin’ on.
With thanks to Simeon Carstens, Facundo Domínguez, Valentin Gagarin,
Xavier Góngora, Arnaud Spiwack, Snoop Dogg and Pharrell Williams for
their reviews and input on this post.
This is the first part of a miniseries on this year’s Symposium on Principles of Programming Languages, a.k.a. POPL 2026, hosted by Jessica Foster.
In this episode, we talk about: undergrad funding and participation, the behind the scenes of AV, choreographic programming, quantum languages, conference catering, and the joy of theory. And at one point, you’ll even hear us get kicked out the venue mid interview. Enjoy!
Last year Ethan Heilman wrote about a simple game he calls Terminal Maneuvers.
This game simulates a missile attacking an interstellar ship.
The ship has a laser defence system.
One player controls the missile, and the other player controls the laser.
If the missile hits the ship, Missile wins.
If the laser hits the missile, the missile is destroyed and Laser wins.
The complicating factor is that, due to the relative motion of the laser and the ship being a significant fraction of the speed of light, Laser has to aim not at the missile but where the missile will be.
This distance allows the missile to perform erratic manoeuvers to prevent Laser from knowing what its future position will be.
However, Missile must expend fuel to perform these manoeuvers.
The Terminal Maneuvers game proceeds in five rounds, giving the laser five opportunities to hit the missile.
In each round, Missile secretly commits to an amount of fuel they will expend.
Laser must “aim” by guessing the amount of fuel expended by Missile.
If they guess correctly, there is some probability of destroying the missile, which depends on how far away the missile is and how much fuel the missile expended.
The table below shows the probabilities of the missile being destroyed in the various rounds.
Probability of Laser destroying the missile when correctly guessing Missile’s fuel expenditure
Fuel Cost
Round 1
Round 2
Round 3
Round 4
Round 5
0 Fuel
100%
100%
100%
100%
100%
1 Fuel
1/6
2/6
3/6
4/6
5/6
2 Fuel
0%
1/6
2/6
3/6
4/6
3 Fuel
0%
1/6
2/6
3/6
4 Fuel
0%
1/6
2/6
5 Fuel
0%
1/6
6 Fuel
0%
The missile has a limited amount of fuel at the start of the game.
Fuel spent earlier in the game means less fuel available later in the game when it is most needed.
The amount of starting fuel selects the difficulty of the game.
Ethan suggests starting with seven fuel, which empirically gives Missile about a 25% chance of winning.
Laser knows how much fuel the missile has at the start of each round, so it is imperative that Missile does not run out of fuel in the middle of the game.
If Laser knows the missile is out of fuel, Laser will predict zero fuel used and will always successfully destroy the missile.
That said, as long as Missile has some fuel, choosing to burn zero fuel is still a legitimate option.
Starting with seven fuel, one strategy for Missile would be to burn one fuel on the first four rounds and burn the remaining three fuel on the last round.
However, if Laser realizes this is Missile’s strategy, Laser can always predict the correct amount of fuel that will be used by the missile.
Taking the product of all the probabilities of Missile’s survival in each round, Missile only has a 4.6% chance of winning.
Clearly, Missile’s optimal strategy should be non-deterministic.
I figured this game would be a fun exercise in learning about mixed-strategy (i.e., non-deterministic) Nash equilibrium.
This game is a small finite game, so it is reasonably easy to analyze, but it is significantly more complicated than trivial games often used in Nash equilibrium examples.
For these calculations, it is best to find the Nash equilibrium strategy at the endgame and work backward from there.
To that end, let us start with the simplest non-trivial endgame.
Missile has survived to Round 5 and has 1 fuel left.
Missile can choose to burn their last fuel or not, and Laser can choose to aim at no fuel burned or not.
This yields the following, game-theoretic payoff matrix, listing the probabilities of missile or laser winning:
Payoff matrix for Round 5 with 1 fuel remaining
Predict 0
Predict 1
Burn 0
0, 1
1, 0
Burn 1
1, 0
1⁄6, 5⁄6
This is a constant-sum game, because the total score of all players is always the same, no matter the outcome.
Constant-sum games are also known as zero-sum games since they can be translated into games where the sum of each outcome is zero without affecting any strategy.
The definition of Nash equilibrium is a pair of strategies, one for each player, where neither player individually can change strategies to improve their outcome.
Therefore, one potential way for Missile to devise a strategy is to find one where Laser’s chance of winning is the same regardless of the move that they make.
Such a strategy is not necessarily going to be possible, but we can give it a try.
Let p be the probability that Missile will burn 0, and let q be the probability that Missile will burn 1.
If Laser predicts 0, the probability of them winning is p.
If Laser predicts 1, the probability of them winning is 5⁄6 q.
If Laser cannot make a choice between these two options to improve their odds, then p = 5⁄6 q.
Missile’s probabilities must add up to 1, so we also require p + q = 1.
We have a linear system of two equations and two unknowns, so we can try to solve it.
The solution is p = 5⁄11 and q = 6⁄11.
Missile burns no fuel with probability 5⁄11 and burns its one fuel with probability 6⁄11.
This provides Missile a 6⁄11 chance of winning, regardless of which prediction Laser makes.
On the flip side, Laser’s Nash equilibrium can be computed by choosing a set of probabilities so that Missile’s outcome is the same regardless of whether they choose to burn fuel or not.
This time, let p be the probability that Laser will predict 0, and let q be the probability that Laser will predict 1.
If Missile burns 0, the probability of them winning is q.
If Missile burns 1, the probability of them winning is p + 1⁄6 q.
Again, if Missile cannot make a choice between these two options to improve their odds, then q = p + 1⁄6 q.
Laser’s probabilities also must add up to 1, so we also require p + q = 1.
Rearranging q = p + 1⁄6 q, we get 5⁄6 q = p, which happens to be the exact same equation Missile had.
Thus, their solutions are identical.
Laser predicts no fuel burned with a probability of 5⁄11 and predicts one fuel burned with a probability of 6⁄11.
This provides Laser a 5⁄11 chance of winning no matter whether Missile has chosen to burn their fuel or not.
This chance is the complement to Missile’s 6⁄11 chance of winning, as it has to be.
Payoff matrix for Round 5 with 2 fuel remaining
Predict 0
Predict 1
Predict 2
Burn 0
0, 1
1, 0
1, 0
Burn 1
1, 0
1⁄6, 5⁄6
1, 0
Burn 2
1, 0
1, 0
2⁄6, 4⁄6
If the game ends in Round 5 with Missile having 2 fuel left, we have the above payoff matrix.
We can solve similar linear algebra problems on three variables to find strategies for each player so that the other player’s outcome is the same no matter which of their three choices they make.
The solution has Missile burn 0 fuel with probability 10⁄37, burn 1 fuel with probability 12⁄37, and burn 2 fuel with probability 15⁄37, giving Missile a 27⁄37 chance of winning regardless of what Laser’s prediction is.
Laser makes the predictions with the same probability distribution, giving Laser a 10⁄37 chance of winning no matter how much fuel Missile chooses to burn.
This sort of distribution is what we might expect: somewhat evenly distributed with a bias towards burning more fuel, which provides some evasion for Missile.
What I found surprising is how when Laser plays at their Nash equilibrium, they simply do not care how much fuel Missile has secretly chosen to burn.
Their odds of winning are the same regardless of what Missile reveals.
It is as if Laser is no longer playing against Missile at all.
Missile’s choices no longer matter.
This result is called the “indifference principle.”
Later we will see that Missile’s choices sometimes can matter.
Missile feels the same when playing at their equilibrium.
No matter what prediction Laser ultimately makes, Missile’s odds of winning have already been fixed by playing at the Nash equilibrium.
In theory, this is what playing poker at a Nash equilibrium should feel like.
Based on the state of the board, you make a random selection of calls, folds, or raises according to some appropriate distribution, and your distribution has fixed your expected payout at that point, independent of the choices the other players are going to make.
No need to stress over whether your bluff will be called or not.
Before moving on to analyzing Round 4, we can complete a chart of the probability of Missile winning when playing at their Nash equilibrium depending on how much fuel they have remaining.
Probability table for Round 5
Remaining Fuel
Missile Win Probability
Laser Win Probability
0
0%
100%
1
6⁄11 ≈ 54.5%
5⁄11 ≈ 45.5%
2
27⁄37 ≈ 73.0%
10⁄37 ≈ 27.0%
3
47⁄57 ≈ 82.5%
10⁄57 ≈ 17.5%
4
77⁄87 ≈ 88.5%
10⁄87 ≈ 11.5%
5
137⁄147 ≈ 93.2%
10⁄147 ≈ 6.8%
6+
100%
0%
If Missile starts Round 4 with 1 fuel remaining, they are in big trouble.
They can only burn fuel in at most one of the two remaining rounds.
Therefore, Laser can win by predicting 0 fuel burned in both Round 4 and Round 5.
Laser is guaranteed to destroy the missile on one of those two rounds.
Missile must start Round 4 with at least 2 fuel remaining if they are to have a chance of winning.
Since the game in each round depends only on the state of Missile’s remaining fuel and not on the specific choices of how that state came to be, we can simplify the analysis of Round 4’s payoff matrix by using each player’s probability of winning Round 5 as their scores in Round 4.
Note that Missile does not have the option of burning all their fuel in Round 4, since starting Round 5 with 0 fuel is a guaranteed loss for them, and Laser knows it.
Payoff matrix for Round 4 with 2 fuel remaining
Predict 0
Predict 1
Burn 0
0, 1
27⁄37, 10⁄37
Burn 1
6⁄11, 5⁄11
2⁄11, 9⁄11
To compute Missile’s strategy, we define p and q as before.
This time Missile needs to solve the equations
p + 5⁄11 q = 10⁄37 p + 9⁄11 q and p + q = 1.
The solution has Missile burn 0 fuel with a probability of 148⁄445 and burn 1 fuel with a probability of 297⁄445, which is roughly a 1⁄3rd–2⁄3rd split.
This provides Missile a chance of winning with a probability of 162⁄445, or about 36.4%.
Meanwhile, Laser needs to solve the equations 27⁄37 q = 6⁄11 p + 2⁄11 q and p + q = 1.
The solution has Laser predict 0 fuel with probability 223⁄445 and predict 1 fuel with probability 222⁄445, which is nearly evenly split.
This provides Laser a chance of winning of 283⁄445, or about 63.6%.
In Round 5, each player’s individual payoff matrix was symmetric, which led to Missile and Laser having identical strategies.
In Round 4, the individual player’s payoff matrices are no longer symmetric, and Missile and Laser end up with different strategies.
Laser picks a nearly 50–50 split because the differences of column scores, 5⁄11 − 1 vs. 9⁄11 − 10⁄37, are nearly equal in magnitude.
Whereas Missile picks a 1⁄3rd–2⁄3rd split because the difference of row scores, 27⁄37 vs. 2⁄11 − 6⁄11, differs in magnitude by close to a factor of two.
We can proceed as before, using linear algebra to compute equilibrium strategies for Round 4 with various states of remaining fuel for the missile.
However, we run into a problem when Missile has 4 fuel remaining.
Payoff matrix for Round 4 with 4 fuel remaining.
Predict 0
Predict 1
Predict 2
Predict 3
Burn 0
0, 1
77⁄87, 10⁄87
77⁄87, 10⁄87
77⁄87, 10⁄87
Burn 1
47⁄57, 10⁄57
47⁄171, 124⁄171
47⁄57, 10⁄57
47⁄57, 10⁄57
Burn 2
27⁄37, 10⁄37
27⁄37, 10⁄37
27⁄74, 47⁄74
27⁄37, 10⁄37
Burn 3
6⁄11, 5⁄11
6⁄11, 5⁄11
6⁄11, 5⁄11
4⁄11, 7⁄11
Let us try to solve for Laser’s equilibrium strategy, the probability distribution where Missile’s outcome is the same no matter what move they make.
We let p, q, r, and s be the probabilities of predicting 0 through 3 fuel burned, respectively.
In addition to having p + q + r + s = 1, we require
77⁄87 (q + r + s),
47⁄57 (p + r + s) + 47⁄171 q,
27⁄37 (p + q + s) + 27⁄74 r, and
6⁄11 (p + q + r) + 4⁄11 s
all be equal to each other.
Solving this system of equations gives us
p ≈ 34.4%,
q ≈ 44.3%,
r ≈ 40.8%, and
s ≈ −19.5%.
Apparently, predicting 3 fuel used is such a terrible move for Laser that our “optimal” solution wants us to predict it with a negative 19.5% probability!
Unfortunately, Laser cannot actually select moves with negative probability.
We have to add constrains to our acceptable solutions to ensure all probabilities are non-negative.
Adding linear constraints to our problem brings us into the realm of linear programming.
Since we are entering this realm, we can take this opportunity to compute the minimax solution for each player.
For Laser, the minimax solution is to compute a probability distribution that minimizes Missile’s score, i.e., their probability of winning, which we will denote by z, subject to the constraint that Missile will choose the move that maximizes their score for that distribution.
This leads to the following system of linear constraints:
That is, Laser’s strategy is to
predict 0 fuel burned 30.5% of the time,
predict 1 fuel burned 38.1% of the time,
predict 2 fuel burned 31.4% of the time,
and never predict 3 fuel burned.
This lets Missile win at most 61.5% of the time, or equivalently, it lets Laser win at least 38.5% of the time.
Is this minimax strategy really an optimal strategy?
Let us look at Missile’s minimax strategy.
For Missile, we need to optimize the following system of linear constraints:
That is, Missile’s strategy is to
burn 0 fuel 19.9% of the time,
burn 1 fuel 32.0% of the time,
burn 2 fuel 48.2% of the time,
and never burn 3 fuel.
This lets Laser win at most 38.5% of the time, or equivalently, it lets Missile win at least 61.5% of the time.
Still, these strategies surprised me.
Laser is not even aiming at Missile burning 3 fuel.
Shouldn’t Missile avoid being hit by Laser entirely by choosing to burn 3 fuel?
But Missile’s optimal strategy also says to avoid burning 3 units of fuel.
Why?
Upon closer examination, we see that with Missile’s computed optimal strategy, they have a 61.5% chance of winning.
If Missile were to burn 3 fuel, yes, they would avoid being hit by Laser in Round 4.
However, they would begin Round 5 with only 1 remaining fuel.
In that state they would only have a 54.5% chance of winning, worse odds than their optimal strategy that avoids burning 3 fuel.
Laser is not aiming at Missile burning 3 fuel because Laser would love for Missile to burn 3 fuel.
Doing so would increase Laser’s odds of winning from 38.5% to 45.5%.
We see that Laser’s strategy does not entirely rule out all consequences of Missile’s choices.
It only makes it indifferent to Missile’s choices within the support of Missile’s optimal mixed set of moves.
Technically an opponent’s choices can affect the outcome of the game; they can still make moves that benefit the other player.
Continuing with linear programming, we can fill out the table for the probability of winning for Round 4.
Probability table for Round 4
Remaining Fuel
Missile Win Probability
Laser Win Probability
1-
0%
100%
2
≈ 36.4%
≈ 63.6%
3
≈ 50.5%
≈ 49.5%
4
≈ 61.5%
≈ 38.5%
5
≈ 69.9%
≈ 30.1%
6
≈ 76.4%
≈ 23.6%
7
≈ 81.6%
≈ 18.4%
Continuing this way, we can work backwards and compute probability tables for all the rounds until we reach round 1.
Probability table for Round 1
Starting Fuel
Missile Win Probability
Laser Win Probability
7
1005005076075⁄3110959445024 ≈ 32.3%
2105954368949⁄3110959445024 ≈ 67.7%
In conclusion, we found that playing optimally, Missile has an approximately 32.3% chance of winning, which is a little higher than the 25% estimate given by Ethan.
I leave it as an exercise to determine the most fair amount of starting for Missile to start with.
With heartfelt thanks to the many people who have already tried hs-bindgen and
given us feedback, we have steadily been working towards the first official
release (see Contributors for the full list). In case you missed
the announcement of the first alpha, hs-bindgen is a
tool for automatic construction of Haskell bindings for C libraries: just point
it at a C header and let it handle the rest. Because we have fixed some critical
bugs in this alpha release, but we’re not quite ready yet for the first full
official release, we have tagged a second alpha release. In the
remainder of this blog post we will briefly highlight the most important
changes; please refer to the CHANGELOG.md of
hs-bindgen and of
hs-bindgen-runtime for the full list of changes, as well as
for migration hints where we have introduced some minor backwards incompatible
changes.
Bugfixes
The most important fixes for bugs in the generated code are:
The implementation of peek and poke for bitfields was broken, which could
lead to segfaults.
Duplicate record fields are now usable also in Template Haskell mode.
Patterns for unsigned enums now get the right value.
We have also resolved a number of panics during code generation, but those would
not have resulted in incorrect generated code (merely in no code being generated
at all).
New features
Implicit fields arise when one struct (or union) is nested in another,
without any field name or tag:
struct outer {int x;struct{int y;int z;};};
We now support such implicit fields; both the inner (anonymous) struct as well
as the corresponding field of the outer struct will be named after the first
field of the inner struct1:
dataOuter=Outer { x ::CInt , y ::Outer_y }dataOuter_y=Outer_y { y ::CInt , z ::CInt }
For this particular case we could also have chosen to flatten the structure
and add y and z directly to Outer, but that does not work in all cases
(for example, when we have an anonymous struct inside a union), so instead
we opt for consistency and always generate an explicit type for the
inner struct.
Unnamed bit-field declarations, which are used to control padding, are now
supported:
struct bar {signedchar x :3;signedchar:3;// Explicit paddingsignedchar y :2;};
We used to distinguish between parse predicates (which files should
hs-bindgen parse at all?) and selection predicates (for which C
declarations should we generate Haskell declarations?). This was confusing,
and as we are getting better at skipping over declarations with unsupported
features (and that list is dwinding anyway), parse predicates are not that
useful anymore. Parse predicates therefore have been removed entirely; we
simply always parse everything (selection predicates are still very much an
important feature of course).
Some infrastructure for and around binding specifications has been improved.
For example, we now distinguish between macros and non-macros of the same name,
and our treatment of arrays has changed slightly. For example, given
typedefchar T [];void foo (T xs);
we now generate
foo ::Ptr (ElemT) ->IO ()
We do not use Ptr CChar, because T might have an existing binding in
another library (with an external binding specification), and we don’t know
what the type of the elements of T are (it could for example be some
newtype around CChar). Elem is a member of a new IsArray class, part of
the hs-bindgen-runtime.
Top-level anonymous enums are now supported. For example,
(Normally an enum results in a newtype around the enum’s underlying type,
and the patterns are for that newtype instead.)
We now generate bindings for static global variables (such globals are
sometimes used in headers that also contain static function bodies).
All definitions required by the generated code are now (re-)exported from
hs-bindgen-runtime, so that it becomes the only package dependency that
needs to be declared (no need for ghc-prim or primitive anymore).
This list is not complete; some other less common edge cases have also been
implemented.
Conclusions
Although we are still working on some finishing touches before we can release
the first official version of hs-bindgen, it is already being put to good use
on various projects. There are only a handful of missing C
features left, all of which low priority edge cases (though
if you have a specific use case for any of these, do let us know!). So if you
are interested, please do try it out, and let us know if you find any problems.
There should be no major breaking changes between now and the first official
release.
This is the version that uses the
--omit-field-prefixes option, which generates code that relies on
DuplicateRecordFields and OverloadedRecordDot.↩︎
The GHC developers are very pleased to announce the release of GHC 9.12.4.
Binary distributions, source distributions, and documentation are available at
downloads.haskell.org and via GHCup.
GHC 9.12.4 is a bug-fix release fixing many issues of a variety of
severities and scopes, including:
Fixed a critical code generation regression where sub-word division produced
incorrect results (#26711, #26668), similar to the bug fixed in 9.12.2
Numerous fixes for register allocation bugs, preventing data corruption
when spilling and reloading registers
(#26411, #26526, #26537, #26542, #26550)
Fixes for several compiler crashes, including issues with CSE (#25468),
and the simplifier(#26681), implicit parameters (#26451), and the type-class
specialiser (#26682)
Fixed cast worker/wrapper incorrectly firing on INLINE functions (#26903)
Fixed LLVM backend miscompilation of bit manipulation operations
(#20645, #26065, #26109)
Fixed associated type family and data family instance changes not triggering
recompilation (#26183, #26705)
Fixed negative type literals causing the compiler to hang (#26861)
Improvements to determinism of compiler output (#26846, #26858)
Fixes for eventlog shutdown deadlocks (#26573)
and lost wakeups in the RTS (#26324)
Fixed split sections support on Windows (#26696, #26494) and the LLVM backend (#26770)
Fixes for the bytecode compiler, PPC native code generator, and Wasm backend
The runtime linker now supports COMMON symbols (#6107)
Improved backtrace support: backtraces for error exceptions are now
evaluated at throw time
NamedDefaults now correctly requires the class to be standard or have an
in-scope default declaration, and handles poly-kinded classes (#25775, #25778, #25882)
… and many more
A full accounting of these fixes can be found in the release notes. As
always, GHC’s release status, including planned future releases, can be found on
the GHC Wiki status.
We would like to thank these sponsors and other anonymous contributors
whose on-going financial and in-kind support has facilitated GHC maintenance
and release management over the years. Finally, this release would not have
been possible without the hundreds of open-source contributors whose work
comprise this release.
As always, do give this release a try and open a ticket if you see
anything amiss.














 which we write as
which we write as 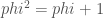 and so
and so ,
,  and
and  .
.



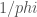 but we can rescale at any time.)
but we can rescale at any time.)


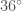 (a tenth of a full turn). If the shorter edges are of length 1, then the longer edges are of length
(a tenth of a full turn). If the shorter edges are of length 1, then the longer edges are of length  is the golden ratio.
is the golden ratio.

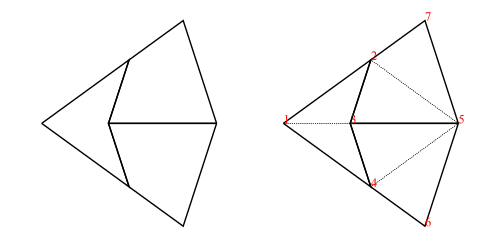
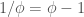 times the scale of the former, to reflect the change in scale.
times the scale of the former, to reflect the change in scale.






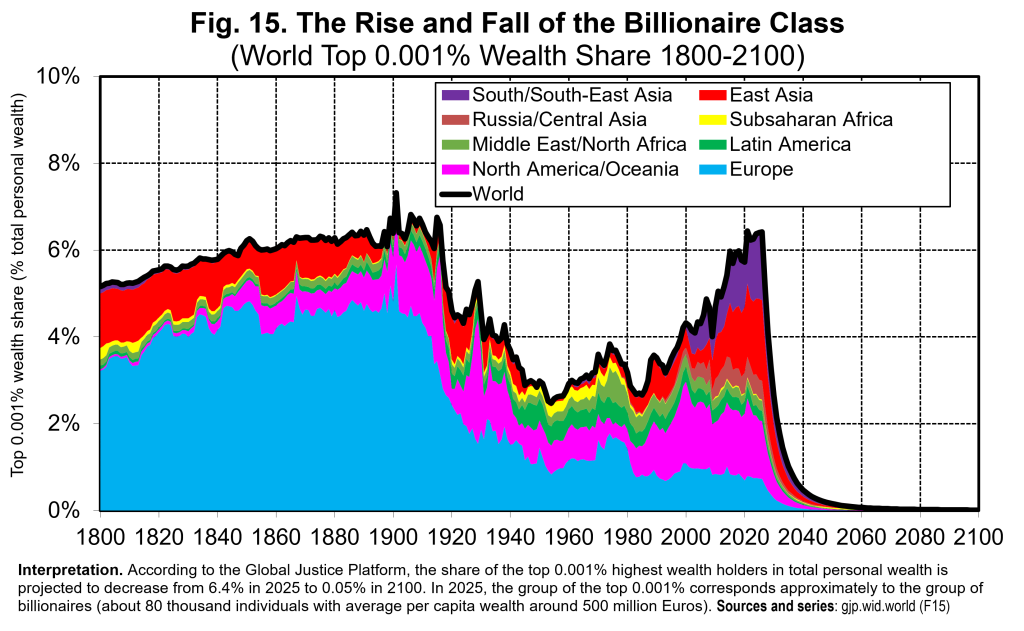
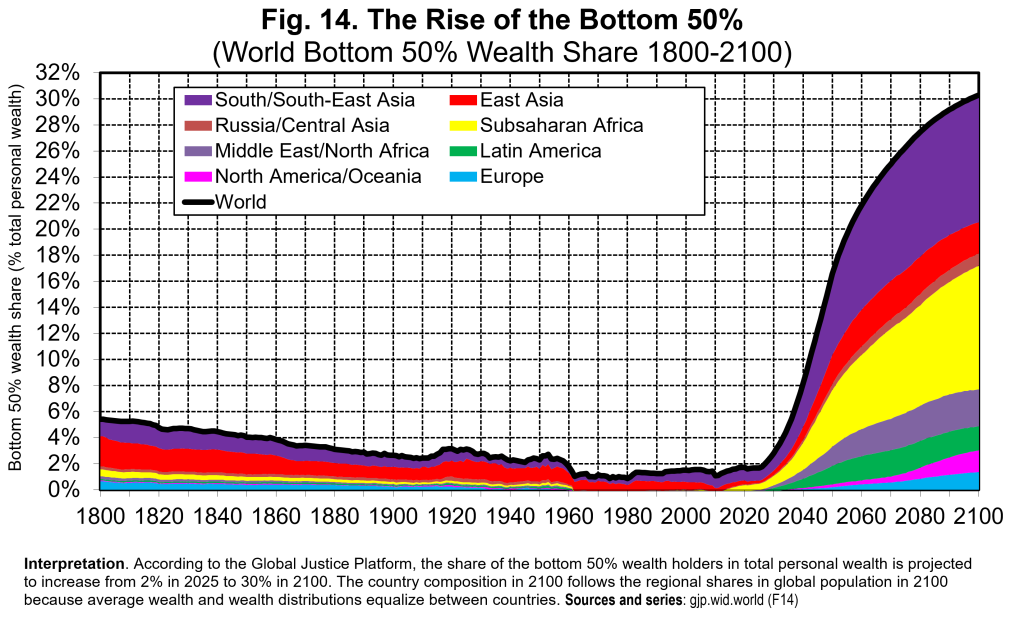
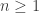 for a function
for a function  is a point
is a point  such that
such that 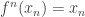 . With this definition, a periodic point of period
. With this definition, a periodic point of period  is also periodic of period
is also periodic of period  for every
for every  for every
for every  from 1 to
from 1 to  , we say that
, we say that  be an interval and
be an interval and  a continuous function. If
a continuous function. If  has a point of least period 3, then it has points of arbitrary least period; in particular, it has a fixed point.
has a point of least period 3, then it has points of arbitrary least period; in particular, it has a fixed point. being open or closed, bounded or unbounded.
being open or closed, bounded or unbounded.![I=[a,b]](https://s0.wp.com/latex.php?latex=I%3D%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) be a compact interval of the real line and
be a compact interval of the real line and  it is
it is  . Then
. Then  be the minimum and the maximum of
be the minimum and the maximum of  , it is
, it is  and
and  . Choose
. Choose 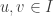 such that
such that 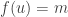 and
and  . Then
. Then  is nonpositive at
is nonpositive at  and nonnegative at
and nonnegative at  . By the intermediate value theorem applied to
. By the intermediate value theorem applied to  ,
,  and
and  , which is a subset of
, which is a subset of 
 be a closed and bounded interval contained in
be a closed and bounded interval contained in  . Then there exists a closed and bounded subinterval
. Then there exists a closed and bounded subinterval  .
.![K=[c,d]](https://s0.wp.com/latex.php?latex=K%3D%5Bc%2Cd%5D&bg=ffffff&fg=333333&s=0&c=20201002) . We may suppose
. We may suppose  , otherwise the statement is trivial. Let
, otherwise the statement is trivial. Let 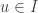 be the largest such that
be the largest such that 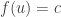 . Two cases are possible.
. Two cases are possible.![x\in(u,b]](https://s0.wp.com/latex.php?latex=x%5Cin%28u%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that
such that 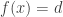 . Let
. Let  , and let
, and let ![J=[u,v]](https://s0.wp.com/latex.php?latex=J%3D%5Bu%2Cv%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Then surely
. Then surely 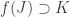 , but if for some
, but if for some  we had either
we had either  or
or  , then by the intermediate value theorem, for some
, then by the intermediate value theorem, for some  Â we would also have either
 we would also have either 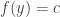 or
or 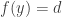 , against our choice of
, against our choice of  for every
for every  be the largest
be the largest ![x\in[a,u]](https://s0.wp.com/latex.php?latex=x%5Cin%5Ba%2Cu%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that
such that ![J=[w,u]](https://s0.wp.com/latex.php?latex=J%3D%5Bw%2Cu%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Then
. Then  be such that
be such that 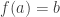 ,
,  , and
, and  . Up to cycling between these three values and replacing
. Up to cycling between these three values and replacing  with
with  , we may suppose
, we may suppose  . Fix a positive integer
. Fix a positive integer  such that
such that  and
and  for every
for every  .
.![L=[a,b]](https://s0.wp.com/latex.php?latex=L%3D%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![R=[b,c]](https://s0.wp.com/latex.php?latex=R%3D%5Bb%2Cc%5D&bg=ffffff&fg=333333&s=0&c=20201002) be the “left” and “right” side of the closed and bounded interval
be the “left” and “right” side of the closed and bounded interval ![[a,c]](https://s0.wp.com/latex.php?latex=%5Ba%2Cc%5D&bg=ffffff&fg=333333&s=0&c=20201002) : then
: then  and
and 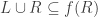 by the intermediate value theorem. In particular,
by the intermediate value theorem. In particular,  , and Lemma 1 immediately tells us that
, and Lemma 1 immediately tells us that 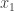 in
in  . Also,
. Also,  , so
, so  , again by Lemma 1: call it
, again by Lemma 1: call it  . This point
. This point  , but
, but  which has period 3. As we can obviously take
which has period 3. As we can obviously take  , we only need to consider the case
, we only need to consider the case 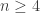 .
.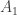 of
of 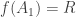 . In turn, as
. In turn, as 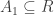 , there also exists a closed and bounded subinterval
, there also exists a closed and bounded subinterval 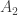 of
of  , again by Lemma 2: but then,
, again by Lemma 2: but then, 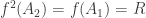 . By iterating the procedure, we find a sequence of closed and bounded intervals
. By iterating the procedure, we find a sequence of closed and bounded intervals  such that, for every
such that, for every 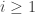 ,
,  and
and  .
. and recall that
and recall that  in the role of
in the role of  as a closed and bounded subinterval not of
as a closed and bounded subinterval not of 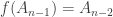 . In turn, as
. In turn, as  of
of  . Following the chain of inclusions we obtain
. Following the chain of inclusions we obtain  . By Lemma 1,
. By Lemma 1,  has a fixed point
has a fixed point  has least period
has least period  , then so has
, then so has  , and in addition
, and in addition  while
while  for every
for every ![i\in[2:n]](https://s0.wp.com/latex.php?latex=i%5Cin%5B2%3An%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Consequently, if
. Consequently, if 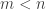 , then
, then 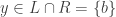 . But this is impossible, because
. But this is impossible, because  by construction as
by construction as  .
. 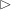 between positive integers is defined as follows:
between positive integers is defined as follows: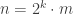 , with
, with  .
.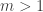 in lexicographic order.
in lexicographic order.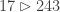 and
and 
 for every
for every  .
. .
. —i.e., the powers of 2—in reverse order.
—i.e., the powers of 2—in reverse order.
 be a continuous function.
be a continuous function.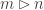 , then
, then  integer it is possible to choose
integer it is possible to choose  . In particular, there are functions whose only periodic points are fixed.
. In particular, there are functions whose only periodic points are fixed.