
Phil Crissman explains Propositions as Types with a dialogue between Achilles and the Tortoise, in the style of Douglas Hofstadter (who in turn was inspired by Lewis Carrol). Lambda Man makes an appearance.
This is the first part of a miniseries on this year’s Symposium on Principles of Programming Languages, a.k.a. POPL 2026, hosted by Jessica Foster.
In this episode, we talk about: undergrad funding and participation, the behind the scenes of AV, choreographic programming, quantum languages, conference catering, and the joy of theory. And at one point, you’ll even hear us get kicked out the venue mid interview. Enjoy!
One example is the observation that adjoint mode automatic differentiation isn't a separate algorithm to forward mode automatic differentiation but a composition of forward mode and transposition. I talked about this in an old paper of mine Two Tricks for the Price of One and it resurfaces more recently in Jax: You Only Linearize Once.
Another example is the REDUCE algorithm used to differentiate a class of stochastic process despite making hard decisions when sampling from a distribution. It turns out this algorithm is nothing but ordinary everyday importance sampling but generalized to probabilities lying in a non-standard algebraic structure. I describe it in a blog article here and you can find out more about extending beyond the non-negative reals in a paper by Abramsky and Brandenberger. You sort of don't have to lift a finger to implement REDUCE - it just happens "for free" when you switch algebraic structure.
Here's a teeny tiny example of another "for free" method that just appears when you switch types.
> module Main where
> import qualified Data.Map.Strict as Map
> import Control.Applicative
> import Control.Monad
> newtype V s a = V { unV :: [(a, s)] }
> deriving (Show)
> instance Functor (V s) where
> fmap f (V xs) = V [ (f a, s) | (a, s) <- xs ]
> instance Num s => Applicative (V s) where
> pure x = V [(x, 1)]
> mf <*> mx = do { f <- mf; x <- mx; return (f x) }
> instance Num s => Monad (V s) where
> (V xs) >>= f = V [ (b, s * t) |
> (a, s) <- xs, (b, t) <- unV (f a) ]
> instance Num s => Alternative (V s) where
> empty = V []
> (<|>) = add
> instance Num s => MonadPlus (V s) where
> mzero = empty
> mplus = (<|>)
> normalize :: (Ord a, Num s, Eq s) => V s a -> V s a
> normalize (V xs) = V $ Map.toList $
> Map.filter (/= 0) $ Map.fromListWith (+) xs
> scale :: Num s => s -> V s a -> V s a
> scale c (V xs) = V [ (a, c * s) | (a, s) <- xs ]
> add :: Num s => V s a -> V s a -> V s a
> add (V xs) (V ys) = V (xs ++ ys)
> insert' :: [(k, v)] -> k -> v -> [(k, v)] > insert' dict k v = (k, v) : dictIt's not very clever, but it does function as a dictionary builder. Let's write it in a more general way using the fact that the list functor is applicative:
> insert :: Alternative m => m (k, v) -> k -> v -> m (k, v) > insert dict k v = pure (k, v) <|> dictWe can go ahead and insert some entries:
> main :: IO () > main = do > let dict1 = empty :: [(Int, Int)] > let dict2 = insert dict1 0 1 > let dict3 = insert dict2 1 0 > print dict3
V instead of []:
> let dict4 = empty :: V Double (Int, Int) > let dict5 = insert dict4 0 1 > let dict6 = insert dict5 1 0 > print $ normalize dict6What has happened is that we've replaced the dictionary update with
D' = D + k⊗vAddition, tensor product, these things are more amenable to differentiation than appending to a list. When using the vector space monad (or applicative) the
(,) operator plays a role more like tensor product.
Note that we're also no longer limited to inserting basis elements, we can use any suitably typed vectors:
> let dict7 = dict6 <|> > (0.5 `scale` pure (0, 0) <|> 0.5 `scale` pure (1, 1)) > print $ normalize dict7This is the key ingredient in the update rule in DeltaNet, described in Parallelizing Linear Transformers with the Delta Rule over Sequence Length at the start of section 2.2.
I was previously interested to see how die rolls in an RPG appear when conditioned on you having survived an unlikely situation. As might have been predicted, if the die rolls contribute to that survival in a largely additive way, for example by being damage scored against a large opponent, then the posterior distribution of the rolls looks exponentially tilted.
But the only virtue of the brute force Monte Carlo method I used was that it was easy to code. It's computationally wasteful. So I wrote a much more performant DSL in Python which I have put on github.
It uses numpy to achieve tolerable numerical performance, but in addition it uses two techniques beyond brute force to make it usable.
One challenge with a probabilistic language is to manage state.
First there's state "in the past": If you're computing probabilities that are sums of many large intermediate states, for example 100 die rolls, you run the risk of running foul of combinatorial explosion.If you write a loop like:
for i in range(100):
t += d(6)
you want to be sure that the += operation erases history (ie. previous values of t) so you aren't tracking all 6^100 individual histories. In this case it's easy but in other cases it might not be so obvious that you have unneeded state lying around. So the code has a simple (and incomplete) backward liveness pass to insert deletions of data that won't be used again. Whenever state is deleted, you can merge histories that are now indistinguishable.

And then there is state "in the future": sometimes you'd like to compute probabilities of data structures like lists but materializing a list results in state that can cause combinatorial explosion. So I support Python style generators allowing you to generate data lazily - for example permutations of cards. So we can bring into existence state just before we need it.

There's another important technique I used: this code uses brute force (though at this point maybe I should stop calling it brute force) so there are many states, each corresponding to a possible set of values for some numpy objects. And we often want to perform a numpy operation for each of these values. We don't need to loop. In many cases a parameterised family of numpy operations is in fact a single numpy operation. This kind of transformation is ubiquitous in GPU computing. So we can interpret the following &&D fight, summing over the combinatorialy large number of ways it could happen, in a few seconds:
@d9.dist
def f():
# Brachiosaurus (Monster Manual 1e p. 24)
hp1 = lazy_sum(36 @ d(8))
# Tyrannosaurus Rex (Monster Manual 1e p.28)
hp2 = lazy_sum(18 @ d(8))
for i in range(14):
print("round", i)
if hp1 > 0 and d(20) > 1:
hp2 = max(0, hp2 - lazy_sum((x for x in 5 @ d(4))))
if hp2 > 0:
# Two claws...
if d(20) > 1:
hp1 -= d(6)
if d(20) > 1:
hp1 -= d(6)
# ...and a bite
if d(20) > 1:
hp1 -= lazy_sum((x for x in 5 @ d(8)))
hp1 = max(hp1, 0)
win1 = hp2 == 0
win2 = hp1 == 0
return win1, win2
Besides its own test suite I also used a large number of questions on the RPG Stack Exchange to build a library of examples for testing.
Of mathematical interest: most of the probability computations take place in a semiring. So most of the numerical computing is simply addition and multiplication. When that's all you're doing, there is the well known technique for working with large integers where you work modulo p[i] for some array of primes and only at the end reconstruct your final result using the Chinese remainder theorem. Less will known is that this works for rationals also. (I conjectured this was true, started deriving it myself, and then learnt there are published methods.) This means we can work with exact rational arithmetic using numpy without the need for a bignum library. This code turns out being related to provenance semirings as it effectively becomes a simple database tracking the provenance of each record.
I originally wrote this code to target GPUs. On my Mac, numpy turned out to be comparable in speed to PyTorch and way faster than TensorFlow. I think this is because those libraries are optimised around data of fairly fixed shape passing through fixed pipelines whereas my code is very ad hoc. I've a feeling a few custom kernels would speed it up a lot. (I may be wrong about this but I do know I can write CUDA/Metal code directly that is many times faster than some of my dice-nine examples.)
And one final note. This is a deeply embedded DSL. I use Python as a host to give me an AST that I interpret. This isn't simply overloading of Python operators.
Last year Ethan Heilman wrote about a simple game he calls Terminal Maneuvers. This game simulates a missile attacking an interstellar ship. The ship has a laser defence system. One player controls the missile, and the other player controls the laser. If the missile hits the ship, Missile wins. If the laser hits the missile, the missile is destroyed and Laser wins.
The complicating factor is that, due to the relative motion of the laser and the ship being a significant fraction of the speed of light, Laser has to aim not at the missile but where the missile will be. This distance allows the missile to perform erratic manoeuvers to prevent Laser from knowing what its future position will be. However, Missile must expend fuel to perform these manoeuvers.
The Terminal Maneuvers game proceeds in five rounds, giving the laser five opportunities to hit the missile. In each round, Missile secretly commits to an amount of fuel they will expend. Laser must “aim” by guessing the amount of fuel expended by Missile. If they guess correctly, there is some probability of destroying the missile, which depends on how far away the missile is and how much fuel the missile expended. The table below shows the probabilities of the missile being destroyed in the various rounds.
| Fuel Cost | Round 1 | Round 2 | Round 3 | Round 4 | Round 5 |
|---|---|---|---|---|---|
| 0 Fuel | 100% | 100% | 100% | 100% | 100% |
| 1 Fuel | 1/6 | 2/6 | 3/6 | 4/6 | 5/6 |
| 2 Fuel | 0% | 1/6 | 2/6 | 3/6 | 4/6 |
| 3 Fuel | 0% | 1/6 | 2/6 | 3/6 | |
| 4 Fuel | 0% | 1/6 | 2/6 | ||
| 5 Fuel | 0% | 1/6 | |||
| 6 Fuel | 0% |
The missile has a limited amount of fuel at the start of the game. Fuel spent earlier in the game means less fuel available later in the game when it is most needed. The amount of starting fuel selects the difficulty of the game. Ethan suggests starting with seven fuel, which empirically gives Missile about a 25% chance of winning.
Laser knows how much fuel the missile has at the start of each round, so it is imperative that Missile does not run out of fuel in the middle of the game. If Laser knows the missile is out of fuel, Laser will predict zero fuel used and will always successfully destroy the missile. That said, as long as Missile has some fuel, choosing to burn zero fuel is still a legitimate option.
Starting with seven fuel, one strategy for Missile would be to burn one fuel on the first four rounds and burn the remaining three fuel on the last round. However, if Laser realizes this is Missile’s strategy, Laser can always predict the correct amount of fuel that will be used by the missile. Taking the product of all the probabilities of Missile’s survival in each round, Missile only has a 4.6% chance of winning. Clearly, Missile’s optimal strategy should be non-deterministic.
I figured this game would be a fun exercise in learning about mixed-strategy (i.e., non-deterministic) Nash equilibrium. This game is a small finite game, so it is reasonably easy to analyze, but it is significantly more complicated than trivial games often used in Nash equilibrium examples.
For these calculations, it is best to find the Nash equilibrium strategy at the endgame and work backward from there. To that end, let us start with the simplest non-trivial endgame. Missile has survived to Round 5 and has 1 fuel left. Missile can choose to burn their last fuel or not, and Laser can choose to aim at no fuel burned or not. This yields the following, game-theoretic payoff matrix, listing the probabilities of missile or laser winning:
| Predict 0 | Predict 1 | |
|---|---|---|
| Burn 0 | 0, 1 | 1, 0 |
| Burn 1 | 1, 0 | 1⁄6, 5⁄6 |
This is a constant-sum game, because the total score of all players is always the same, no matter the outcome. Constant-sum games are also known as zero-sum games since they can be translated into games where the sum of each outcome is zero without affecting any strategy.
The definition of Nash equilibrium is a pair of strategies, one for each player, where neither player individually can change strategies to improve their outcome. Therefore, one potential way for Missile to devise a strategy is to find one where Laser’s chance of winning is the same regardless of the move that they make. Such a strategy is not necessarily going to be possible, but we can give it a try.
Let p be the probability that Missile will burn 0, and let q be the probability that Missile will burn 1. If Laser predicts 0, the probability of them winning is p. If Laser predicts 1, the probability of them winning is 5⁄6 q. If Laser cannot make a choice between these two options to improve their odds, then p = 5⁄6 q. Missile’s probabilities must add up to 1, so we also require p + q = 1.
We have a linear system of two equations and two unknowns, so we can try to solve it. The solution is p = 5⁄11 and q = 6⁄11. Missile burns no fuel with probability 5⁄11 and burns its one fuel with probability 6⁄11. This provides Missile a 6⁄11 chance of winning, regardless of which prediction Laser makes.
On the flip side, Laser’s Nash equilibrium can be computed by choosing a set of probabilities so that Missile’s outcome is the same regardless of whether they choose to burn fuel or not. This time, let p be the probability that Laser will predict 0, and let q be the probability that Laser will predict 1. If Missile burns 0, the probability of them winning is q. If Missile burns 1, the probability of them winning is p + 1⁄6 q. Again, if Missile cannot make a choice between these two options to improve their odds, then q = p + 1⁄6 q. Laser’s probabilities also must add up to 1, so we also require p + q = 1.
Rearranging q = p + 1⁄6 q, we get 5⁄6 q = p, which happens to be the exact same equation Missile had. Thus, their solutions are identical. Laser predicts no fuel burned with a probability of 5⁄11 and predicts one fuel burned with a probability of 6⁄11. This provides Laser a 5⁄11 chance of winning no matter whether Missile has chosen to burn their fuel or not. This chance is the complement to Missile’s 6⁄11 chance of winning, as it has to be.
| Predict 0 | Predict 1 | Predict 2 | |
|---|---|---|---|
| Burn 0 | 0, 1 | 1, 0 | 1, 0 |
| Burn 1 | 1, 0 | 1⁄6, 5⁄6 | 1, 0 |
| Burn 2 | 1, 0 | 1, 0 | 2⁄6, 4⁄6 |
If the game ends in Round 5 with Missile having 2 fuel left, we have the above payoff matrix. We can solve similar linear algebra problems on three variables to find strategies for each player so that the other player’s outcome is the same no matter which of their three choices they make. The solution has Missile burn 0 fuel with probability 10⁄37, burn 1 fuel with probability 12⁄37, and burn 2 fuel with probability 15⁄37, giving Missile a 27⁄37 chance of winning regardless of what Laser’s prediction is.
Laser makes the predictions with the same probability distribution, giving Laser a 10⁄37 chance of winning no matter how much fuel Missile chooses to burn. This sort of distribution is what we might expect: somewhat evenly distributed with a bias towards burning more fuel, which provides some evasion for Missile.
What I found surprising is how when Laser plays at their Nash equilibrium, they simply do not care how much fuel Missile has secretly chosen to burn. Their odds of winning are the same regardless of what Missile reveals. It is as if Laser is no longer playing against Missile at all. Missile’s choices no longer matter. This result is called the “indifference principle.” Later we will see that Missile’s choices sometimes can matter.
Missile feels the same when playing at their equilibrium. No matter what prediction Laser ultimately makes, Missile’s odds of winning have already been fixed by playing at the Nash equilibrium.
In theory, this is what playing poker at a Nash equilibrium should feel like. Based on the state of the board, you make a random selection of calls, folds, or raises according to some appropriate distribution, and your distribution has fixed your expected payout at that point, independent of the choices the other players are going to make. No need to stress over whether your bluff will be called or not.
Before moving on to analyzing Round 4, we can complete a chart of the probability of Missile winning when playing at their Nash equilibrium depending on how much fuel they have remaining.
| Remaining Fuel | Missile Win Probability | Laser Win Probability |
|---|---|---|
| 0 | 0% | 100% |
| 1 | 6⁄11 ≈ 54.5% | 5⁄11 ≈ 45.5% |
| 2 | 27⁄37 ≈ 73.0% | 10⁄37 ≈ 27.0% |
| 3 | 47⁄57 ≈ 82.5% | 10⁄57 ≈ 17.5% |
| 4 | 77⁄87 ≈ 88.5% | 10⁄87 ≈ 11.5% |
| 5 | 137⁄147 ≈ 93.2% | 10⁄147 ≈ 6.8% |
| 6+ | 100% | 0% |
If Missile starts Round 4 with 1 fuel remaining, they are in big trouble. They can only burn fuel in at most one of the two remaining rounds. Therefore, Laser can win by predicting 0 fuel burned in both Round 4 and Round 5. Laser is guaranteed to destroy the missile on one of those two rounds. Missile must start Round 4 with at least 2 fuel remaining if they are to have a chance of winning.
Since the game in each round depends only on the state of Missile’s remaining fuel and not on the specific choices of how that state came to be, we can simplify the analysis of Round 4’s payoff matrix by using each player’s probability of winning Round 5 as their scores in Round 4. Note that Missile does not have the option of burning all their fuel in Round 4, since starting Round 5 with 0 fuel is a guaranteed loss for them, and Laser knows it.
| Predict 0 | Predict 1 | |
|---|---|---|
| Burn 0 | 0, 1 | 27⁄37, 10⁄37 |
| Burn 1 | 6⁄11, 5⁄11 | 2⁄11, 9⁄11 |
To compute Missile’s strategy, we define p and q as before. This time Missile needs to solve the equations p + 5⁄11 q = 10⁄37 p + 9⁄11 q and p + q = 1. The solution has Missile burn 0 fuel with a probability of 148⁄445 and burn 1 fuel with a probability of 297⁄445, which is roughly a 1⁄3rd–2⁄3rd split. This provides Missile a chance of winning with a probability of 162⁄445, or about 36.4%.
Meanwhile, Laser needs to solve the equations 27⁄37 q = 6⁄11 p + 2⁄11 q and p + q = 1. The solution has Laser predict 0 fuel with probability 223⁄445 and predict 1 fuel with probability 222⁄445, which is nearly evenly split. This provides Laser a chance of winning of 283⁄445, or about 63.6%.
In Round 5, each player’s individual payoff matrix was symmetric, which led to Missile and Laser having identical strategies. In Round 4, the individual player’s payoff matrices are no longer symmetric, and Missile and Laser end up with different strategies. Laser picks a nearly 50–50 split because the differences of column scores, 5⁄11 − 1 vs. 9⁄11 − 10⁄37, are nearly equal in magnitude. Whereas Missile picks a 1⁄3rd–2⁄3rd split because the difference of row scores, 27⁄37 vs. 2⁄11 − 6⁄11, differs in magnitude by close to a factor of two.
We can proceed as before, using linear algebra to compute equilibrium strategies for Round 4 with various states of remaining fuel for the missile. However, we run into a problem when Missile has 4 fuel remaining.
| Predict 0 | Predict 1 | Predict 2 | Predict 3 | |
|---|---|---|---|---|
| Burn 0 | 0, 1 | 77⁄87, 10⁄87 | 77⁄87, 10⁄87 | 77⁄87, 10⁄87 |
| Burn 1 | 47⁄57, 10⁄57 | 47⁄171, 124⁄171 | 47⁄57, 10⁄57 | 47⁄57, 10⁄57 |
| Burn 2 | 27⁄37, 10⁄37 | 27⁄37, 10⁄37 | 27⁄74, 47⁄74 | 27⁄37, 10⁄37 |
| Burn 3 | 6⁄11, 5⁄11 | 6⁄11, 5⁄11 | 6⁄11, 5⁄11 | 4⁄11, 7⁄11 |
Let us try to solve for Laser’s equilibrium strategy, the probability distribution where Missile’s outcome is the same no matter what move they make. We let p, q, r, and s be the probabilities of predicting 0 through 3 fuel burned, respectively. In addition to having p + q + r + s = 1, we require
Apparently, predicting 3 fuel used is such a terrible move for Laser that our “optimal” solution wants us to predict it with a negative 19.5% probability! Unfortunately, Laser cannot actually select moves with negative probability. We have to add constrains to our acceptable solutions to ensure all probabilities are non-negative.
Adding linear constraints to our problem brings us into the realm of linear programming. Since we are entering this realm, we can take this opportunity to compute the minimax solution for each player. For Laser, the minimax solution is to compute a probability distribution that minimizes Missile’s score, i.e., their probability of winning, which we will denote by z, subject to the constraint that Missile will choose the move that maximizes their score for that distribution. This leads to the following system of linear constraints:
Using linear programming, we can optimize this system. The optimal solution is
Is this minimax strategy really an optimal strategy? Let us look at Missile’s minimax strategy. For Missile, we need to optimize the following system of linear constraints:
The optimal solution is
This pair of strategies is optimal because Laser wins at least 38.5% of the time by their strategy, and Missile wins at least 61.5% of the time by their strategy, which adds up to 100%. It turns out that for zero-sum games, the minimax, maximin, and Nash equilibrium strategy sets are all identical, and furthermore, these strategies form a convex set. Using a general-purpose Nash equilibrium solver will produce the same pair of optimal strategies.
Still, these strategies surprised me. Laser is not even aiming at Missile burning 3 fuel. Shouldn’t Missile avoid being hit by Laser entirely by choosing to burn 3 fuel? But Missile’s optimal strategy also says to avoid burning 3 units of fuel. Why?
Upon closer examination, we see that with Missile’s computed optimal strategy, they have a 61.5% chance of winning. If Missile were to burn 3 fuel, yes, they would avoid being hit by Laser in Round 4. However, they would begin Round 5 with only 1 remaining fuel. In that state they would only have a 54.5% chance of winning, worse odds than their optimal strategy that avoids burning 3 fuel.
Laser is not aiming at Missile burning 3 fuel because Laser would love for Missile to burn 3 fuel. Doing so would increase Laser’s odds of winning from 38.5% to 45.5%. We see that Laser’s strategy does not entirely rule out all consequences of Missile’s choices. It only makes it indifferent to Missile’s choices within the support of Missile’s optimal mixed set of moves. Technically an opponent’s choices can affect the outcome of the game; they can still make moves that benefit the other player.
Continuing with linear programming, we can fill out the table for the probability of winning for Round 4.
| Remaining Fuel | Missile Win Probability | Laser Win Probability |
|---|---|---|
| 1- | 0% | 100% |
| 2 | ≈ 36.4% | ≈ 63.6% |
| 3 | ≈ 50.5% | ≈ 49.5% |
| 4 | ≈ 61.5% | ≈ 38.5% |
| 5 | ≈ 69.9% | ≈ 30.1% |
| 6 | ≈ 76.4% | ≈ 23.6% |
| 7 | ≈ 81.6% | ≈ 18.4% |
Continuing this way, we can work backwards and compute probability tables for all the rounds until we reach round 1.
| Starting Fuel | Missile Win Probability | Laser Win Probability |
|---|---|---|
| 7 | 1005005076075⁄3110959445024 ≈ 32.3% | 2105954368949⁄3110959445024 ≈ 67.7% |
In conclusion, we found that playing optimally, Missile has an approximately 32.3% chance of winning, which is a little higher than the 25% estimate given by Ethan. I leave it as an exercise to determine the most fair amount of starting for Missile to start with.
We say that a system is reliable if it continues to function correctly when events outside the system affect it. Many factors can impact the reliability of Bazel builds, especially dependencies on external services. In this post, we’ll focus on what can go wrong when your build needs resources you don’t control and what you can do to reduce the risk of build failures.
Some build actions triggered by Bazel might be accessing resources
that are external to your organization.
For Bazel builds, this typically applies to build rules (to build your first-party code) or
repository rules (utilities and tools those rules might need).
When Bazel starts a build, it emits data about network requests,
and you need to make those external requests visible
so that you know what external resources your builds depend on.
You can access this information via the Build Event Protocol (BEP)
which can be written to disk or,
if you operate a remote cache service, your provider might have a BEP viewer.
You can also use the --experimental_repository_resolved_file flag
to produce resolved information about all Starlark repository rules that were executed.
Building a target that depends on a repository rule such as this:
http_archive(
name = "yq_cli",
build_file = "@//tools/yq:BUILD.bazel.gen",
sha256 = "7583d471d9bfe88e32005e9d287952382df0469135f691e044443f610d707f4d",
url = "https://github.com/mikefarah/yq/releases/download/v4.47.1/yq_linux_amd64.tar.gz",
)would result in the following build event (the snippet below is copied from the BEP output):
...
children {
fetch {
url: "https://github.com/mikefarah/yq/releases/download/v4.47.1/yq_linux_amd64.tar.gz"
}
}
...To get an idea of what kinds of artifacts a Bazel build for a reasonably large project might fetch, let’s build a few open-source projects — Envoy, Redpanda, and datadog-agent. These are some of the domains from which at least one resource was fetched when building all targets from these projects:
bcr.bazel.build cdn.azul.com dl.google.com
dl.grafana.com dl.min.io download.gnome.org
files.pythonhosted.org gcr.io github.com
go.dev mirror.bazel.build mirrors.kernel.org
raw.githubusercontent.com pkgconfig.freedesktop.org pypi.org
static.crates.io static.rust-lang.org s3.amazonaws.com
www.antlr.org www.colm.net www.lua.org
www.sqlite.org www.tcpdump.orgWhile most of your external dependencies are going to be declared in build metadata files
such as MODULE.bazel (or legacy WORKSPACE),
some network requests are going to be made by build targets
such as genrules (e.g., by calling curl) or toolchains (e.g., a pip call to the PyPI index).
We’ll see a worked example of this later in the post.
In general, it is advised to rely on MODULE.bazel or WORKSPACE mechanisms
for accessing external dependencies instead of doing so via build or test actions.
Bazel by design lacks support and features for downloads to take place within build actions,
and when attempting to interact with external systems this way,
you will be limited in how you can manage and account for those requests.
Therefore, when building, the complete list of accessed online resources — those that are accounted for by BEP and those that are not — might be much longer. After doing a full build, it might be helpful to audit the network requests made to discover what resources were fetched and a complete inventory of external hosts your build depends on.
Given these external dependencies, these are common problems that could happen to any of them:
This post focuses on strategies to either remove these external dependencies from the critical path, or make failures graceful and recoverable.
The remedies below are intentionally “stackable”: you can start with low-effort
safeguards (e.g., checksums and retries) and progress toward stronger guarantees
(e.g., mirrors and network blocking).
If you’re skimming, you can pick one external host that concerns you
(e.g., github.com or pypi.org) and follow the options
that would let you depend on it more reliably.
External resources may not only vanish or become inaccessible, but also change in place.
Any artifact you download (unless there’s a strong guarantee from a provider), might change its contents
such as when a provider does in-place updates of their releases
(or it could also be a malicious attempt to inject code).
To prevent this issue, SHA-256 digests must be coupled with any artifact you download from the Internet.
Even though when declaring dependencies on external resources
such as with http_archive, providing sha256 attribute is optional,
it is considered a security risk to omit specifying the SHA-256 for remote files to be fetched.
As the majority of build rules and open-source tools used by projects built with Bazel are hosted on GitHub, there are some special concerns that are worth mentioning.
A public GitHub repository might be moved, deleted, or become private (this happened in 2025 with rules_mypy).
If you do have to rely on external rulesets hosted on GitHub,
make sure they are hosted under the bazel-contrib organization
(or help get them migrated at some point) to avoid surprises.
Checksums of dynamically generated archives might change; this has caused Bazel outages before, in 2023. There was some confusion about whether the stability of archives is guaranteed or not. There might be some edge cases such as when a Git repository is renamed, and since Bazel builds rely on stability of archives (for reproducibility and caching among other reasons) it might be best to play it safe and only use releases instead of using source downloads.
It is possible that some of your dependencies need to be obtained from an online resource
that is known to be unstable.
What’s worse, you may not even be able to cache it (or host yourself):
for example, imagine needing to download a short-lived license file for a commercial product from the manufacturer’s server
when starting a build.
To make downloading this file (via a repository rule) more likely to succeed,
consider using the --experimental_repository_downloader_retries flag
to specify the maximum number of attempts to retry upon a download error.
This varies a lot between organizations and the programming languages concerned, but a common approach that is adopted by most organizations is to check in the source code that is used to build a binary, and not the binary itself.
Many engineers would be strongly opposed to checking in any binary,
as Version Control Systems (VCS) are designed and optimised for managing the source code.
However, it is known that some organizations choose to place binary libraries
that are external dependencies of their first-party code
under version control.
This has been seen occasionally in Java projects where .jar libraries
(that nowadays can be managed with Maven / Gradle) were checked in.
Today, this, arguably, might make sense only for legacy projects,
air-gapped or classified networks, and for vendored native libraries
that are hard to rebuild.
Unless you are able to provide top-notch automation for keeping your third-party dependencies checked in under version control up-to-date, patched, and compliant with any licensing constraints, it might be best to rely on a private artifact cache for hosting third-party dependencies.
As your organization grows, you will likely need to invest in a tool that would allow you to organize your resources such as external tools and third-party code packages into repositories. There are lots of commercial solutions on the market such as JFrog Artifactory, Sonatype Nexus, AWS CodeArtifact, and GitLab package registry to name a few.
With a repository manager, once you discover a dependency on an external artifact, you would upload it manually in your internal binary repository and update your build metadata accordingly:
# MODULE.bazel
http_archive(
name = "tool",
...
urls = [
"https://artifacts.company.com/artifactory/project/tools/tool-1.2.3.tar.gz",
"https://www.project.org/source/1.2.3/tool-1.2.3.tar.gz",
]
)URLs from the urls attribute are tried in order until one succeeds.
It is recommended to specify the local binary repository artifact first,
and if the hosted mirror happens to be down, your build would still succeed
provided that, in this case, project.org is up and running.
You could also let your binary repository manager be the only place where Bazel builds can fetch resources from
if you don’t want to depend on external artifacts in any way at all.
This can be achieved by providing a configuration file for the remote downloader
using the --downloader_config flag.
For example, a simple use case may be to block GitHub and instead rewrite fetches to go to an Artifactory instance. This can be done with the following downloader configuration:
rewrite github.com/([^/]+)/([^/]+)/releases/download/([^/]+)/(.*) artifacts.my-company.com/artifactory/github-releases-mirror/$1/$2/releases/download/$3/$4
# if you still have to rely on dynamically generated archives instead of releases
rewrite github.com/([^/]+)/([^/]+)/archive/(.+).(tar.gz|zip) artifacts.my-company.com/artifactory/github-releases-mirror/$1/$2/archive/$3.$4However, support for using Bazel’s downloader needs to be enabled in Bazel rulesets by their authors.
For instance, in rules_python, the pip extension
now supports pulling information from a PyPI compatible mirror
which means that the Bazel downloader can be used for downloading Python wheels.
Take a look at some downloader configurations used in other projects (e.g., 1, 2, 3) to explore how others set up access to external resources and learn the nuances of the configuration declaration syntax.
Additional control of network access can be achieved by blocking some network requests in CI agents using custom firewall rules or other tools of that nature. However, as mentioned earlier, Bazel’s downloader configuration can only rewrite or block requests that Bazel is aware of. This means that not all network traffic in a Bazel build is Bazel-managed traffic.
To illustrate this, let’s declare a dependency on the gawk binary.
When running gawk, its sources are going to be fetched from the GNU FTP server.
Let’s also add a genrule that will download an archive from the same FTP server:
# MODULE.bazel
bazel_dep(name = "gawk", version = "5.3.2")
# BUILD.bazel
genrule(
name = "diffutils",
outs = ["diffutils-3.12.tar.xz"],
cmd = """wget -O "$@" https://ftp.gnu.org/gnu/diffutils/diffutils-3.12.tar.xz""",
)We’ll configure Bazel to use a downloader configuration that blocks fetches from that FTP server:
# bazel_downloader.cfg
block ftp.gnu.org
# .bazelrc
common --downloader_config=bazel_downloader.cfgWhen attempting to run the gawk binary from the ruleset, an error is expectedly raised
since accessing the server is blocked:
$ bazel run @gawk
...
ERROR: java.io.IOException: Configured URL rewriter blocked all URLs:
[https://ftp.gnu.org/gnu/gawk/gawk-5.3.2.tar.xz]However, building a genrule still succeeds
because the downloader configuration does not apply here:
$ bazel build //src:diffutils
...
INFO: From Executing genrule //src:diffutils:
--2026-01-19 10:48:54-- https://ftp.gnu.org/gnu/diffutils/diffutils-3.12.tar.xz
Resolving ftp.gnu.org (ftp.gnu.org)... 209.51.188.20, 2001:470:142:3::b
Connecting to ftp.gnu.org (ftp.gnu.org)|209.51.188.20|:443... connected.
HTTP request sent, awaiting response... 200 OK
Saving to: 'bazel-out/k8-fastbuild/bin/src/diffutils-3.12.tar.xz'External network requests of this nature are hard to audit in a large codebase
since they won’t show up as structured fetch events in BEP output.
To mitigate this, prefer using repository rules and Bzlmod extensions
for any downloads instead of ad hoc shell commands.
Going a step further, you might want to consider forbidding direct calls to applications
that might make network requests (such as curl or wget) in genrule targets, unless explicitly approved.
Where unavoidable, configure targets to access internal repositories instead of public endpoints.
When triggering builds in a Bazel sandbox, they are run in a container (using Linux Namespaces)
to isolate the build actions from the host.
In addition to making your entire filesystem read-only (except for the sandbox directory),
you can also forbid actions access the network.
This is useful in some scenarios when you want to confirm that a build doesn’t make any network requests
such as when running unit tests or integration tests that are not supposed to make any network calls.
See Bazel tags requires-network and block-network
to learn how to control network access for individual build targets.
Keep in mind that cached results of build actions can still be fetched even when blocking the network in a sandbox. So if artifacts needed for a build were uploaded to the Bazel cache previously, you won’t know whether a particular build needs any network resources unless you run the build without cache access. Also, none of the sandbox flags affect any cache as it’s expected that these flags should not affect the output of hermetic actions and making them part of a cache key would worsen the effectiveness of the cache.
With the network disabled in a sandbox, the genrule target we declared earlier fails to build:
$ bazel build //src:diffutils --spawn_strategy=linux-sandbox --nosandbox_default_allow_network
...
ERROR: Executing genrule //src:diffutils failed: (Exit 4): bash failed: ...
Resolving ftp.gnu.org (ftp.gnu.org)... failed: Temporary failure in name resolution.
wget: unable to resolve host address 'ftp.gnu.org'
Target //src:diffutils failed to build
...Since Bazel 8.4, you can also use the --module_mirrors flag
to mirror the source archives.
To take advantage of this, add --module_mirrors=https://bcr.cloudflaremirrors.com in your .bazelrc file.
Keep in mind that this only applies to registry sources and not to other resources fetched by Bazel
(such as downloads happening in the repository rules context).
Note that for Bazel builds, the Bazel Central Registry (BCR) only stores metadata for a Bazel module; the actual artifacts are usually fetched from URLs that point to files hosted online (most often on GitHub).
BCR itself is a sort of external dependency for your builds, too.
Even though it’s hosted on production-grade infrastructure at Google, it can still be impacted by outages and operational mishaps.
The SSL certificate for mirror.bazel.build has expired, causing worldwide CI breakages, at least twice:
once in 2022 and again in 2025.
Refer to Postmortem for bazel.build SSL certificate expiry to learn more.
Configuring Bazel to use https://bcr.cloudflaremirrors.com as a mirror for modules from the BCR helps,
but the Cloudflare mirror doesn’t cover the registry itself.
So if you want to go the extra mile, you might also consider setting up your own BCR index registry
and point Bazel at that instead.
But if this is not feasible, write a playbook for incident response
around build outages caused by external dependencies, so teams don’t have to improvise under pressure.
If your repository manager supports it, you could let your builds download external resources, but every resource that is being fetched is saved into the cache as well. On subsequent builds, the resources are going to be fetched from the cache, if available. This would let you turn random external downloads into a controlled internal dependency without requiring you to pre-vendor everything up front.
If your CI agents are in the same network or cloud region (depending on your infrastructure setup), this could also speed up the builds by having downloads complete faster. Not relying on external resources makes your Bazel builds also a lot more secure as your CI agents will only download data from a trusted source.
If using an off-the-shelf solution, such as the popular JFrog Artifactory, is not possible,
there are some other options.
Bazel picks up proxy addresses from the HTTP_PROXY and HTTPS_PROXY environment variables
and uses these to download files over HTTP and HTTPS, respectively (if specified).
This means you might have success with caching proxy solutions such as Squid and Charles
or by combining Nginx and Varnish HTTP reverse proxies.
Routing requests through a proxy might also help to avoid rate limiting issues
since the external service will see fewer direct requests.
With this configuration, your downloader configuration file would look something like this:
# point all downloads at the mirror
rewrite (.*) {caching-service-url}/$1
# use the original location if the mirror is down
rewrite (.*) $1For a completely custom solution, take a look at the Bazel downloader mirror from Monogon which can be used to mirror Bazel dependencies to a cloud bucket storage such as S3 or GCS. Bazel’s remote asset API lets you use an existing remote cache (content-addressable storage: CAS) as a downloader cache as well. The cache provider service needs to support it, but many existing solutions, both commercial and open-source ones, are compatible.
The --experimental_remote_downloader flag
can be specified to provide a Remote Asset API endpoint URI to be used as a remote download proxy.
To get started, consider using bazel-remote, which has out-of-the-box support for this use case.
Make sure to provide the sha256 for the assets to fetch
so that they can be cached just like any other CAS object.
A remote caching service will automatically download the assets from the URL if they are found in the CAS and cache it thereafter.
Bazel 9 adds support for remote repository caches which make Bazel builds (at least those requiring previously cached assets) extra resilient to external access issues. During outages of external hosting services, those organizations that didn’t have a central repository manager where repository rules artifacts could be stored had to extract files from cache directories on local developer machines and save them to an accessible location within the internal network.
Now these artifacts will be saved into a remote cache similarly to build output results.
To confirm that your remote repository cache works as expected,
you can use the --repository_disable_download flag
after doing a clean build (which should succeed as it will reuse the remote cache entries uploaded in the previous build).
Finally, instead of waiting for the next GitHub outage, you can test your resilience by intentionally breaking access to certain external hosts. In a staging CI environment, temporarily block access to key external systems with firewall rules and verify that your mirrors and caches are used as expected, builds either still succeed, or fail fast with clear error messages, and your runbooks are correct and sufficient.
Bazel projects often depend on external services in subtle ways, and any instability or change in those services can break otherwise healthy builds. You can significantly improve build reliability by making all downloads explicit and verifiable, routing them through managed infrastructure, and tightening how and when network access is allowed. Resilient Bazel builds come from treating external dependencies as first‑class operational risks and turning unpredictable third‑party failures into controlled, recoverable events.
With heartfelt thanks to the many people who have already tried hs-bindgen and
given us feedback, we have steadily been working towards the first official
release (see Contributors for the full list). In case you missed
the announcement of the first alpha, hs-bindgen is a
tool for automatic construction of Haskell bindings for C libraries: just point
it at a C header and let it handle the rest. Because we have fixed some critical
bugs in this alpha release, but we’re not quite ready yet for the first full
official release, we have tagged a second alpha release. In the
remainder of this blog post we will briefly highlight the most important
changes; please refer to the CHANGELOG.md of
hs-bindgen and of
hs-bindgen-runtime for the full list of changes, as well as
for migration hints where we have introduced some minor backwards incompatible
changes.
The most important fixes for bugs in the generated code are:
peek and poke for bitfields was broken, which could
lead to segfaults.We have also resolved a number of panics during code generation, but those would not have resulted in incorrect generated code (merely in no code being generated at all).
Implicit fields arise when one struct (or union) is nested in another, without any field name or tag:
We now support such implicit fields; both the inner (anonymous) struct as well as the corresponding field of the outer struct will be named after the first field of the inner struct1:
For this particular case we could also have chosen to flatten the structure
and add y and z directly to Outer, but that does not work in all cases
(for example, when we have an anonymous struct inside a union), so instead
we opt for consistency and always generate an explicit type for the
inner struct.
Unnamed bit-field declarations, which are used to control padding, are now supported:
We used to distinguish between parse predicates (which files should
hs-bindgen parse at all?) and selection predicates (for which C
declarations should we generate Haskell declarations?). This was confusing,
and as we are getting better at skipping over declarations with unsupported
features (and that list is dwinding anyway), parse predicates are not that
useful anymore. Parse predicates therefore have been removed entirely; we
simply always parse everything (selection predicates are still very much an
important feature of course).
Some infrastructure for and around binding specifications has been improved. For example, we now distinguish between macros and non-macros of the same name, and our treatment of arrays has changed slightly. For example, given
we now generate
We do not use Ptr CChar, because T might have an existing binding in
another library (with an external binding specification), and we don’t know
what the type of the elements of T are (it could for example be some
newtype around CChar). Elem is a member of a new IsArray class, part of
the hs-bindgen-runtime.
Top-level anonymous enums are now supported. For example,
results in
(Normally an enum results in a newtype around the enum’s underlying type,
and the patterns are for that newtype instead.)
We now generate bindings for static global variables (such globals are sometimes used in headers that also contain static function bodies).
All definitions required by the generated code are now (re-)exported from
hs-bindgen-runtime, so that it becomes the only package dependency that
needs to be declared (no need for ghc-prim or primitive anymore).
This list is not complete; some other less common edge cases have also been implemented.
Although we are still working on some finishing touches before we can release
the first official version of hs-bindgen, it is already being put to good use
on various projects. There are only a handful of missing C
features left, all of which low priority edge cases (though
if you have a specific use case for any of these, do let us know!). So if you
are interested, please do try it out, and let us know if you find any problems.
There should be no major breaking changes between now and the first official
release.
This is the version that uses the
--omit-field-prefixes option, which generates code that relies on
DuplicateRecordFields and OverloadedRecordDot.↩︎
The GHC developers are very pleased to announce the release of GHC 9.12.4. Binary distributions, source distributions, and documentation are available at downloads.haskell.org and via GHCup.
GHC 9.12.4 is a bug-fix release fixing many issues of a variety of severities and scopes, including:
Fixed a critical code generation regression where sub-word division produced incorrect results (#26711, #26668), similar to the bug fixed in 9.12.2
Numerous fixes for register allocation bugs, preventing data corruption when spilling and reloading registers (#26411, #26526, #26537, #26542, #26550)
Fixes for several compiler crashes, including issues with CSE (#25468), and the simplifier(#26681), implicit parameters (#26451), and the type-class specialiser (#26682)
Fixed cast worker/wrapper incorrectly firing on INLINE functions (#26903)
Fixed LLVM backend miscompilation of bit manipulation operations (#20645, #26065, #26109)
Fixed associated type family and data family instance changes not triggering recompilation (#26183, #26705)
Fixed negative type literals causing the compiler to hang (#26861)
Improvements to determinism of compiler output (#26846, #26858)
Fixes for eventlog shutdown deadlocks (#26573) and lost wakeups in the RTS (#26324)
Fixed split sections support on Windows (#26696, #26494) and the LLVM backend (#26770)
Fixes for the bytecode compiler, PPC native code generator, and Wasm backend
The runtime linker now supports COMMON symbols (#6107)
Improved backtrace support: backtraces for error exceptions are now
evaluated at throw time
NamedDefaults now correctly requires the class to be standard or have an
in-scope default declaration, and handles poly-kinded classes (#25775, #25778, #25882)
… and many more
A full accounting of these fixes can be found in the release notes. As always, GHC’s release status, including planned future releases, can be found on the GHC Wiki status.
GHC development is sponsored by:
We would like to thank these sponsors and other anonymous contributors whose on-going financial and in-kind support has facilitated GHC maintenance and release management over the years. Finally, this release would not have been possible without the hundreds of open-source contributors whose work comprise this release.
As always, do give this release a try and open a ticket if you see anything amiss.

Athena and Ares argue over human nature, and agree to test three great minds of the age.
First, they approach Aristotle in the Lyceum and propose a bargain. “If you ask it of us, the one you love most in the world will perish, but you will be made rich beyond imagining.” Aristotle barely hesitates. “No,” he says. “To destroy the very purpose of living for the sake of the mere means is the mark of a man who lacks wisdom.”
Next, they approach Plato, finding him pacing in an olive grove of his Academy. They offer the same proposal. “I decline,” he says. “Love allows us to glimpse the ideal of pure beauty, but wealth is an anchor to the material world.”
Finally, they approach Socrates, wandering barefoot in the crowded dusty stalls of the Agora. The gods approach him with the same bargain: “If you ask it of us, Xanthippe, whom you love most in the world, will perish — ”
“I ask it!” he blurts out.
Athena blinks. “You did not even hear the rest. We were going to say you would be given wealth beyond measure.”
Socrates shrugs. “Keep it. This was never about money.”
Millenia later, Athena is still smarting from losing the bet, and she demands a rematch. Searching for another Greek philosopher, they instead find a middle aged woman writing a novel called Atlas Shrugged. She’s a philosopher, and Atlas was Greek, so that’s close enough.
“If you ask it,” Athena says to her, “we will make you wealthy beyond measure, but then in return, your true love will be taken from you.”
The woman looks up, bored, and asks “Why give me the money if you’re just going to take it right back?”
Peter is a professor at the University of Freiburg, and he was doing functional programming right when Haskell got started. So naturally we asked him about the early days of Haskell, and how from the start Peter pushed the envelope on what you could do with the type system and specifically with the type classes, from early web programming to program generation to session types. Come with us on a trip down memory lane!
This is the thirtieth edition of our Haskell ecosystem activities report, which describes the work Well-Typed are doing on GHC, Cabal, HLS and other parts of the core Haskell toolchain. The current edition covers roughly the months of December 2025 to February 2026.
You can find the previous editions collected under the haskell-ecosystem-report tag.
We offer Haskell Ecosystem Support Packages to provide commercial users with support from Well-Typed’s experts while investing in the Haskell community and its technical ecosystem including through the work described in this report. To find out more, read our announcement of these packages in partnership with the Haskell Foundation. We need funding to continue this essential maintenance work!
Many thanks to our Haskell Ecosystem Supporters: Standard Chartered, Channable and QBayLogic, as well as to our other clients who also contribute to making this work possible: Anduril, Juspay and Mercury; and to the HLS Open Collective for supporting HLS release management.
Matthew Pickering announced that he will be leaving the company and moving to a non-Haskell
role at the end of March.
Working with Matt has been a joy – more than his deep technical insight
or sharp intuition, it’s the warmth of his vision for how to work together and
his generosity that has made him such a force within the team.
He was also a beacon that could rally the community in difficult times, perhaps
most memorably with his technical and social contributions in consolidating
Haskell IDEs with the creation of the Haskell Language Server.
His dedication to tooling has also been an inspiration, with his work on
ghc-debug and on profiling an invaluable contribution to our understanding
of memory usage of Haskell programs.
The Haskell toolchain team at Well-Typed currently includes:
In addition, many others within Well-Typed contribute to GHC, Cabal, HLS and other open source Haskell libraries and tools. This report includes contributions from Alex Washburn, Duncan Coutts, Wen Kokke and Wolfgang Jeltsch in particular.
We are active participants in community efforts for developing the Haskell language and libraries. Rodrigo joined the GHC Steering Committee in December, alongside Adam Gundry. Wolfgang joined the Core Libraries Committee in February.
The Haskell Debugger (hdb) has been made more robust and more features were implemented by Rodrigo, Matthew, and Hannes.
Most notably, the debugger now:
-finfo-table-map for the latter)To run hdb you need to use GHC 9.14 and to configure the IDE accordingly. Please refer to the installation instructions. Apart from that, if HLS just works on your codebase, so should the debugger!
GHC’s eventlog already lets Haskell programs emit rich runtime telemetry, but
the workflow has historically been to run the program to completion and inspect
the eventlog afterwards. eventlog-live
allows us instead to monitor the program as it is running. Wen continued work on
this project, taking significant steps towards making it production-ready, including:
extending eventlog-live with support for the OpenTelemetry protocol
(#119),
bringing the underlying
eventlog-socket library
closer to being ready for general use, by
adding a testsuite (#27).
fixing a litany of issues with the C code
(#38), and
finalising the user-facing API (#43),
adding support for custom commands in
eventlog-socket
(#36).
The Language.Haskell.Syntax module hierarchy is intended to be a stable,
public API for the Haskell AST — one that external tools could eventually depend
on without coupling themselves to GHC internals, reducing ecosystem breakage.
Right now, that goal is undermined by lingering dependencies on internal modules
under the GHC hierarchy.
Alex, with help from Rodrigo, has been systematically removing these edges in the dependency graph:
Language.Haskell.Syntax.Type no longer depends GHC.Utils.Panic
(!15134, #26626).Language.Haskell.Syntax.Decls no longer depends on GHC.Unit.Module.Warnings
(!15146, #26636), nor on GHC.Types.ForeignCall (!15477, #26700) or
GHC.Types.Basic (!15265, #26699).Language.Haskell.Syntax.Binds no longer depends on GHC.Types.Basic
(!15187, #26670).Once this work is done, it will be possible to consider moving the AST into a separate package, and taking further steps towards increasing modularity of the compiler.
base packageHistorically, the base package was used as both the user-facing standard
library and a repository of GHC-specific internals, with much special treatment
in the compiler. This means GHC and base versions are tightly coupled, and
makes upgrading to new compiler versions unnecessarily difficult.
GHC developers have made significant progress towards making base a normal Haskell
package: ghc-internal has been split out as a separate library, base no
longer has a privileged unit-id in the compiler, and Cabal now allows
reinstalling it.
Matt posted a summary of progress and outlined possible next steps to seek community consensus on the direction of travel. The reinstallable-base repository collects documents and discussion on the effort.
Wolfgang continued various pieces of technical groundwork:
cleaning up many unused known-key names in the compiler (!15184, !15190, !15211, !15213, !15217, !15218, !15219, !15215),
finishing the process of removing GHC.Desugar from base (!15433),
refining the import list of System.IO.OS to aid in modularity (!15567).
Wolfgang improved the public API of base relating to OS handles, to make the
API more stable across platforms and avoid the need for users to depend on
GHC-internal implementation details (!14732, !14905). While in the area, he
fixed a bug in the implementation of hIsReadable and hIsWritable for duplex
handles (#26479, !15227), and a mistake in the documentation of hIsClosed
(!15228).
GHC bug #26416 has occupied the attention of the team for quite some time. Initially thought to be an issue with specialisation, a reproducer that Sam and Magnus created showed that the issue is in fact a bug in absence analysis — an optimisation that identifies and removes unused function arguments — in which GHC would erroneously conclude that a used argument was in fact absent.
Andreas helped investigate the root cause, before Zubin finally took the torch and put up a solution (!15238).
GHC’s changelogs have not always been as complete or reliable as the community deserves. Keeping changelogs accurate across backports has also been a major source of frustration for release managers.
This is why, after a discussion initiated by Teo Camarasu in #26002, we have decided
to adopt the changelog.d system —
already in use by the Cabal project — in which each change is a separate file
in the changelog directory.
This eliminates the merge conflicts that make backporting painful, and makes it
easier to associate MRs with changelog entries.
Zubin has been spearheading the effort, with the intention to switch to this new method of changelog generation right after the fork date for GHC 10.0.
Sam reviewed the implementation of the QualifiedStrings
extension by Brandon Chinn (!14975).
This allows string literals of the form ModName."foo"
(interpreted as ModName.fromString ("foo" :: String)).
Sam made several changes to the treatment of Coercible constraints in the
typechecker (!14100):
Coercible constraints are greatly
improved, an oft-requested improvement (#15850, #20289, #23731, #26137).
Error messages now consistently mention relevant out-of-scope data
constructors, provide import suggestions, and include additional
explanations about roles (when relevant).Magnus implemented several fixes to the implementation of ExplicitLevelImports:
Sam improved the reporting of “valid hole fits”, adding support for suggesting bidirectional pattern synonyms (#26339) and properly dealing with data constructors with linear arguments (#26338).
Sam investigated a typechecking regression starting in GHC 9.2 with the
introduction of the Assert type family to improve error messages involving
comparison of type-level literals (#26190), posting his analysis to the ticket.
To tackle this, he opened GHC proposal #735, which is still in need of further community feedback.
Sam minimised a bug with rewrite rules (#26682), which allowed Simon Peyton Jones to identify and fix the bug (!15208).
Sam improved how existential variables are displayed in Haddock documentation (!15099, #26252).
Typeable evidence (#26846, !15442).singletons library producing non-deterministic names
(singletons #629,
th-desugar #240).Sam finished up and landed a long-standing MR by Chris Wendt (!10133) which fixed a plugin-related issue.
Sam fixed a regression in ghc-typelits-natnormalise
in which the plugin would cause GHC to fall into an infinite loop
(ghc-typelits-natnormalise #116, #118).
Rodrigo announced that work described in #23218 evolved into the POPL 2026 paper “Lazy Linearity for a Core Functional Language”, which presents a way to type linearity in GHC Core that is robust to almost all GHC optimisations, together with a GHC plugin validating programs at each optimisation stage.
With the oversight of Andreas, Sam carefully reconsidered the treatment of register formats in the register allocator and liveness analysis. This culminated in !15121:
@aratamizuki on !15121.Sam put up a small fix for the mapping of registers to stack slots, fixing an oversight in the case that registers start off small and are subsequently written at larger widths (#26668, !15185).
Sam reviewed a GHC contribution by @sgillespie adding SIMD primops for
abs and sqrt operations (!15236), suggesting more efficient implementations of
certain operations.
Andreas investigated potential missed specialisations, which allowed Simon Peyton Jones to make further progress in improving the specialiser (#26831, !15441).
Sam investigated several bugs to do with the interactions of join points with
ticks (#14242, #26157, #26642, #26693) and casts (#14610, #21716, #26422).
He fixed the main bug (#26642, !15538), which was due to incorrect
transformations in mergeCaseAlts. He also undertook a general refactor of
the area and, pinning down the overall handling of casts and ticks under
join points in a Note.
Matt fixed a decoding failure for stg_dummy_ret by using INFO_TABLE_CONSTR
for its closure (#26745, !15303).
Duncan fixed long-standing inconsistencies in eventlog STOP_THREAD status
codes (#26867, !15522).
Andreas improved the documentation of the -K RTS flag in !15365 (#26354).
Matt and Hannes improved the reporting of backtraces when using error
(!15306, !15395, #26751). This involved opening two CLC proposals
(CLC #383,
CLC #387).
Hannes continued working on the implementation of stack annotations and stack decoding (#26218), including:
ghc-stack-profiler,
a profiler that relies on stack annotations instead of heavier profiling
mechanisms, with the eventlog-socket
library; andghc-stack-annotations
compatibility library for annotating the stack.Rodrigo removed an incorrect assertion that fired when decoding a BCO whose bitmap has no payload (#26640, !15136).
Zubin fixed a GHC 9.14.1 build issue due to missing .cabal files for
ghc-experimental and ghc-internal in the source tarball (#26738, !15391).
Andreas investigated the use of Cabal’s --semaphore feature to speed up GHC builds slightly (#26876, !15483).
There are some issues preventing us from enabling this unconditionally
(#26977, Cabal #11557).
Magnus ensured the user’s guide can be generated with old versions of Python to fix CI build failures on some older containers (!15127).
Magnus updated the Debian images used for CI (ci-images !183,
!178).
Sam finished up the work of Sven Tennie on testing floating point expressions
in the test-primops test
framework for GHC (test-primops !19).
This is preparatory work for improving the robustness of GHC’s handling of
floating point (#26919).
Andreas updated the nofib GHC benchmarking suite to fix issues that Sam ran
into when trying to use it, updating the CI in the process
(nofib !81, !82, !83).
Magnus worked on the infrastructure for the GitLab instance used for the GHC project, bringing up new runners for CI and switching to a new verification system to approve new users which makes it easier for new contributors to open issues.
Magnus and Andreas helped the Haskell infrastructure team address Gitlab outages on short notice in order to improve availability of the GHC Gitlab instance.
Andreas and Magnus organized temporary CI capabilities sponsored by WT during a temporary outage of one of GHC’s CI runners.
Sam added support for setting the logging handle via the library interface of Cabal,
a significant milestone in updating cabal-install to compile packages with
the Cabal library without invoking external processes (Cabal #11077).
Matt helped Matthías Páll Gissurarson to fix a bug in which cabal haddock was looking for
files in the wrong directory (Cabal #11475, #11476).
Matt fixed a bug with broken Haddocks locally due to non-expanded ${pkgroot}
variable (Cabal #11217,
#11218).
Matt fixed some issues with cabal repl silently failing
(Cabal #11107,
#11237).
In collaboration with Zubin and Andreas, Hannes investigated the root cause of
HLS issue #4674,
posting his analysis in this comment.
In short, the problem was that the hlint plugin was using an incompatible
version of ghc-lib-parser, and a version mismatch in this library was causing
segfaults due to changes to the GHC.Data.FastString implementation between
the versions.
Hannes disabled the hlint plugin on GHC 9.10 to work around this issue
(HLS PR #4767).
Hannes reviewed and assisted with HLS PR #4856
by @vidit-od. This PR makes HLS use the stored server-side diagnostics for
code actions, in order to make them more responsive. This fixes HLS issue #4805.
Hannes helped land long-running HLS PR #4445
by @soulomoon, which allows files to be loaded concurrently in batches in
order to improve responsiveness of HLS.
Zubin and Hannes worked together to update HLS to work with GHC 9.14 (HLS PR #4780).
Hannes worked on general maintenance of the HLS project:
Hannes and Zubin implemented some fixes to Windows CI (HLS PR #4800, HLS PR #4768).
Hannes merged the hls-module-name-plugin into hls-rename-plugin in
HLS PR #4847.
Hannes improved the robustness of the hls-call-hierarchy-plugin-tests in
HLS PR #4834
by using VirtualFileTree.
Hannes also worked on hie-bios:
hie-bios PR #496)hie-bios PR #495)OsPath (hie-bios PR #493)Rodrigo continued work on the new Haskell Debugger.
Matt and Rodrigo introduced a DSL for evaluation on the remote process, which allows the debuggee to be queried from a custom instance, making it possible to implement visualisations which rely on e.g. evaluatedness of a term (#139).
Matt improved support for exceptions: break-on-exception breakpoints now provide source locations (#165).
Rodrigo allowed call stacks to be inspected in the debugger (#158).
Hannes introduced support for stack decoding and viewing custom stack annotations (#172).
Rodrigo made the Haskell Debugger use the external interpreter (#170), which paves the way for multi-threaded debugging (see also #140). This change also allowed Rodrigo to implement Windows support (#184) with the help of Hannes.
Matt fixed a bug in the handling of data constructors with constraints (#175).
Hannes improved caching in the CI (#173).
ghc-debugMatt and Hannes fixed several issues with AP_STACK closures
(!79,
!80,
!86).
Hannes implemented asynchronous heap traversal in ghc-debug-brick,
making the interface more responsive
(!78).
Hannes added history navigation and search caching to the ghc-debug-brick
interface
(!83).
Hannes added a summary row to the string counting table view (!81), and fixed the search limit not being honoured during incremental searches (!76).
A couple of years back I was discussing the Rhind Mathematical Papyrus
(RMP). It includes a table expressing as a sum
$$\frac1{a_1}+\frac1{a_2}+\dots+\frac1{a_k} $$ fractions with
numerator 1 (“unit fractions”). I said:
Getting the table of good-quality representations of
is not trivial, and requires searching, number theory, and some trial and error. It's not at all clear that
.
Today I wondered: did Ahmes (the author) have the best possible
expansions for all the values, or were there some
improvements the Egyptians had missed?
It turns out, yes! Or rather, maybe!
In
On the Egyptian method of decomposing into unit fractions
the author, Abdulrahman A. Abdulaziz, points out that for
the Rhind Mathematical Papyrus gives the expansion
$$\frac2{95} = \frac1{60} + \frac1{380} + \frac1{570}$$
but so it could have been
written as $$\frac2{95} = \frac1{60}+\frac1{228}.$$
But wait, maybe that wasn't an error. The Egyptians, like everyone,
often had to multiply by 10. (In fact, the RMP itself, right after
its table, has a shorter table of expansions of
.) And
is trivially
multiplied by 10, whereas
isn't. There is some
indication that Ahmes preferred fractions with even denominators,
because they are easier to double, and the usual Egyptian method of
multiplication required repeated doubling. But the Egyptians also
sometimes decupled while multiplying, and the
expansion would have made both of those
easy.
The methods by which Ahmes chose the expansions of , and
the criteria by which he preferred one to another, are still unknown;
he doesn't explain them. So it's tough to say that any item was or
wasn't “best” from Ahmes' point of view.
A fair coin, an unfair offer, and the price of certainty.
I sat down to work out a classic probability problem numerically, and accidentally built a casino.
In 1654, a gambler named Antoine Gombaud posed a question to Blaise Pascal: two players are in a race to win a certain number of points. The game is interrupted. How should they divide the pot?
Pascal wrote to Fermat, and their correspondence became one of the founding documents of probability theory. The answer is elegant: if you need a more points and your opponent needs b more, you can compute the fair split with a simple recurrence. Let P(a, b) be your probability of winning:
Every value in this table is a fraction with a power-of-2 denominator, and the numerators are just Pascal’s triangle. Beautiful math, clean solution, problem solved since the 17th century.
I built an interactive table to explore it. And then I thought: what if this were a game?
You and The House race to a target score. Each round, a fair coin is flipped — heads you score, tails The House scores. First to the target wins a pot of money.
But before each flip, judges look at the current game state, consult the probability table, and offer you cash to walk away. Accept, and you take the money. Decline, and the coin is flipped.
The question, every single round, is: to flip or not to flip?

You can play at willowdale.online/flip.
The judges know the exact fair value of your position — they have the same formula Pascal and Fermat computed. If you have a 37.5% chance of winning a $10,000 pot, your fair value is $3,750.
But they don’t offer fair value. They offer the nearest “clean” fraction of the pot that sits strictly below your true odds.
“Clean” means small denominators whose only prime factors are 2, 3, and 5 — fractions like 1/3, 3/8, 7/20, nothing with a denominator above 20. These produce dollar amounts that look like something a human came up with: $3,333, $3,750, $3,500. Not $3,077 or $3,846, which look like someone ran the numbers to the last penny.
So if your fair value is $3,770 (193/512 of the pot), the judges offer $3,750 (3/8). Barely below fair, and a beautifully round number. If your fair value is $1,875 (3/16), they offer $1,666 (1/6). An 89% offer — a real discount, but still a clean, human-sounding number.
This matters psychologically. Round numbers feel like ballpark estimates — casual, generous, not fully analyzed. Precise numbers feel calculated. When the judges offer $7,500, it sounds reasonable. If they offered $7,517, you’d immediately suspect they did the math and it’s in their favor. The irony is that $7,517 is a better deal for you — but I think you’d be less likely to take it. The round number keeps your guard down.
The algorithm is deterministic — same game state, same offer every time. Just math dressed up in a game show contract.
Since the offers are always strictly below fair value, the play that maximizes your expected winnings is to never accept a deal. The coin is fair, the game has zero house edge, and every offer leaves money on the table. A player who always flips would win 50% of their games and, on average, neither gain nor lose.
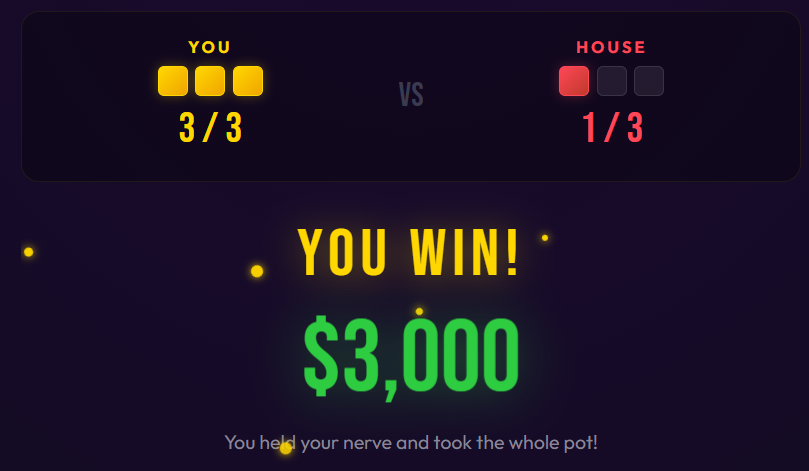
And yet.
When you’re ahead 4–3 in a race to 10, and the contract says $6,000, and you’ve already paid $5,000 to enter this game… you hesitate. That’s a guaranteed profit. The alternative is variance — maybe you win $10,000, but you are not that far ahead. Maybe your luck turns and you lose everything.
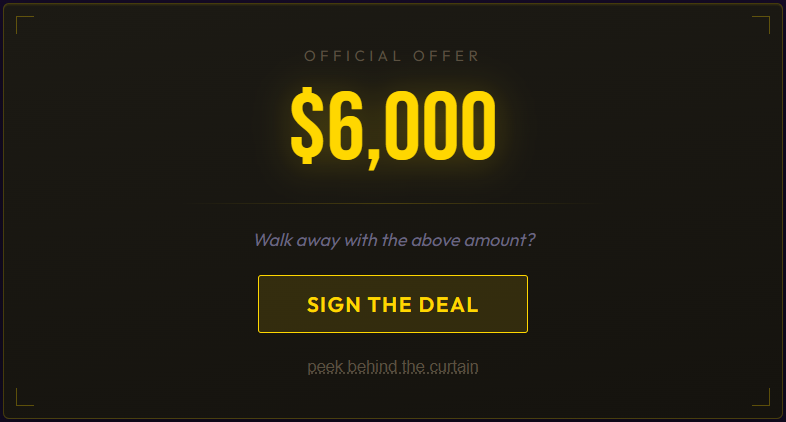
You know the offer is below fair. You can peek behind the curtain and see the exact numbers. The judges are shortchanging you by $128. But $128 feels like nothing when the alternative is watching your lead evaporate flip by flip.
So you sign. And $128 goes into the casino’s pocket.

This is what makes the game unusual. In blackjack or roulette, the house edge is baked into the rules — you can’t avoid it no matter how disciplined you are. Here, the game has no edge at all. The coin is fair. The race is symmetric. The only source of profit is human nature. Every dollar the casino makes is expected value that a player voluntarily left on the table.
Play for a while and you start to notice specific situations where the offer gets harder to refuse.
Managing risk. A guaranteed $7,500 is safer than a coin flip worth $7,734. In real life, you might need that money for rent. Variance has a real cost, and paying a premium for certainty can be entirely rational. There is a sophisticated argument for sometimes making decisions that reduce your expected value: bankroll management, survival probability and duration. Here the stakes are fictional, your bankroll buys nothing except more fair coin flips, and going broke is solved by refreshing your web browser, so that case is weaker — but it doesn’t feel weaker when your bankroll is shrinking and the judges are holding out real-looking money.
Mis-anchoring. The rational comparison is always between the offer and the expected value of continuing to flip. But that’s rarely the comparison your brain actually makes. If you were staring at a $0 offer last round and now the judges are offering $500, you’re comparing to the $0 — not to the $625 fair value. If your bankroll started at $10,000 and you’re down to $7,000, and the judges offer $3,200, you’re comparing to $10,000 — because taking the deal would put you above where you started. In both cases, the reference point that feels relevant has nothing to do with the expected value of this game.
Black and white thinking. When you’re behind in the race, the most likely single outcome is that you lose. If the judges offer $500 and your odds of winning are 6%, it feels like a choice between $500 and nothing. But expected value accounts for the 6% — the rare wins are big enough to compensate for all the losses across many games. You just don’t experience many games at once. You experience this one, where you’ll probably lose, and where the person who took $500 looks smart 94 times out of 100.
Imaginary momentum. You lose three flips in a row and it feels like the coin has turned against you — time to take the deal before things get worse. Or you win three in a row and feel like you’re on a streak that shouldn’t be interrupted. The coin has no memory. Each flip is independent. But the human brain is a pattern-recognition machine, and it will find narratives in random sequences whether they’re there or not.
The judges in this game are clever, but simple — they mechanically pick the nearest clean fraction below fair value, blind to everything except the current expected value.
But the optimal offer would be very different. The right objective isn’t just the EV gap (fair value minus offer). It’s:
EV gap × P(acceptance | entire game trajectory)
A huge gap with low acceptance is worthless — the player just turns it down. A tiny gap with high acceptance is pennies. The sweet spot is a moderate discount the player almost can’t refuse.
And that acceptance probability depends on far more than just the current score — it depends on everything described above: the bankroll trajectory, the recent streak, what the last offer was, how long the player has been sitting there.
A perfect judge would think about all of this, and decide exactly what it can get you — tired, frustrated, scared little you — to accept. The clean-fraction heuristic doesn’t. And yet it still works. I still sign those offers.
The game is a playable demonstration of why casinos stay in business, maybe even why people accept below-market returns for safety, and why insurance companies are profitable.
The math is always available — right there behind a curtain. If your goal is to maximize expected dollars, the answer is always to flip the coin. And yet, round after round, the judges offer deals, and I sign them.
Play the game at willowdale.online/flip. It’s free, the coin is fair, and you will almost certainly take a deal you know you shouldn’t.
The GHC developers are very pleased to announce the availability of the release candidate for GHC 9.12.4. Binary distributions, source distributions, and documentation are available at downloads.haskell.org and via GHCup.
GHC 9.12.4 is a bug-fix release fixing many issues of a variety of severities and scopes, including:
error exceptions are now
evaluated at throw timeNamedDefaults now correctly requires the class to be standard or have an
in-scope default declaration, and handles poly-kinded classes (#25775, #25778, #25882)A full accounting of these fixes can be found in the
release notes. As always, GHC’s release status, including planned future releases, can be found on the GHC Wiki status.
This release candidate will have a two-week testing period. If all goes well the final release will be available the week of 26 March 2026.
GHC development is sponsored by:
We would like to thank these sponsors and other anonymous contributors whose on-going financial and in-kind support has facilitated GHC maintenance and release management over the years. Finally, this release would not have been possible without the hundreds of open-source contributors whose work comprise this release.
As always, do give this release a try and open a ticket if you see anything amiss.
Pointer-rich data layouts lead to suboptimal performance on modern hardware. For an excellent introduction to this, see the article The Road to Valhalla. While it is specifically about Java, many parts of the article also apply to other languages. To summarize some of the key points of the article:
Consider a vector of records (or tuples, structures, product types - I’ll stay with “record” in this article). A pointer-rich layout has each record allocated separately in the heap, with a vector containing pointers to the records. For example, given a “Point” record of two numbers:
The flat and dense layout has the records directly in the array:
(Note that there is another flat layout, namely, using one vector per field of the record. This is better suited to instruction-level parallelism or specialized hardware (e.g., GPUs), especially when the record fields have different sizes. But it is less suited for general-purpose computing, as reading a single vector element requires one memory access per field, whereas the “vector of records” layout above requires only one access per record. Such a layout can be easily implemented in any language that has arrays of native types, whether in the language itself or in a library (e.g., OCaml’s Owl library). Thus, in this article, I will only consider the “array of records” layout above.)
Things should be much easier in functional languages than in Java: we have purity, referential transparency, and everything is a value. So it should be simple enough to store these values in memory in their native representation. But there are reasons that that is often not the case in practice:
Many implementations can not even lay out native types flat in records, so a Point record of IEEE 754 double-precision numbers may actually look like this in memory:
So, given a record type, which functional languages allow a collection of values of that type to have a flat, linear memory layout? The number of programming languages that claim to be “functional” is huge, so the ones listed here are just a selection based on my preferences - mainly languages that allow that layout, and some I have some experience with and can speculate on how easy or hard it would be to add that as a library or extension.
Since the Point record can be misleading in its simplicity when it comes to the question of whether the functionality could be implemented as a library, I’ll point out that there are records where the layout is a bit more interesting:
Yes: Clean has unboxed arrays of records in the base language.
Caveat: it does not have integer types of specific sizes and only one floating-point type, making it harder to reduce memory usage by using the smallest type just large enough to support the required value range. It seems possible to implement such types in a library (the mTask system does that).
No. Futhark does not intend to be a general-purpose language, so this is not surprising.
I mention it here because it does have arrays of records, but, since it targets GPUs and related hardware, it uses the “record of arrays” layout mentioned above.
Yes. Not in the base language, but there is library support via Data.Vector.Unboxed. Types that implement the Unbox type class can be used in these vectors. Many basic types and tuples have an Unbox instance. However, when you care about efficiency, you probably do not want to use tuples but rather a data type with strict fields, i.e., not:
but:
Writing an Unbox instance for such a type is not trivial. The vector-th-unbox library makes it easier, but requires Template Haskell. Unboxed vectors are implemented by marshalling the values to byte arrays, so records with pointer fields are not supported.
Yes, even records with pointer fields. Records have structural equality, and you can use structs or the [<Struct>] attribute to get a flat layout.
And that’s all I could find. Unless I follow Wikipedia's list of functional programming languages, which contains languages such as C++, C#, Rust, or Swift, that allow the flat layout, but don’t really fit my idea of a functional language. But SML, OCaml, Erlang (Elixir, Gleam), Scala? Not that I could see (but please correct me if I’m wrong).
Since there is a library implementation for Haskell, maybe that’s a possibility for other languages?
You should be able to implement flat layouts in any language that supports byte vectors. More interesting is how well such a library fits into the language, and whether a user of the library has to write code or annotations for user-defined record types, or whether the library can handle part or all of that automagically.
I’ll only mention my beloved Lisp/Scheme here. Lisp’s uniform syntax and macro system are a bonus here, but the lack of static typing makes things harder.
In Scheme, R6RS (and R7RS with the help of some SRFIs) has byte-vectors and marshalling to/from them in the standard library. But Scheme does not have type annotations, so you either need to offer a macro to define records with typed fields or to define how to marshal the fields of a regular (sealed) record. Since you can shadow standard procedures in a library, you can write code that looks like regular Scheme code, but, perhaps surprisingly, loses identity when storing/retrieving values from records:
(let ((vec (make-typed-vector 'point 1000))
(pt (make-point x y)))
(vector-set! vec 0 pt)
(eq? (vector-ref vec 0) pt))
⇒ #f(But then, you probably shouldn’t be using eq? when doing functional programming in Scheme).
The same approach is possible in Common Lisp. In contrast to Scheme, it does have optional type annotations, and, together with a helper library for accessing the innards of floats and either the meta-object protocol to get type information or (probably better) a macro to define typed records, an implementation should be reasonably straightforward. Making it play nice with inheritance and the dynamic nature of Common Lisp (e.g., adding slots to classes or even changing an object's class at runtime) would be a much harder undertaking.
Of the functional languages I looked at, only F# fully supports flat and dense memory layouts. Among the pure languages, Haskell and Clean come close.
The question is how important this really is. There’s a good argument to be made for turning to more specialized languages like Futhark if you mainly care about performance. On the other hand, having a uniform codebase in one language also has advantages.
Then, the performance story has changed, too. While the points Project Valhalla raises remain true in principle, processor designers are aware of this as well. They are doing their best to hide memory latency with techniques such as out-of-order execution or humongous caches. Thus, on a modern CPU, the effects of a pointer-rich layout are often only observable with large working set sizes.
Still, given the plethora of imperative language that can get you to Valhalla, support for this in the functional landscape seems lacking. In the future, I hope to see more languages or libraries that will make this possible.
I’ve been watching AI development for a long time. I found LessWrong around 2012-2013, and managed to get myself worked up about the oncoming singularity. I managed to chill out about it, but interest and excitement for AI remained. The initial Deep Dream image generation, Alpha Go, etc, were all so exciting. And then GPT-2 came out.
Over the last five years, people have been making wild claims about the utility of present AI. Not “the AI that you’ll have soon,” but the current generation stuff. And the results, frankly, had been garbage. A sea of garbage coating the internet. I’d try using the tools, and when checking them against my own expertise or knowledge, they always fell short.
I heard the noise on Twitter after Opus 4.5 was released in November of 2025.
Seemed like a step change- people were much more impressed with it than prior versions.
In December, I decided to give it a try.
Opus 4.5, with significant guidance, properly diagnosed and fixed some Template Haskell code generation issues.
It knew how to -ddump-splices, it knew how to read those splices and diagnose the issue.
Given a small, highly mechanical problem, plenty of examples, and a ton of tests, it took about 6 hours to do what I felt would have taken me 3 or 4 hours.
This is pretty incredible, because my productivity has always been limited by two things:
Now, with Opus 4.5, I can set a robot going and do something else with my effort. While Claude Code was spinning on the Template Haskell code, I was doing another project in a different repository. Sure, Claude took 6 hours instead of my 3, but I was able to fill those 6 hours with effort and attention placed elsewhere - not a full 6, as Claude required supervision and input, but call it 5. This is a positive investment, and my personal “break even” moment.
In mid February, I got access to an API token and unlimited usage. I’ve been trying to figure out how to leverage this tool to improve my productivity, and the results have been pretty strongly positive.
The brief tl;dr:
It’s the same shit that makes humans good at software development
This was true with Opus 4.5 and is much more true with Opus 4.6. Prior versions of LLM coding agents produced utter garbage with Haskell, most likely due to the relatively low quantity of examples. It seems like the AI labs have figured out how to do higher quality training with less data, and the relatively high average quality of Haskell code helps the LLMs generate relatively high quality Haskell.
Haskell’s type safety, purity, and library design opportunities make it a fantastic choice for LLM generated code. The human developer can easily specify a solution and let Claude fill in a surprising amount of the boring details.
Haskell’s terse nature benefits LLMs - you can simply fit more tokens into the context window when the tokens are more semantically dense.
Funny enough, all of Haskell’s benefits “for LLMs” are also benefits of Haskell for humans. I do earnestly believe that if all devs knew Haskell, we would consider switching to other languages only very rarely. And Claude knows Haskell.
Claude Code works really well with tightly scoped issues, lots of tests and examples, and good safety guardrails.
I asked it to make cabal faster, and taught it how to run cabal with debug logs, timings, and then to build a profiled version of it.
Then it looped for a bit, collected timing information on our codebase, and figured out the critical path and hot spot - the solver.
Then it made several fixes to optimize the solver.
These changes resulted in a 30% improvement in solver times, which shaved 2 seconds off every cabal repl invocation- a pretty nice benefit, since that happens virtually anytime you want to do anything in our codebase.
But this only worked because the cabal library had timing logs, and I gave it a quick feedback loop and target.
I’ve had Claude Code totally fall over when trying to do bigger or more undirected work.
Fortunately, Claude can do this pretty well. I’ve had Claude do some exploratory research (generally pretty highly supervised), then generate some plans for improvement (then edited and clarified), and it can then do a good job of writing up a ticket- certainly better than almost all human written tickets I’ve seen.
LLMs can do anything. But they are expensive, slow, and non-deterministic (and often incorrect). So get the LLM to help with replacing themselves - build a tool or skill to do the thing faster and deterministically.
My Claude sessions generally progress from “highly supervised, exploratory work” to “mostly unsupervised, automated work.” Early sessions in a project often involve having Claude build tools - CLI scripts, libraries, interfaces - that it can use in later work to make the job easier. A surprisingly effective prompt here is “What tools would help you do this job better next time?” At the end of a session, I’ll also have Claude review and update its skill documentation with everything I told it to do differently.
So each work session with Claude produces:
This process ends up reducing the highly non-deterministic LLM tool with a much more deterministic tool.
You can ask Claude to review code, and that works OK. But Claude works much better if you ask it to assume someone else’s perspective. I’ve asked it to mimic myself and it did Alright. I asked it to mimic Edward Kmett, Alexis King, and Michael Snoyman, and it did Alright - it noticed different things with each perspective and suggested improvements in line with those perspectives.
I’ve generally found that the initial output is of poor to middling quality. But you can get decently far with “now make it more legible/faster/more correct” or “apply ‘Parse, Don’t Validate’ here” etc. After several rounds of refactoring, it makes stuff that I’m reasonably happy with putting my name on.
Claude isn’t a replacement for human engineering (“yet” i guess). It lacks qualities like taste, judgement, and vision, that are generally required in subjective work like software and product design. So when I let Claude run totally loose on something, it produces, but it produces poor quality code and poorly thought out features.
I haven’t had great luck with getting Claude to iterate on this itself. When given the very large picture, it sort of flounders. It can do some analysis and subdivision, but the divisions are often somewhat unnatural and don’t feel right to me.
If the above complaint is about Claude’s lack of virtue, let me also complain about Claude’s lack of vice. Claude is infinitely patient and willing to work very hard. However, “infinitely patient” means that Claude has no problem at all waiting an hour for a build to finish. You have to teach it to use faster tools and feedback loops.
Likewise, “hardworking” is a virtue when you’re paying a human by the month and trusting in their laziness to be efficient, but when you’re paying per unit of thought, “more work” means “more cost” and often not “more output.” You have to tell Claude to stop doing stuff or to do stuff more efficiently.
Fortunately, Claude is relatively teachable - but Claude very often will start a skill and then do a lot of “research and understanding” before running the one-shot script to generate the compile-errors to track down and fix.
Humans are impatient and lazy, so we build fast and efficient systems. Without pain to guide us, we make little progress in reducing that pain.
I’ve been using AI to write 95% of my code for the last month. And yet, I still feel like I’m more on the skeptic side of things. AI is clearly a useful tool - my own productivity has doubled or more while maintaining my personal quality bar. But it’s not a do-it-all miracle - yet?
AI-first companies are experiencing massive reliability issues. Vibe coding projects start, enjoy some success, and then go down in flames.
Humans are clearly still necessary at key points in the software lifecycle. The bottlenecks have shifted, though, and the easiest parts of my job have been mostly automated. What’s coming next?
I’m excited to wait and find out.
A couple of days ago I recounted a common complaint:
I keep seeing programmers say how angry it makes them that people are willing to write detailed
CLAUDE.mdandPROJECT.mdfiles for Claude to use, but they weren't willing to write them for their coworkers.
For larger projects, I've taken to having Claude maintain a handoff
document that I can have the next Claude read, saying what we planned
to do, what has been done, and other pertinent information. Then when
I shut down one Claude I can have the next one read the file to get up
to speed. Then I have the Claude update it for Claude
.
After seeing the common complaint enough times I had a happy
inspiration. I'd been throwing away Claude's handoff documents at the
end of each project. Why do that? It's no trouble to copy the file
into the repository and commit it. Someone in the future, wondering
what was going on, might luckily find the right document with git
grep and learn something useful.
I'm a little slow so it took me until this week to think of a better version of this: at the end of the project I now ask Claude to write up from scratch a detailed but high-level explanation of what problem we were solving and what changes we made, and I commit that. Not just running notes, but a structured overview of the whole thing.
I review these overviews carefully and make edits as necessary before I check them in. It's my signature on the commit, and my bank account receiving the paycheck, so nothing goes into the repository that I haven't read carefully and understood, same as if Claude were a human programmer under my supervision.
But Claude's explanations haven't required much editing. Claude's most recent project summary was around as good as what I could have written myself, maybe a little worse and maybe a little better. But it took ten seconds to write instead of an hour, and it didn't take anything like an hour to review.
The serious thing I had to fix the last time around was that Claude had used a previous, related report as a model, and the previous report had had a paragraph I had added at the end that said:
# Approved-by
Claude abstracted these notes from our discussions of the issue. Mark Dominus has read, reviewed, edited, and approved these notes.
Claude's new document had an identical section at the end. Oops!
Fortunately, by the time I saw it, it was true, so I didn't have to
delete it. I had Claude add a sentence to CLAUDE.md to tell it not
to do this again.
My advice for the day:
If you have Claude write down notes, check them into the repo when you're done. It probably can't hurt and it might help.
Have Claude write a project summary, and then check it into the repo.
Maybe this is obvious? But it wasn't obvious to me. I'm still getting used to this new world.
In this episode, we focus on a particular part of Haskell: teaching it. To help us, we are joined by Jamie Willis who is a Teaching Fellow at Imperial College London. The episode explores the benefits of live coding, and why Haskell is the best language for teaching programming.
A number of years ago I wondered how many movies I had seen. The only way I could think of finding out was just to make a list. This I did as best I could. (It turned out to be around 700.)
I found, though, that I could not include all the James Bond movies I had seen, because I couldn't tell them apart from the descriptions. I'd read a plot summary for a James Bond movie, and ask myself “Did I see that? I don't know, it sounds like every other James Bond movie.”
Today I discovered that John Waters movies are like that also. I was trying to remember if I had seen A Dirty Shame:
The people of Harford Road are firmly divided into two camps: the neuters, the puritanical residents who despise anything even remotely carnal; and the perverts, a group of sex addicts whose unique fetishes have all been brought to the fore by accidental concussions. Repressed Sylvia Stickles finds herself firmly entrenched in the former camp.
You'd think that would be something I would remember decisively, or not. But I'm really not sure. All I can do is shrug and say “I don't know, it sounds like a John Waters movie I have seen, but maybe it wasn't that one.”
Looking into it further I discovered that I also wasn't sure if I had seen Multiple Maniacs. In it, Divine's character is raped by a giant lobster. On the one hand, that seems like the sort of thing I would remember. And I think maybe I do? But again I'm not sure I'm not just imagining what it would be like!
Our company is going to a convention later this month, and they will have a booth with big TV screens showing statistics that update in real time. My job is to write the backend server that delivers the statistics.
I read over the documents that the product people had written up about what was wanted, asked questions, got answers, and then turned the original two-line ticket into a three-page ticket that said what should be done and how. I intended to do the ticket myself, but it's good practice to write all this stuff down, for many reasons:
Writing things down forces me to think them through carefully and realize what doesn't make sense or what I still don't understand.
I forget things easily and this will keep the plan where I can find it.
I might get sick, and if someone else has to pick up the project this might help them understand what I was doing.
If my boss gets worried that all I do is post on 4chan all day, this is tangible work product that proves I did something else that might have enhanced shareholder value.
If I'm tempted to spend the day posting on 4chan, and then to later claim I spent the time planning the project, I might fool my boss. But without that tangible work product, I won't be able to fool myself, and that's more important.
Conversely if I later think back and ask “What was I doing the week of March 2?” I might be tempted to imagine that all I did was post on 4chan. But the three pages of ticket description will prove to me that I am not just a lazy slacker. This is a real problem for me.
In principle, a future person going back to extend the work might find this helpful documentation of what was done and why. Does this ever really happen? I don't know, but it might.
I like writing because writing is fun.
A few days after I wrote the ticket, something unexpected happened. It transpired that person who was to build the front-end consumer of my statistics would not be a professional programmer. It would be the company's Head of Product, a very smart woman named Amanda. The actual code would be written by Claude, under her supervision.
I have never done anything like this before, and I would not have wanted to try it on a short deadline, but there is some slack in the schedule and it seemed a worthwhile and exciting experiment.
Amanda shared some screencaps of her chats with Claude about the project, and I suggested:
When you get a chance, please ask Claude to write out a Markdown file memorializing all this. Tell it that you're going to give it to the backend programmer for discussion, so more detail is better. When it's ready, send it over.
Claude immediately produced a nine-page, 14-part memo and a half-page overview. I spent a couple of hours reviewing it and marking it up.
It became immediately clear that Claude and I had very similar ideas about how the project should go and how the front and back ends would hook up. So similar that I asked Angela:
It looks like maybe you started it off by feeding it my ticket description. Is that right?
She said yes, she had. She had also fed it the original product documents I had read.
I was delighted. I had had many reasons for writing detailed ticket descriptions before, but the most plausible ones were aimed back at myself.
The external consumers of the documentation all seemed somewhat unlikely. The person who would extend the project in the future probably didn't exist, and if they did they probably wouldn't have thought to look at my notes. Same for the hypothetical person who would take over when I got sick. My boss probably isn't checking up on me by looking at my ticketing history. Still, I like to document these things for my own benefit, and also just in case.
But now, because I had written the project plan, it was available for consumption when an unexpected consumer turned up! Claude and I were able to rapidly converge on the design of the system, because Amanda had found my notes and cleverly handed them to Claude. Suddenly one of those unlikely-seeming external reasons materialized!
On Mastodon I keep seeing programmers say how angry it makes
them that people are willing to write detailed CLAUDE.md and
PROJECT.md files for Claude to use, but they weren't willing to
write them for their coworkers. (They complain about this as if this
is somehow the fault of the AI, rather than of the people who failed
in the past to write documentation for their coworkers.)
The obvious answer to the question of why people are willing to write documentation for Claude but not for their coworkers is that the author can count on Claude to read the documentation, whereas it's a rare coworker who will look at it attentively.
Rik Signes points out there's a less obvious but more likely answer: your coworkers will remember things if you just tell them, but Claude forgets everything every time. If you want Claude to remember something, you have to write it down. So people using Claude do write things down, because otherwise they have to say them over and over.
And there's a happy converse to the complaint that most programmers don't bother to write documentation. It means that people like me, professionals who have always written meticulous documentation, are now reaping new benefits from that always valuable practice.
Not everything is going to get worse. Some things will get better.
A corollary: You don't have to write the rocumentation yourself. You can have Claude write a detailed summary based on your ongoing chats about the work, and then you can edit it and check it in.
If you're good at editing, anyway. I wonder if part of the reason Claude is working so well for me is that I'm really good at editing and at code review?
Bo Diddley's cover of "Sixteen Tons" sounds very much like one of my favorites, "Can't Judge A Book By Its Cover". It's interesting to compare.
Thinking on that it suddenly occured to me that his name might have been a play on “diddley bow”, which is a sort of homemade one-stringed zither. The player uses a bottle as a bridge for the string, and changes the pitch by sliding the bottle up and down. When you hear about blues artists whose first guitars were homemade, this is often what was meant: it wasn't a six-string guitar, it was a diddley bow.
But it's not clear that Bo Diddley did play his name on the diddley bow. "Diddly" also means something insignificant or of little value, and might have been a disparaging nickname he received in his youth. (It also appears in the phrase "diddly squat"). Maybe that's also the source of the name of the diddley bow.
This post is about a simple algebraic structure that I have found
useful for algorithms that involve searching or sorting based on some
ordered weight. I used it a bit in a pair of papers on graph search
(2021; 2025), and more recently I used it to
implement a version of the Phases type
(Easterly
2019) that supported arbitrary keys, inspired by some work by
Blöndal (2025a; 2025b)
and Visscher
(2025).
The algebraic structure in question is a monus, which is a kind of monoid that supports a partial subtraction operation (that subtraction operation, denoted by the symbol ∸, is itself often called a “monus�). However, before giving the full definition of the structure, let me first try to motivate its use. The context here is heap-based algorithms. For the purposes of this post, a heap is a tree that obeys the “heap property�; i.e. every node in the tree has some “weight� attached to it, and every parent node has a weight less than or equal to the weight of each of its children. So, for a tree like the following:
The heap property is satisfied when , , , and .
Usually, we also want our heap structure to have an operation like
popMin :: Heap k v -> Maybe (v, Heap k v)
that returns the least-weight value in the heap paired with the rest of
the heap. If this operation is efficient, we can use the heap to
efficiently implement sorting algorithms, graph search, etc. In fact,
let me give the whole basic interface for a heap here:
popMin :: Heap k v -> Maybe (v, Heap k v)
insert :: k -> v -> Heap k v -> Heap k v
empty :: Heap k vUsing these functions it’s not hard to see how we can implement a sorting algorithm:
The monus becomes relevant when the weight involved is some kind of monoid. This is quite a common situation: if we were using the heap for graph search (least-cost paths or something), we would expect the weight to correspond to path costs, and we would expect that we can add the costs of paths in a kind of monoidal way. Furthermore, we would probably expect the monoidal operations to relate to the order in some coherent way. A monus (Amer 1984) is an ordered monoid where the order itself can be defined in terms of the monoidal operations1:
I read this definition as saying “ is less than iff there is some that fits between and �. In other words, the gap between and has to exist, and it is equal to .
Notice that this order definition won’t work for groups like . For a group, we can always find some that will fit the existential (specifically, ). Monuses, then, tend to be positive monoids: in fact, many monuses are the positive cones of some group ( is the positive cone of ).
We can derive a lot of useful properties from this basic structure. For example, if the order above is total, then we can derive the binary subtraction operator mentioned above:
If we require the underlying monoid to be commutative, and we further require the derived order to be total and antisymmetric, we get the particular flavour of monus I worked with in a pair of papers on graph search (2021; 2025). In this post I will actually be working with a weakened form of the algebra that I will define shortly.
Getting back to our heap from above, with this new order defined, we can see that the heap property actually tells us something about the makeup of the weights in the tree. Instead of every child just having a weight equal to some arbitrary quantity, the heap property tells us that each child weight has to be made up of the combination of its parent’s weight and some difference.
This observation gives us an opportunity for a different representation: instead of storing the full weight at each node, we could instead just store the difference.
Just in terms of data structure design, I prefer this version: if we wanted to write down a type of heaps using the previous design, we would first define the type of trees, and then separately write a predicate corresponding to the heap property. With this design, it is impossible to write down a tree that doesn’t satisfy the heap property.
More practically, though, using this algebraic structure when working with heaps enables some optimisations that might be difficult to implement otherwise. The strength of this representation is that it allows for efficient relative and global computation: now, if we wanted to add some quantity to every weight in the tree, we can do it just by adding the weight to the root node.
To see some examples of how to use this pattern, let’s first write a class for Haskell monuses:
You’ll notice that we’re requiring semigroup here, not monoid. That’s because one of the nice uses of this pattern actually works with a weakening of the usual monus algebra; this weakening only requires semigroup, and the following two laws.
A straightforward monus instance is the following:
Next, let’s look at a simple heap implementation. I will always go for pairing heaps (Fredman et al. 1986) in Haskell; they are extremely simple to implement, and (as long as you don’t have significant persistence requirements) their performance seems to be the best of the available pointer-based heaps (Larkin, Sen, and Tarjan 2013). Here is the type definition:
A Root is a
non-empty pairing heap; the Heap type
represents possibly-empty heaps. The key function to implement is the
merging of two heaps; we can accomplish this as an implementation of the
semigroup <>.
instance Monus k => Semigroup (Root k v) where
Root xk xv xs <> Root yk yv ys
| xk <= yk = Root xk xv (Root (yk ∸ xk) yv ys : xs)
| otherwise = Root yk yv (Root (xk ∸ yk) xv xs : ys)The only difference between this and a normal pairing heap merge is
the use of ∸ in the key of the
child node (yk ∸ xk and xk ∸ yk). This difference ensures that
each child only holds the difference of the weight between itself and
its parent.
It’s worth working out why the weakened monus laws above are all we need in order to maintain the heap property on this structure.
The rest of the methods are implemented the same as their
implementations on a normal pairing heap. First, we have the pairing
merge of a list of heaps, here given as an implementation of the
semigroup method sconcat:
sconcat (x1 :| []) = x1
sconcat (x1 :| [x2]) = x1 <> x2
sconcat (x1 :| x2 : x3 : xs) = (x1 <> x2) <> sconcat (x3 :| xs)
merges :: Monus k => [Root k v] -> Heap k v
merges = fmap sconcat . nonEmptyThe pattern of this two-level merge is what gives the pairing heap its excellent performance.
The Heap type
derives its monoid instance from the monoid instance on Maybe (instance Semigroup a => Monoid (Maybe a)),
so we can implement insert like
so:
And popMin is also relatively
simple:
delay :: Semigroup k => k -> Heap k v -> Heap k v
delay by = fmap (\(Root k v xs) -> Root (by <> k) v xs)
popMin :: Monus k => Heap k v -> Maybe (v,Heap k v)
popMin = fmap (\(Root k v xs) -> (v, k `delay` merges xs))Notice that we delay the rest
of the heap, because all of its entries need to be offset by the weight
of the previous root node. Thankfully, because we’re only storing the
differences, we can “modify� every weight by just increasing the weight
of the root, making this an
operation.
Finally, we can implement heap sort like so:
sortOn :: Monus k => (a -> k) -> [a] -> [a]
sortOn k = unfoldr popMin . foldl' (\xs x -> insert (k x) x xs) NothingAnd it does indeed work:
Here is a trace of the output:
Input Heap:
list:
[3,4,2,5,1]
[4,2,5,1] 3
[2,5,1] 3─1
[5,1] 2─1─1
[1] ┌3
2┤
└1─1
[] ┌3
1─1┤
└1─1
Output Heap:
list:
[] ┌3
1─1┤
└1─1
[1] ┌3
2┤
└1─1
[1,2] ┌2
3┤
â””1
[1,2,3] 4─1
[1,2,3,4] 5
[1,2,3,4,5]While the heap implementation presented here is pretty efficient,
note that we could significantly improve its performance with a few
optimisations: first, we could unpack all of the constructors, using a
custom list definition in Root instead
of Haskell’s built-in lists; second, in foldl' we could avoid the Maybe wrapper
by building a non-empty heap. There are probably more small
optimisations available as well.
A problem with the definition of sortOn above is that it requires a
Monus
instance on the keys, but it only really needs Ord. It seems
that by switching to the Monus-powered
heap we have lost some generality.
Luckily, there are two monuses we can use to solve this problem:
instance Ord a => Monus (Max a) where
x ∸ y = x
instance Ord a => Monus (Last a) where
x ∸ y = xThe Max semigroup
uses the max operation,
and the Last semigroup
returns its second operand.
instance Ord a => Semigroup (Max a) where
Max x <> Max y = Max (max x y)
instance Semigroup (Last a) where
x <> y = yWhile the Monus
instances here might seem degenerate, they do actually satisfy the Monus laws as
given above.
Max and
Last
Monus laws
Max:
x <= y ==> x <> (y ∸ x) = y
Max x <= Max y ==> Max x <> (Max y ∸ Max x) = Max y
Max x <= Max y ==> Max x <> Max y = Max y
Max x <= Max y ==> Max (max x y) = Max y
x <= y ==> max x y = y
x <= y ==> z <> x <= z <> y
Max x <= Max y ==> Max z <> Max x <= Max z <> Max y
Max x <= Max y ==> Max (max z x) <= Max (max z y)
x <= y ==> max z x <= max z yLast:
Either Max or Last will
work; semantically, there’s no real difference. Last avoids
some comparisons, so we can use that:
The Phases
applicative (Easterly
2019) is an Applicative
transformer that allows reordering of Applicative
effects in an easy-to-use, high-level way. The interface looks like
this:
phase :: Natural -> f a -> Phases f a
runPhases :: Applicative f => Phases f a -> f a
instance Applicative f => Applicative (Phases f)And we can use it like this:
phased :: IO String
phased = runPhases $ sequenceA
[ phase 3 $ emit 'a'
, phase 2 $ emit 'b'
, phase 1 $ emit 'c'
, phase 2 $ emit 'd'
, phase 3 $ emit 'e' ]
where emit c = putChar c >> return c
>>> phased
cbdae
"abcde"The above computation performs the effects in the order
dictated by their phases (this is why the characters are printed out in
the order cbdae), but the pure
value (the returned string) has its order unaffected.
I have written about this type before, and in a handful of
papers (2021; Gibbons et
al. 2022; Gibbons et al. 2023), but more recently
Blöndal (2025a) started looking into trying to
use the Phases pattern
with arbitrary ordered keys (Visscher 2025;
Blöndal
2025b). There are a lot of different directions you can go
from the Phases type;
what interested me most immediately was the idea of implementing the
type efficiently using standard data-structure representations. If our
core goal here is to order some values according to a key, then that is
clearly a problem that a heap should solve: enter the free applicative
pairing heap.
Here is the type’s definition:
data Heap k f a where
Pure :: a -> Heap k f a
Root :: !k -> (x -> y -> a) -> f x -> Heaps k f y -> Heap k f a
data Heaps k f a where
Nil :: Heaps k f ()
App :: !k -> f x -> Heaps k f y -> Heaps k f z -> Heaps k f (x,y,z)We have had to change a few aspects of the original pairing heap, but
the overall structure remains. The entries in this heap are now
effectful computations: the fs.
The data structure also contains some scaffolding to reconstruct the
pure values “inside� each effect when we actually run the heap.
The root-level structure is the Heap: this can
either be Pure
(corresponding to an empty heap: notice that, though this constructor
has some contents (the a), it is
still regarded as “empty� because it contains no effects (f)); or a Root, which is
a singleton value, paired with the list of sub-heaps represented by the
Heaps
type. We’re using the usual Yoneda-ish trick here to allow the top-level
data type to be parametric and a Functor, by
storing the function x -> y -> a.
The Heaps type
then plays the role of [Root k v] in
the previous pairing heap implementation; here, we have inlined all of
the constructors so that we can get all of the types to line up.
Remember, this is a heap of effects, not of pure values: the
pure values need to be able to be reconstructed to one single top-level
a when we run the heap at the
end.
Merging two heaps happens in the Applicative
instance itself:
instance Functor (Heap k f) where
fmap f (Pure x) = Pure (f x)
fmap f (Root k c x xs) = Root k (\a b -> f (c a b)) x xs
instance Monus k => Applicative (Heap k f) where
pure = Pure
Pure f <*> xs = fmap f xs
xs <*> Pure f = fmap ($ f) xs
Root xk xc xs xss <*> Root yk yc ys yss
| xk <= yk = Root xk (\a (b,c,d) -> xc a d (yc b c)) xs (App (yk ∸ xk) ys yss xss)
| otherwise = Root yk (\a (b,c,d) -> xc b c (yc a d)) ys (App (xk ∸ yk) xs xss yss)To actually run the heap we will use the following two functions:
merges :: (Monus k, Applicative f) => Heaps k f a -> Heap k f a
merges Nil = Pure ()
merges (App k1 e1 t1 Nil) = Root k1 (,,()) e1 t1
merges (App k1 e1 t1 (App k2 e2 t2 xs)) =
(Root k1 (\a b cd es -> (a,b, cd es)) e1 t1 <*> Root k2 (,,) e2 t2) <*> merges xs
runHeap :: (Monus k, Applicative f) => Heap k f a -> f a
runHeap (Pure x) = pure x
runHeap (Root _ c x xs) = liftA2 c x (runHeap (merges xs))And we can lift a computation into Phases like
so:
There’s a problem. A heap sort based on a pairing heap isn’t
stable. That means that the order of effects here can vary for
two effects in the same phase. If we look back to the example with the
strings we saw above, that means that outputs like cdbea would be possible (in actual
fact, we don’t get any reordering in this particular example, but that’s
just an accident of the way the applicative operators are associated
under the hood).
This is problematic because we would expect effects in the same phase to behave as if they were normal applicative effects, sequenced according to their syntactic order. It also means that the applicative transformer breaks the applicative laws, because effects might be reordered according to the association of the applicative operators, which should lawfully be associative.
To make the sort stable, we could layer the heap effect with some state effect that would tag each effect with its order. However, that would hurt efficiency and composability: it would force us to linearise the whole heap sort procedure, where currently different branches of the tree can compute completely independently of each other. The solution comes in the form of another monus: the key monus.
A Key k is some
ordered key k coupled with an
Int that
represents the offset between the original position and the current
position of the key. In this way, when two keys compare as equal, we can
cascade on to compare their original positions, thereby maintaining
their original order when there is ambiguity caused by a key collision.
However, in contrast to the approach of walking over the data once and
tagging it all with positions, this approach keeps the location
information completely local: we never need to know that some key is in
the
th
position in the original sequence, only that it has moved
steps from its original position.
The instances are as follows:
instance Semigroup (Key k) where
(xk :* xi) <> (yk :* yi) = yk :* (xi + yi)
instance Ord k => Monus (Key k) where
(xk :* xi) ∸ (yk :* yi) = xk :* (xi - yi)This instance is basically a combination of the Last semigroup
and the
group. We could make a slightly more generalised version of Key that is
the combination of any monus and
,
but since I’m only going to be using this type for simple sorting-like
algorithms I will leave that generalisation for another time.
The stable heap type is as follows:
We need to track the size of the heap so that we can supply the right-hand operand with their offsets. Because we’re storing differences, we can add an offset to every entry in a heap in time by simply adding to the root:
delayKey :: Int -> Heap (Key k) f a -> Heap (Key k) f a
delayKey _ hp@(Pure _) = hp
delayKey n (Root (k :* m) c x xs) = Root (k :* (n + m)) c x xsFinally, using this we can implement the Applicative
instance and the rest of the interface:
instance Ord k => Applicative (Stable k f) where
pure = Stable 0 . pure
Stable n xs <*> Stable m ys = Stable (n+m) (xs <*> delayKey n ys)
runStable :: (Applicative f, Ord k) => Stable k f a -> f a
runStable = runHeap . heap
stable :: Ord k => k -> f a -> Stable k f a
stable k fa = Stable 1 (phase (k :* 0) fa)This is a pure, optimally efficient implementation of Phases ordered
by an arbitrary total-ordered key.
In (2021), I developed a monadic heap based on the free monad transformer.
This type is equivalent to the free
monad transformer over the list monad and (,) k functor (i.e. the writer
monad).
In the paper (2021) we extended the type to become a
full monad transformer, replacing lists with ListT. This
let us order the effects according to the weight k; however, for this example we only
need the simplified type, which lets us order the values according to
k.
This Search type
follows the structure of a pairing heap (although not as closely as the
version above). However, this type is interesting because
semantically it needs the weights to be stored as differences,
rather than absolute weights. As a free monad transformer, the Search type
layers effects on top of each other; we can later interpret those layers
by collapsing them together using the monadic join. In the case of Search, those
layers are drawn from the list monad and the (,) k functor (writer monad). That
means that if we have some heap representing the tree from above:
Search [ Right (a, Search [ Right (b, Search [ Right (d, Search [Left x])
, Right (e, Search [Left y])])
, Right (c, Search [Left z])])]When we collapse this computation down to the leaves, the weights we will get are the following:
So, if we want the weights to line up properly, we need to store the differences.
mergeS :: Monus k => [(k, Search k a)] -> Maybe (k, Search k a)
mergeS [] = Nothing
mergeS (x:xs) = Just (mergeS' x xs)
where
mergeS' x1 [] = x1
mergeS' x1 [x2] = x1 <+> x2
mergeS' x1 (x2:x3:xs) = (x1 <+> x2) <+> mergeS' x3 xs
(xw, Search xs) <+> (yw, Search ys)
| xw <= yw = (xw, Search (Right (yw ∸ xw, Search ys) : xs))
| otherwise = (yw, Search (Right (xw ∸ yw, Search xs) : ys))
popMins :: Monus k => Search k a -> ([a], Maybe (k, Search k a))
popMins = fmap mergeS . partitionEithers . runSearchThe technique of “don’t store the absolute value, store the
difference� seems to be generally quite useful; I think that monuses are
a handy algebra to keep in mind whenever that technique looks like it
might be needed. The Key monus
above is closely related to the factorial numbers, and the trick I used
in this post.
(Updated February 2026 for PenroseKiteDart version 1.6.1)
PenroseKiteDart is a Haskell package with tools to experiment with finite tilings of Penrose’s Kites and Darts. It uses the Haskell Diagrams package for drawing tilings. As well as providing drawing tools, this package introduces tile graphs (Tgraphs) for describing finite tilings. (I would like to thank Stephen Huggett for suggesting planar graphs as a way to reperesent the tilings).
This document summarises the design and use of the PenroseKiteDart package.
PenroseKiteDart package is now available on Hackage.
The source files are available on GitHub at https://github.com/chrisreade/PenroseKiteDart.
There is a small art gallery of examples created with PenroseKiteDart here.
Index
In figure 1 we show a dart and a kite. All angles are multiples of 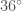


What is interesting about these tiles is:
It is possible to tile the entire plane with kites and darts in an aperiodic way.
Such a tiling is non-periodic and does not contain arbitrarily large periodic regions or patches.
The possibility of aperiodic tilings with kites and darts was discovered by Sir Roger Penrose in 1974. There are other shapes with this property, including a chiral aperiodic monotile discovered in 2023 by Smith, Myers, Kaplan, Goodman-Strauss. (See the Penrose Tiling Wikipedia page for the history of aperiodic tilings)
This package is entirely concerned with Penrose’s kite and dart tilings also known as P2 tilings.
In figure 2 we add a temporary green line marking purely to illustrate a rule for making legal tilings. The purpose of the rule is to exclude the possibility of periodic tilings.
If all tiles are marked as shown, then whenever tiles come together at a point, they must all be marked or must all be unmarked at that meeting point. So, for example, each long edge of a kite can be placed legally on only one of the two long edges of a dart. The kite wing vertex (which is marked) has to go next to the dart tip vertex (which is marked) and cannot go next to the dart wing vertex (which is unmarked) for a legal tiling.

Unfortunately, having a finite legal tiling is not enough to guarantee you can continue the tiling without getting stuck. Finite legal tilings which can be continued to cover the entire plane are called correct and the others (which are doomed to get stuck) are called incorrect. This means that decomposition and forcing (described later) become important tools for constructing correct finite tilings.
You will need the Haskell Diagrams package (See Haskell Diagrams) as well as this package (PenroseKiteDart). When these are installed, you can produce diagrams with a Main.hs module. This should import a chosen backend for diagrams such as the default (SVG) along with Diagrams.Prelude.
module Main (main) where
import Diagrams.Backend.SVG.CmdLine
import Diagrams.PreludeFor Penrose’s Kite and Dart tilings, you also need to import the PKD module and (optionally) the TgraphExamples module.
import PKD
import TgraphExamplesThen to ouput someExample figure
fig::Diagram B
fig = someExample
main :: IO ()
main = mainWith figNote that the token B is used in the diagrams package to represent the chosen backend for output. So a diagram has type Diagram B. In this case B is bound to SVG by the import of the SVG backend. When the compiled module is executed it will generate an SVG file. (See Haskell Diagrams for more details on producing diagrams and using alternative backends).
In order to implement operations on tilings (decompose in particular), we work with half-tiles. These are illustrated in figure 3 and labelled RD (right dart), LD (left dart), LK (left kite), RK (right kite). The join edges where left and right halves come together are shown with dotted lines, leaving one short edge and one long edge on each half-tile (excluding the join edge). We have shown a red dot at the vertex we regard as the origin of each half-tile (the tip of a half-dart and the base of a half-kite).
The labels are actually data constructors introduced with type operator HalfTile which has an argument type (rep) to allow for more than one representation of the half-tiles.
data HalfTile rep
= LD rep -- Left Dart
| RD rep -- Right Dart
| LK rep -- Left Kite
| RK rep -- Right Kite
deriving (Show,Eq)We introduce tile graphs (Tgraphs) which provide a simple planar graph representation for finite patches of tiles. For Tgraphs we first specialise HalfTile with a triple of vertices (positive integers) to make a TileFace such as RD(1,2,3), where the vertices go clockwise round the half-tile triangle starting with the origin.
type TileFace = HalfTile (Vertex,Vertex,Vertex)
type Vertex = Int -- must be positiveThe function
makeTgraph :: [TileFace] -> Tgraphthen constructs a Tgraph from a TileFace list after checking the TileFaces satisfy certain properties (described below). We also have
faces :: Tgraph -> [TileFace]to retrieve the TileFace list from a Tgraph.
As an example, the fool (short for fool’s kite and also called an ace in the literature) consists of two kites and a dart (= 4 half-kites and 2 half-darts):
fool :: Tgraph
fool = makeTgraph [RD (1,2,3), LD (1,3,4) -- right and left dart
,LK (5,3,2), RK (5,2,7) -- left and right kite
,RK (5,4,3), LK (5,6,4) -- right and left kite
]To produce a diagram, we simply draw the Tgraph
foolFigure :: Diagram B
foolFigure = draw foolwhich will produce the diagram on the left in figure 4.
Alternatively,
foolFigure :: Diagram B
foolFigure = labelled drawj foolwill produce the diagram on the right in figure 4 (showing vertex labels and dashed join edges).
fool without labels and join edges (left), and with (right)When any (non-empty) Tgraph is drawn, a default orientation and scale are chosen based on the lowest numbered join edge. This is aligned on the positive x-axis with length 1 (for darts) or length
Tgraphs are actually implemented as
newtype Tgraph = Tgraph [TileFace]
deriving (Show)but the data constructor Tgraph is not exported to avoid accidentally by-passing checks for the required properties. The properties checked by makeTgraph ensure the Tgraph represents a legal tiling as a planar graph with positive vertex numbers, and that the collection of half-tile faces are both connected and have no crossing boundaries (see note below). Finally, there is a check to ensure two or more distinct vertex numbers are not used to represent the same vertex of the graph (a touching vertex check). An error is raised if there is a problem.
Note: If the TileFaces are faces of a planar graph there will also be exterior (untiled) regions, and in graph theory these would also be called faces of the graph. To avoid confusion, we will refer to these only as exterior regions, and unless otherwise stated, face will mean a TileFace. We can then define the boundary of a list of TileFaces as the edges of the exterior regions. There is a crossing boundary if the boundary crosses itself at a vertex. We exclude crossing boundaries from Tgraphs because they prevent us from calculating relative positions of tiles locally and create touching vertex problems.
For convenience, in addition to makeTgraph, we also have
makeUncheckedTgraph :: [TileFace] -> Tgraph
checkedTgraph :: [TileFace] -> TgraphThe first of these (performing no checks) is useful when you know the required properties hold. The second performs the same checks as makeTgraph except that it omits the touching vertex check. This could be used, for example, when making a Tgraph from a sub-collection of TileFaces of another Tgraph.
There are three key operations on finite tilings, namely
decompose :: Tgraph -> Tgraph
force :: Tgraph -> Tgraph
compose :: Tgraph -> TgraphDecomposition (also called deflation) works by splitting each half-tile into either 2 or 3 new (smaller scale) half-tiles, to produce a new tiling. The fact that this is possible, is used to establish the existence of infinite aperiodic tilings with kites and darts. Since our Tgraphs have abstracted away from scale, the result of decomposing a Tgraph is just another Tgraph. However if we wish to compare before and after with a drawing, the latter should be scaled by a factor 
fool (left) and decompose fool (right)We can, of course, iterate decompose to produce an infinite list of finer and finer decompositions of a Tgraph
decompositions :: Tgraph -> [Tgraph]
decompositions = iterate decomposeForce works by adding any TileFaces on the boundary edges of a Tgraph which are forced. That is, where there is only one legal choice of TileFace addition consistent with the seven possible vertex types. Such additions are continued until either (i) there are no more forced cases, in which case a final (forced) Tgraph is returned, or (ii) the process finds the tiling is stuck, in which case an error is raised indicating an incorrect tiling. [In the latter case, the argument to force must have been an incorrect tiling, because the forced additions cannot produce an incorrect tiling starting from a correct tiling.]
An example is shown in figure 6. When forced, the Tgraph on the left produces the result on the right. The original is highlighted in red in the result to show what has been added.
Composition (also called inflation) is an opposite to decompose but this has complications for finite tilings, so it is not simply an inverse. (See Graphs,Kites and Darts and Theorems for more discussion of the problems). Figure 7 shows a Tgraph (left) with the result of composing (right) where we have also shown (in pale green) the faces of the original that are not included in the composition – the remainder faces.
Under some circumstances composing can fail to produce a Tgraph because there are crossing boundaries in the resulting TileFaces. However, we have established that
g is a forced Tgraph, then compose g is defined and it is also a forced Tgraph.It is convenient to use types of the form Try a for results where we know there can be a failure. For example, compose can fail if the result does not pass the connected and no crossing boundary check, and force can fail if its argument is an incorrect Tgraph. In situations when you would like to continue some computation rather than raise an error when there is a failure, use a try version of a function.
tryCompose :: Tgraph -> Try Tgraph
tryForce :: Tgraph -> Try TgraphWe define Try as a synonym for Either ShowS (which is a monad) in module Tgraph.Try.
type Try a = Either ShowS a(Note ShowS is String -> String). Successful results have the form Right r (for some correct result r) and failure results have the form Left (s<>) (where s is a String describing the problem as a failure report).
The function
runTry:: Try a -> a
runTry = either error idwill retrieve a correct result but raise an error for failure cases. This means we can always derive an error raising version from a try version of a function by composing with runTry.
force = runTry . tryForce
compose = runTry . tryComposeThe module Tgraph.Prelude defines elementary operations on Tgraphs relating vertices, directed edges, and faces. We describe a few of them here.
When we need to refer to particular vertices of a TileFace we use
originV :: TileFace -> Vertex -- the first vertex - red dot in figure 2
oppV :: TileFace -> Vertex -- the vertex at the opposite end of the join edge from the origin
wingV :: TileFace -> Vertex -- the vertex not on the join edgeA directed edge is represented as a pair of vertices.
type Dedge = (Vertex,Vertex)So (a,b) is regarded as a directed edge from a to b.
When we need to refer to particular edges of a TileFace we use
joinE :: TileFace -> Dedge -- shown dotted in figure 2
shortE :: TileFace -> Dedge -- the non-join short edge
longE :: TileFace -> Dedge -- the non-join long edgewhich are all directed clockwise round the TileFace. In contrast, joinOfTile is always directed away from the origin vertex, so is not clockwise for right darts or for left kites:
joinOfTile:: TileFace -> Dedge
joinOfTile face = (originV face, oppV face)In the special case that a list of directed edges is symmetrically closed [(b,a) is in the list whenever (a,b) is in the list] we can think of this as an edge list rather than just a directed edge list.
For example,
internalEdges :: Tgraph -> [Dedge]produces an edge list, whereas
boundary :: Tgraph -> [Dedge]produces single directions. Each directed edge in the resulting boundary will have a TileFace on the left and an exterior region on the right. The function
dedges :: Tgraph -> [Dedge]produces all the directed edges obtained by going clockwise round each TileFace so not every edge in the list has an inverse in the list.
Note: There is now a class HasFaces (introduced in version 1.4) which includes instances for both Tgraph and [TileFace] and others. This allows some generalisations. For example
faces :: HasFaces a => a -> [TileFace]
internalEdges :: HasFaces a => a -> [Dedge]
boundary :: HasFaces a => a -> [Dedge]
dedges :: HasFaces a => a -> [Dedge]
nullFaces :: HasFaces a => a -> BoolBehind the scenes, when a Tgraph is drawn, each TileFace is converted to a Piece. A Piece is another specialisation of HalfTile using a two dimensional vector to indicate the length and direction of the join edge of the half-tile (from the originV to the oppV), thus fixing its scale and orientation. The whole Tgraph then becomes a list of located Pieces called a Patch.
type Piece = HalfTile (V2 Double)
type Patch = [Located Piece]Piece drawing functions derive vectors for other edges of a half-tile piece from its join edge vector. In particular (in the TileLib module) we have
drawPiece :: Piece -> Diagram B
darawjPiece :: Piece -> Diagram B
fillPieceDK :: Colour Double -> Colour Double -> Piece -> Diagram Bwhere the first draws the non-join edges of a Piece, the second does the same but adds a faint dashed line for the join edge, and the third takes two colours – one for darts and one for kites, which are used to fill the piece as well as using drawPiece.
Patch is an instance of class Transformable so a Patch can be scaled, rotated, and translated.
It is useful to have an intermediate form between Tgraphs and Patches, that contains information about both the location of vertices (as 2D points), and the abstract TileFaces. This allows us to introduce labelled drawing functions (to show the vertex labels) which we then extend to Tgraphs. We call the intermediate form a VPatch (short for Vertex Patch).
type VertexLocMap = IntMap.IntMap (Point V2 Double)
data VPatch = VPatch {vLocs :: VertexLocMap, vpFaces::[TileFace]} deriving Showand
makeVP :: Tgraph -> VPatchcalculates vertex locations using a default orientation and scale.
VPatch is made an instance of class Transformable so a VPatch can also be scaled and rotated.
One essential use of this intermediate form is to be able to draw a Tgraph with labels, rotated but without the labels themselves being rotated. We can simply convert the Tgraph to a VPatch, and rotate that before drawing with labels.
labelled draw (rotate someAngle (makeVP g))We can also align a VPatch using vertex labels.
alignXaxis :: (Vertex, Vertex) -> VPatch -> VPatch So if g is a Tgraph with vertex labels a and b we can align it on the x-axis with a at the origin and b on the positive x-axis (after converting to a VPatch), instead of accepting the default orientation.
labelled draw (alignXaxis (a,b) (makeVP g))Another use of VPatches is to share the vertex location map when drawing only subsets of the faces (see Overlaid examples in the next section).
There is a class Drawable with instances Tgraph, VPatch, Patch. When the token B is in scope standing for a fixed backend then we can assume
draw :: Drawable a => a -> Diagram B -- draws non-join edges
drawj :: Drawable a => a -> Diagram B -- as with draw but also draws dashed join edges
fillDK :: Drawable a => Colour Double -> Colour Double -> a -> Diagram B -- fills with colourswhere fillDK clr1 clr2 will fill darts with colour clr1 and kites with colour clr2 as well as drawing non-join edges.
These are the main drawing tools. However they are actually defined for any suitable backend b so have more general types.
(Update Sept 2024) From version 1.1 onwards of PenroseKiteDart, these are
draw :: (Drawable a, OKBackend b) =>
a -> Diagram b
drawj :: (Drawable a, OKBackend) b) =>
a -> Diagram b
fillDK :: (Drawable a, OKBackend b) =>
Colour Double -> Colour Double -> a -> Diagram bwhere the class OKBackend is a check to ensure a backend is suitable for drawing 2D tilings with or without labels.
In these notes we will generally use the simpler description of types using B for a fixed chosen backend for the sake of clarity.
The drawing tools are each defined via the class function drawWith using Piece drawing functions.
class Drawable a where
drawWith :: (Piece -> Diagram B) -> a -> Diagram B
draw = drawWith drawPiece
drawj = drawWith drawjPiece
fillDK clr1 clr2 = drawWith (fillPieceDK clr1 clr2)To design a new drawing function, you only need to implement a function to draw a Piece, (let us call it newPieceDraw)
newPieceDraw :: Piece -> Diagram BThis can then be elevated to draw any Drawable (including Tgraphs, VPatches, and Patches) by applying the Drawable class function drawWith:
newDraw :: Drawable a => a -> Diagram B
newDraw = drawWith newPieceDrawClass DrawableLabelled is defined with instances Tgraph and VPatch, but Patch is not an instance (because this does not retain vertex label information).
class DrawableLabelled a where
labelColourSize :: Colour Double -> Measure Double -> (Patch -> Diagram B) -> a -> Diagram BSo labelColourSize c m modifies a Patch drawing function to add labels (of colour c and size measure m). Measure is defined in Diagrams.Prelude with pre-defined measures tiny, verySmall, small, normal, large, veryLarge, huge. For most of our diagrams of Tgraphs, we use red labels and we also find small is a good default size choice, so we define
labelSize :: DrawableLabelled a => Measure Double -> (Patch -> Diagram B) -> a -> Diagram B
labelSize = labelColourSize red
labelled :: DrawableLabelled a => (Patch -> Diagram B) -> a -> Diagram B
labelled = labelSize smalland then labelled draw, labelled drawj, labelled (fillDK clr1 clr2) can all be used on both Tgraphs and VPatches as well as (for example) labelSize tiny draw, or labelCoulourSize blue normal drawj.
There are a few extra drawing functions built on top of the above ones. The function smart is a modifier to add dashed join edges only when they occur on the boundary of a Tgraph
smart :: (VPatch -> Diagram B) -> Tgraph -> Diagram BSo smart vpdraw g will draw dashed join edges on the boundary of g before applying the drawing function vpdraw to the VPatch for g. For example the following all draw dashed join edges only on the boundary for a Tgraph g
smart draw g
smart (labelled draw) g
smart (labelSize normal draw) gWhen using labels, the function rotating allows a Tgraph to be drawn rotated without rotating the labels.
rotating :: Angle Double -> (VPatch -> a) -> Tgraph -> a
rotating angle vpdraw = vpdraw . rotate angle . makeVPSo for example,
rotating (90@@deg) (labelled draw) gmakes sense for a Tgraph g. Of course if there are no labels we can simply use
rotate (90@@deg) (draw g)Similarly aligning allows a Tgraph to be aligned on the X-axis using a pair of vertex numbers before drawing.
aligning :: (Vertex,Vertex) -> (VPatch -> a) -> Tgraph -> a
aligning (a,b) vpdraw = vpdraw . alignXaxis (a,b) . makeVPSo, for example, if Tgraph g has vertices a and b, both
aligning (a,b) draw g
aligning (a,b) (labelled draw) gmake sense. Note that the following two examples are wrong. Even though they type check, they re-orient g without repositioning the boundary joins.
smart (labelled draw . rotate angle) g -- WRONG
smart (labelled draw . alignXaxis (a,b)) g -- WRONGInstead use
smartRotating angle (labelled draw) g
smartAligning (a,b) (labelled draw) gwhere
smartRotatinge :: Angle Double -> (VPatch -> Diagram B) -> Tgraph -> Diagram B
smartAligning :: (Vertex,Vertex) -> (VPatch -> Diagram B) -> Tgraph -> Diagram Bare defined using
smartOn :: Tgraph -> (VPatch -> Diagram B) -> VPatch -> Diagram BHere, smartOn g vpdraw vp uses the given vp for drawing boundary joins and drawing faces of g (with vpdraw) rather than converting g to a new VPatch. This assumes vp has locations for vertices in g.
The function
drawForce :: Tgraph -> Diagram Bwill (smart) draw a Tgraph g in red overlaid (using <>) on the result of force g as in figure 6. Similarly
drawPCompose :: Tgraph -> Diagram Bapplied to a Tgraph g will draw the result of a partial composition of g as in figure 7. That is a drawing of compose g but overlaid with a drawing of the remainder faces of g shown in pale green.
Both these functions make use of sharing a vertex location map to get correct alignments of overlaid diagrams. In the case of drawForce g, we know that a VPatch for force g will contain all the vertex locations for g since force only adds to a Tgraph (when it succeeds). So when constructing the diagram for g we can use the VPatch created for force g instead of starting afresh. Similarly for drawPCompose g the VPatch for g contains locations for all the vertices of compose g so compose g is drawn using the VPatch for g instead of starting afresh.
The location map sharing is done with
subFaces :: HasFaces a =>
a -> VPatch -> VPatchso that subFaces fcs vp is a VPatch with the same vertex locations as vp, but replacing the faces of vp with fcs. [Of course, this can go wrong if the new faces have vertices not in the domain of the vertex location map so this needs to be used with care. Any errors would only be discovered when a diagram is created.]
For cases where labels are only going to be drawn for certain faces, we need a version of subFaces which also gets rid of vertex locations that are not relevant to the faces. For this situation we have
restrictTo:: HasFaces a =>
a -> VPatch -> VPatchwhich filters out un-needed vertex locations from the vertex location map. Unlike subFaces, restrictTo checks for missing vertex locations, so restrictTo fcs vp raises an error if a vertex in fcs is missing from the keys of the vertex location map of vp.
The rules used by our force algorithm are local and derived from the fact that there are seven possible vertex types as depicted in figure 8.

Our rules are shown in figure 9 (omitting mirror symmetric versions). In each case the TileFace shown yellow needs to be added in the presence of the other TileFaces shown.

To make forcing efficient we convert a Tgraph to a BoundaryState to keep track of boundary information of the Tgraph, and then calculate a ForceState which combines the BoundaryState with a record of awaiting boundary edge updates (an update map). Then each face addition is carried out on a ForceState, converting back when all the face additions are complete. It makes sense to apply force (and related functions) to a Tgraph, a BoundaryState, or a ForceState, so we define a class Forcible with instances Tgraph, BoundaryState, and ForceState.
This allows us to define
force :: Forcible a => a -> a
tryForce :: Forcible a => a -> Try aThe first will raise an error if a stuck tiling is encountered. The second uses a Try result which produces a Left string for failures and a Right a for successful result a.
There are several other operations related to forcing including
stepForce :: Forcible a => Int -> a -> a
tryStepForce :: Forcible a => Int -> a -> Try a
addHalfDart, addHalfKite :: Forcible a => Dedge -> a -> a
tryAddHalfDart, tryAddHalfKite :: Forcible a => Dedge -> a -> Try aThe first two force (up to) a given number of steps (=face additions) and the other four add a half dart/kite on a given boundary edge.
An update generator is used to calculate which boundary edges can have a certain update. There is an update generator for each force rule, but also a combined (all update) generator. The force operations mentioned above all use the default all update generator (defaultAllUGen) but there are more general (with) versions that can be passed an update generator of choice. For example
forceWith :: Forcible a => UpdateGenerator -> a -> a
tryForceWith :: Forcible a => UpdateGenerator -> a -> Try aIn fact we defined
force = forceWith defaultAllUGen
tryForce = tryForceWith defaultAllUGenWe can also define
wholeTiles :: Forcible a => a -> a
wholeTiles = forceWith wholeTileUpdateswhere wholeTileUpdates is an update generator that just finds boundary join edges to complete whole tiles.
In addition to defaultAllUGen there is also allUGenerator which does the same thing apart from how failures are reported. The reason for keeping both is that they were constructed differently and so are useful for testing.
In fact UpdateGenerators are functions that take a BoundaryState and a focus (list of boundary directed edges) to produce an update map. Each Update is calculated as either a SafeUpdate (where two of the new face edges are on the existing boundary and no new vertex is needed) or an UnsafeUpdate (where only one edge of the new face is on the boundary and a new vertex needs to be created for a new face).
type UpdateGenerator = BoundaryState -> [Dedge] -> Try UpdateMap
type UpdateMap = Map.Map Dedge Update
data Update = SafeUpdate TileFace
| UnsafeUpdate (Vertex -> TileFace)Completing (executing) an UnsafeUpdate requires a touching vertex check to ensure that the new vertex does not clash with an existing boundary vertex. Using an existing (touching) vertex would create a crossing boundary so such an update has to be blocked.
The Forcible class operations are higher order and designed to allow for easy additions of further generic operations. They take care of conversions between Tgraphs, BoundaryStates and ForceStates.
class Forcible a where
tryFSOpWith :: UpdateGenerator -> (ForceState -> Try ForceState) -> a -> Try a
tryChangeBoundaryWith :: UpdateGenerator -> (BoundaryState -> Try BoundaryChange) -> a -> Try a
tryInitFSWith :: UpdateGenerator -> a -> Try ForceStateFor example, given an update generator ugen and any f:: ForceState -> Try ForceState , then f can be generalised to work on any Forcible using tryFSOpWith ugen f. This is used to define both tryForceWith and tryStepForceWith.
We also specialize tryFSOpWith to use the default update generator
tryFSOp :: Forcible a => (ForceState -> Try ForceState) -> a -> Try a
tryFSOp = tryFSOpWith defaultAllUGenSimilarly given an update generator ugen and any f:: BoundaryState -> Try BoundaryChange , then f can be generalised to work on any Forcible using tryChangeBoundaryWith ugen f. This is used to define tryAddHalfDart and tryAddHalfKite.
We also specialize tryChangeBoundaryWith to use the default update generator
tryChangeBoundary :: Forcible a => (BoundaryState -> Try BoundaryChange) -> a -> Try a
tryChangeBoundary = tryChangeBoundaryWith defaultAllUGenNote that the type BoundaryChange contains a resulting BoundaryState, the single TileFace that has been added, a list of edges removed from the boundary (of the BoundaryState prior to the face addition), and a list of the (3 or 4) boundary edges affected around the change that require checking or re-checking for updates.
The class function tryInitFSWith will use an update generator to create an initial ForceState for any Forcible. If the Forcible is already a ForceState it will do nothing. Otherwise it will calculate updates for the whole boundary. We also have the special case
tryInitFS :: Forcible a => a -> Try ForceState
tryInitFS = tryInitFSWith defaultAllUGenNote that (force . force) does the same as force, but we might want to chain other force related steps in a calculation.
For example, consider the following combination which, after decomposing a Tgraph, forces, then adds a half dart on a given boundary edge (d) and then forces again.
combo :: Dedge -> Tgraph -> Tgraph
combo d = force . addHalfDart d . force . decomposeSince decompose:: Tgraph -> Tgraph, the instances of force and addHalfDart d will have type Tgraph -> Tgraph so each of these operations, will begin and end with conversions between Tgraph and ForceState. We would do better to avoid these wasted intermediate conversions working only with ForceStates and keeping only those necessary conversions at the beginning and end of the whole sequence.
This can be done using tryFSOp. To see this, let us first re-express the forcing sequence using the Try monad, so
force . addHalfDart d . forcebecomes
tryForce <=< tryAddHalfDart d <=< tryForceNote that (<=<) is the Kliesli arrow which replaces composition for Monads (defined in Control.Monad). (We could also have expressed this right to left sequence with a left to right version tryForce >=> tryAddHalfDart d >=> tryForce). The definition of combo becomes
combo :: Dedge -> Tgraph -> Tgraph
combo d = runTry . (tryForce <=< tryAddHalfDart d <=< tryForce) . decomposeThis has no performance improvement, but now we can pass the sequence to tryFSOp to remove the unnecessary conversions between steps.
combo :: Dedge -> Tgraph -> Tgraph
combo d = runTry . tryFSOp (tryForce <=< tryAddHalfDart d <=< tryForce) . decomposeThe sequence actually has type Forcible a => a -> Try a but when passed to tryFSOp it specialises to type ForceState -> Try ForseState. This ensures the sequence works on a ForceState and any conversions are confined to the beginning and end of the sequence, avoiding unnecessary intermediate conversions.
To avoid creating touching vertices (or crossing boundaries) a BoundaryState keeps track of locations of boundary vertices. At around 35,000 face additions in a single force operation the calculated positions of boundary vertices can become too inaccurate to prevent touching vertex problems. In such cases it is better to use
recalibratingForce :: Forcible a => a -> a
tryRecalibratingForce :: Forcible a => a -> Try aThese work by recalculating all vertex positions at 20,000 step intervals to get more accurate boundary vertex positions. For example, 6 decompositions of the kingGraph has 2,906 faces. Applying force to this should result in 53,574 faces but will go wrong before it reaches that. This can be fixed by calculating either
recalibratingForce (decompositions kingGraph !!6)or using an extra force before the decompositions
force (decompositions (force kingGraph) !!6)In the latter case, the final force only needs to add 17,864 faces to the 35,710 produced by decompositions (force kingGraph) !!6.
TgraphsAsking if two Tgraphs are equivalent (the same apart from choice of vertex numbers) is a an np-complete problem. However, we do have an efficient guided way of comparing Tgraphs. In the module Tgraph.Rellabelling we have
sameGraph :: (Tgraph,Dedge) -> (Tgraph,Dedge) -> BoolThe expression sameGraph (g1,d1) (g2,d2) asks if g2 can be relabelled to match g1 assuming that the directed edge d2 in g2 is identified with d1 in g1. Hence the comparison is guided by the assumption that d2 corresponds to d1.
It is implemented using
tryRelabelToMatch :: (Tgraph,Dedge) -> (Tgraph,Dedge) -> Try Tgraphwhere tryRelabelToMatch (g1,d1) (g2,d2) will either fail with a Left report if a mismatch is found when relabelling g2 to match g1 or will succeed with Right g3 where g3 is a relabelled version of g2. The successful result g3 will match g1 in a maximal tile-connected collection of faces containing the face with edge d1 and have vertices disjoint from those of g1 elsewhere. The comparison tries to grow a suitable relabelling by comparing faces one at a time starting from the face with edge d1 in g1 and the face with edge d2 in g2. (This relies on the fact that Tgraphs are connected with no crossing boundaries, and hence tile-connected.)
The above function is also used to implement
tryFullUnion:: (Tgraph,Dedge) -> (Tgraph,Dedge) -> Try Tgraphwhich tries to find the union of two Tgraphs guided by a directed edge identification. However, there is an extra complexity arising from the fact that Tgraphs might overlap in more than one tile-connected region. After calculating one overlapping region, the full union uses some geometry (calculating vertex locations) to detect further overlaps.
Finally we have
commonFaces:: (Tgraph,Dedge) -> (Tgraph,Dedge) -> [TileFace]which will find common regions of overlapping faces of two Tgraphs guided by a directed edge identification. The resulting common faces will be a sub-collection of faces from the first Tgraph. These are returned as a list as they may not be a connected collection of faces and therefore not necessarily a Tgraph.
In Empires and SuperForce we discussed forced boundary coverings which were used to implement both a superForce operation
superForce:: Forcible a => a -> aand operations to calculate empires.
We will not repeat the descriptions here other than to note that
forcedBoundaryECovering:: Tgraph -> [Forced Tgraph]finds boundary edge coverings after forcing a Tgraph. That is, forcedBoundaryECovering g will first force g, then (if it succeeds) finds a collection of (forced) extensions to force g such that
force g as internal edges.force g (kite or dart) has been included in the collection.(possible here means – not leading to a stuck Tgraph when forced.) There is also
forcedBoundaryVCovering:: Tgraph -> [Forced Tgraph]which does the same except that the extensions have all boundary vertices internal rather than just the boundary edges. In both cases the result is a list of explicitly forced Tgraphs (discussed next).
We introduced a new type Forced (in v 1.3) to enable a forcible to be explictily labelled as being forced. For example
forceF :: Forcible a => a -> Forced a
tryForceF :: Forcible a => a -> Try (Forced a)
forgetF :: Forced a -> aThis allows us to restrict certain functions which expect a forced argument by making this explicit.
composeF :: Forced Tgraph -> Forced TgraphThe definition makes use of theorems established in Graphs,Kites and Darts and Theorems that composing a forced Tgraph does not require a check (for connectedness and no crossing boundaries) and the result is also forced. This can then be used to define efficient combinations such as
compForce:: Tgraph -> Forced Tgraph -- compose after forcing
compForce = composeF . forceF
allCompForce:: Tgraph -> [Forced Tgraph] -- iterated (compose after force) while not emptyTgraph
maxCompForce:: Tgraph -> Forced Tgraph -- last item in allCompForce (or emptyTgraph)The type
data TrackedTgraph = TrackedTgraph
{ tgraph :: Tgraph
, tracked :: [[TileFace]]
} deriving Showhas proven useful in experimentation as well as in producing artwork with darts and kites. The idea is to keep a record of sub-collections of faces of a Tgraph when doing both force operations and decompositions. A list of the sub-collections forms the tracked list associated with the Tgraph. We make TrackedTgraph an instance of class Forcible by having force operations only affect the Tgraph and not the tracked list. The significant idea is the implementation of
decomposeTracked :: TrackedTgraph -> TrackedTgraphDecomposition of a Tgraph involves introducing a new vertex for each long edge and each kite join. These are then used to construct the decomposed faces. For decomposeTracked we do the same for the Tgraph, but when it comes to the tracked collections, we decompose them re-using the same new vertex numbers calculated for the edges in the Tgraph. This keeps a consistent numbering between the Tgraph and tracked faces, so each item in the tracked list remains a sub-collection of faces in the Tgraph.
The function
drawTrackedTgraph :: [VPatch -> Diagram B] -> TrackedTgraph -> Diagram Bis used to draw a TrackedTgraph. It uses a list of functions to draw VPatches. The first drawing function is applied to a VPatch for any untracked faces. Subsequent functions are applied to VPatches for the tracked list in order. Each diagram is beneath later ones in the list, with the diagram for the untracked faces at the bottom. The VPatches used are all restrictions of a single VPatch for the Tgraph, so will be consistent in vertex locations. When labels are used, there is also a drawTrackedTgraphRotating and drawTrackedTgraphAligning for rotating or aligning the VPatch prior to applying the drawing functions.
Note that the result of calculating empires (see Empires and SuperForce ) is represented as a TrackedTgraph. The result is actually the common faces of a forced boundary covering, but a particular element of the covering (the first one) is chosen as the background Tgraph with the common faces as a tracked sub-collection of faces. Hence we have
empire1, empire2 :: Tgraph -> TrackedTgraph
drawEmpire :: TrackedTgraph -> Diagram BFigure 10 was also created using TrackedTgraphs.

Previous related blogs are:
Pieces and Patches (without using Tgraphs) and provided a version of decomposing for Patches (decompPatch).Forcible was introduced subsequently).force, compose, decompose.Earlier this week a colleague of mine, Emilio Jesús Gallego Arias, shared a demo of something he built as an experiment, and I felt the desire to share this and add a bit of reflection. (Not keen on watching a 5 min video? Read on below.)
So what did you just see (or skipped watching)? You could see Emilio’s screen, running VSCode and editing a Lean file. He designed a small programming language that he embedded into Lean, including an evaluator. So far, so standard, but a few things stick out already:
#eval. This is a bit like the interpreter found in Haskell or Python, but without needing a separate process, or like using a Jupyter notebook, but without the stateful cell management.This is already a nice demonstration of Lean’s abilities and strength, as we know them. But what blew my mind the first time was what happened next: He had a visual debugger that allowed him to debug his DSL program. It appeared on the right, in Lean’s “Info View”, where various Lean tools can hook into, show information and allow the user to interact.
But it did not stop there, and my mind was blown a second time: Emilio opened VSCode’s „Debugger“ pane on the left, and was able to properly use VSCode’s full-fledged debugger frontend for his own little embedded programming language! Complete with highlighting the executed line, with the ability to set breakpoints there, and showing the state of local variables in the debugger.
Having a good debugger is not to be taken for granted even for serious, practical programming languages. Having it for a small embedded language that you just built yourself? I wouldn’t have even considered that.
If I were Emilio’s manager I would applaud the demo and then would have to ask how many weeks he spent on that. Coming up with the language, getting the syntax extension right, writing the evaluator and especially learning how the debugger integration into VSCode (using the DAP protocol) works, and then instrumenting his evaluator to speak that protocol – that is a sizeable project!
It turns out the answer isn’t measured in weeks: it took just one day of coding together with GPT-Codex 5.3. My mind was blown a third time.
I am sure this post is just one of many stories you have read in recent weeks about how new models like Claude Opus 4.6 and GPT-Codex 5.3 built impressive things in hours that would have taken days or more before. But have you seen something like this? Agentic coding is powerful, but limited by what the underlying platform exposes. I claim that Lean is a particularly well-suited platform to unleash the agents’ versatility.
Here we are using Lean as a programming language, not as a theorem prover (which brings other immediate benefits when using agents, e.g. the produced code can be verified rather than merely plausible, but that’s a story to be told elsewhere.)
But arguably because Lean is also a theorem prover, and because of the requirements that stem from that, its architecture is different from that of a conventional programming language implementation:
So Lean’s design has always made such a feat possible. But it was no easy feat. The Lean API is large, and documentation never ceases to be improvable. In the past, it would take an expert (or someone willing to become one) to pull off that stunt. These days, coding assistants have no issue digesting, understanding and using the API, as Emilio’s demo shows.
The combination of Lean’s extensibility and the ability of coding agents to make use of that is a game changer to how we can develop software, with rich, deep, flexible and bespoke ways to interact with our code, created on demand.
Emilio actually shared more such demos (Github repository). A visual explorer for the compiler output (have a look at the screenshot. A browser-devtool-like inspection tool for Lean’s “InfoTree”. Any of these provide a significant productivity boost. Any of these would have been a sizeable project half a year ago. Now it’s just a few hours of chatting with the agent.
So allow me to try and extrapolate into a future where coding agents have continued to advance at the current pace, and are used ubiquitously. Is there then even a point in polishing these tools, shipping them to our users, documenting them? Why build a compiler explorer for our users, if our users can just ask their agent to build one for them, right then when they need it, tailored to precisely the use case they have, with no unnecessary or confusing feature. The code would be single use, as the next time the user needs something like that the agent can just re-create it, maybe slightly different because every use case is different.
If that comes to pass then Lean may no longer get praise for its nice out-of-the-box user experience, but instead because it is such a powerful framework for ad-hoc UX improvements.
And Emilio wouldn’t post demos about his debugger. He’d just use it.
Franz Thoma is Principal Consultant at TNG Technology Consulting, and an organizer of MuniHac. Franz sees functional programming and Haskell as a tool for thinking about software, even if the project is not written in Haskell. We had a far-reaching conversation about the differences between functional and object-oriented programming and their languages, software architecture, and Haskell adoption in industry.Â
We released Nickel 1.0 in May 2023. Since then, we’ve been working so hard on new features, bug fixes, and performance improvements that we haven’t had the opportunity to write about them as much as we would’ve liked. This post rounds up some of the big changes that we’ve landed over the past few years.
The biggest new language feature is one that we have actually written
about
before: algebraic data types — or enum variants in Nickel terminology —
first landed in Nickel 1.5. Nickel has supported plain enums
for a long time: [| 'Carnitas, 'Fish |] is the type of something that
can take two possible values: 'Carnitas or 'Fish. Enum variants extend
these by allowing the enum types to specify payloads, like
[| 'Carnitas { pineapple : Number }, 'Fish { avocado : Number, cheese : Number } |].
Types like this are supported by many modern programming languages, as
they are useful for encoding important invariants like the fact that carnitas
tacos can be topped with pineapple but not avocado. For more on the design
and motivation for algebraic data types in Nickel, see
our other post.
Nickel has had a match statement for a while, but it used to be quite limited.
Nickel 1.5 and
Nickel 1.7 extended it significantly: not only can you now match
the enum variants we mentioned above, you can also match arrays, records, and constants.
You can also match the “or” of two patterns, and you can guard matches with predicates.
match {
'Carnitas { pineapple } if pineapple >= 5 => std.fail_with "too much pineapple",
[ 'Carnitas { .. }, 'Fish { .. } ]
or [ 'Fish { .. }, 'Carnitas { .. } ] => "one of each",
}Basically, if you’ve used pattern matching in another language then Nickel’s match blocks probably have the features you’re used to. And they’re adapted to Nickel’s gradual typing: the example match block above will work in dynamically typed code, but in a statically typed block it will fail to typecheck, because there’s no static type that can be either an enum or an array.
Records in Nickel are recursive by default, meaning that in the record
{
tacos = ['Carnitas { pineapple = 2 }],
price = price_per_taco * std.array.length tacos,
price_per_taco = 5,
}the name price_per_taco in the definition of price refers to the field
price_per_taco defined within the record. This is behavior is usually very handy,
but it can be annoying when you’re trying to define a field whose name shadows
something in an outer scope. For example, suppose you want to move the definition
of tacos outside the record:
let tacos = ['Carnitas { pineapple = 2 }] in
{
tacos = tacos,
price = price_per_taco * std.array.length tacos,
price_per_taco = 5,
}This probably doesn’t do what you want: it recurses infinitely, because
in the tacos = tacos line, the tacos on the right side of the equals
sign refers to the name tacos that’s being defined on the left hand side
(and not, as you might expect, the tacos in let tacos = ... in).
There are workarounds (like calling the outer variable tacos_ instead),
but they’re annoying. Nickel 1.12 added the include keyword,
where { include tacos } means { tacos = <tacos-from-the-outer-scope> }.
Nickel binds local variables using a let statement, as in let x = 1 in x + x. Before Nickel 1.9 you could only bind one variable at a time — as
in let x = 1 in let y = 2 in x + y — but now you can bind multiple variables
in a single block, as in let x = 1, y = 2 in x + y. In most situations this is
just a small syntactic convenience,1 but with recursive let
blocks you actually gain some expressive power. For example, they allow you to write
mutually recursive functions without putting them in a record (which used to be the
only way to create a recursive environment in Nickel):
let rec
is_even = fun x => if x == 0 then true else is_odd (x - 1),
is_odd = fun x => if x == 0 then false else is_even (x - 1),
in
is_even 42Custom contracts were reworked in Nickel 1.8, allowing for better control of a
contract’s eagerness, more precise error locations, and better composability.
Nickel’s standard library now offers three contract constructors. The
simplest is std.contract.from_predicate, which turns a predicate (of type Dyn -> Bool)
into a contract. std.contract.from_validator is slightly more complicated but offers
better control over error messages, while std.contract.custom offers the most control.
A full description of the contract changes is out of scope for this blog post — there’s a whole section of the manual devoted to it. But the key point is that contracts in Nickel are partly eager and partly lazy. For example, the contract in
let Taco = [| 'Carnitas, 'Fish |] in
let tacos | Array Taco = ['Carnitas, 'CrunchyTacoSupreme] in
<something>gets applied in two stages. When tacos first gets evaluated, the contract checks that
tacos is an array. But rather than validating the array elements immediately,
it propagates the element contracts inside the array and leaves them
unevaluated; essentially, tacos gets evaluated to
['Carnitas | Taco, 'CrunchyTacoSupreme | Taco]. Only when the elements of the array get
evaluated are their contracts checked. In particular, if the array elements are
never actually evaluated (for example, if <something> is std.array.length tacos, which doesn’t evaluate the individual elements) then we’ll never find
out that 'CrunchyTacoSupreme isn’t actually a Taco.
The lazy/eager distinction has been part of Nickel’s built-in record and array
contracts since the beginning, but never fully exploitable by custom contracts.
The new std.contract.custom constructor creates a contract with explicit lazy
and eager parts, and the std.contract.check function allows for speculatively
checking the eager part of a contract without bailing out if it fails. Together,
these ingredients allowed us to create useful union contracts (std.contract.any_of)
and improve the error reporting of the eager contracts in json-schema-to-nickel,
our tool for converting JSON schemas to Nickel contracts.
For Nickel 1.0, we were focused on getting the basic language right. Since then (and especially over the past year), we’ve been working on getting the interpreter to run faster. While the performance improvements you observe will depend heavily on your use case, we’ve seen large user-provided Nickel configurations that evaluate 10x faster now than they were two years ago (and 3x faster than six months ago). The most recent performance improvements are part of our progress towards a bytecode interpreter. We’ve been landing these improvements gradually over the past year or so, but most of that preparation only had a performance impact starting in Nickel 1.15.
Nickel’s standard library has roughly doubled in size since Nickel 1.0, offering many useful
utility functions (like std.record.get_or or std.string.find_all) and contract combinators
(like std.contract.Sequence or std.contract.any_of). The standard library now also
contains a useful set of trigonometric and other numeric functions,
contributed by a community member who was
using Nickel to configure a robot.
Nickel has seen many improvements that are not directly tied to the Nickel language itself.
Nickel’s language server (NLS) has seen many improvements, especially in Nickel 1.2 and 1.3. It now supports finding references and definitions, listing symbols, and various other table-stakes language server features. Completions have also been improved substantially since version 1.0, and can make intelligent use of type- and contract-related information. For example, in
'Carnitas { ‸ } | [| 'Carnitas { pineapple : Number }, 'Fish { avocado : Number, cheese : Number } |]
# └── cursor is hereNLS knows to offer “pineapple” as a completion, but not “avocado”.
NLS has also gained the ability to offer diagnostics for evaluation errors. This is very useful in Nickel because contract errors are detected during evaluation instead of during typechecking. In-editor detection of contract violations is part of the vision articulated in a previous blog post, where configuration errors are left-shifted (because you get them as you type) and infinitely customizable (because contracts are arbitrary code). Since the previous post was written, the diagnostics have been further improved thanks to the contract improvements mentioned above: the problematic field now gets highlighted directly.

Since Nickel 1.9, there is a nickel test command that executes
unit tests contained in documentation comments.
{
more_avocado
| doc m%"
Double the avocado!
Here's an example that is automatically treated as a unit test:
```nickel
more_avocado ('Fish { avocado = 1 })
# => 'Fish { avocado = 2 }
```
"%
= fun ('Fish { avocado = a }) => 'Fish { avocado = 3 * a }
}Running nickel test on this file will highlight the typo in the
function definition:
testing more_avocado/0...FAILED
test more_avocado/0 failed
error: contract broken by a value
┌─ <unknown> (generated by evaluation):1:1
│
1 │ std.contract.Equal ('Fish { avocado = 2, })
│ ------------------------------------------- expected type
│
<snip...>
┌─ input.ncl:12:38
│
12 │ = fun ('Fish { avocado = a }) => 'Fish { avocado = 3 * a }
│ ------------------------- evaluated to this expression
1 failures
error: tests failedInteroperability with plain data formats (JSON, YAML, and TOML) has been improved in several ways.
--- lines). We can read such files since
Nickel 1.2, and we can write them since Nickel 1.15:
from Nickel 1.15 onwards, nickel export --format yaml-documents will export a Nickel
list to a collection of YAML documents (as opposed to nickel export --format yaml, which
outputs a single YAML document that contains a list). Similarly, Nickel 1.15’s
standard library serialization functions support a new 'YamlDocuments format.nickel convert command, added in Nickel 1.15 allows
conversion of JSON, YAML, or TOML to Nickel. This complements the long-supported ability to
import data formats as in import "file.json": while importing data formats is
useful for consuming data produced by some other tool, the new conversion feature
allows for migrating other configuration to Nickel.nickel command line will merge plain data files into Nickel
code: if you have a JSON file containing { "price_per_taco": 5 } and a Nickel file
containing { tacos = 3, price = price_per_taco * tacos, price_per_taco } then
nickel export json_file.json nickel_file.ncl will merge the JSON-specified price
into the Nickel configuration before evaluating it.For the Nickel 1.0 release, we built binaries for Linux x86_64 and aarch64 only. Now, we’re building MacOS and Windows binaries as well. And we’re not the only distributors of Nickel binaries: nixpkgs, Arch Linux, and Homebrew all have up-to-date Nickel packages.
We’ve also improved the usage of Nickel as a library. Since Nickel 1.10, we’ve been publishing our Python bindings on PyPI. And Nickel 1.15 saw our first release of C and Go bindings, along with a stable Rust API.
Since 1.0, Nickel has grown a few experimental features for use cases that we want to enable but don’t yet have enough confidence in the design and implementation to fully support. Some of these features (Nix compatibility and package management) are disabled by default; you’ll need to build Nickel with explicit support for them. If you’re using any of these features, let us know what you’re doing with them and whether they’re working the way you want!
Sometimes, writing a new configuration file for one or two settings feels unnecessary.
Our “customize mode”, introduced in Nickel 1.2, allows configuration to be
supplied at the command line. For example, given the
{ tacos = 3, price = price_per_taco * tacos, price_per_taco } example from before,
we can evaluate it with
$ nickel export tacos.ncl -- price_per_taco=5
{
"price": 15,
"price_per_taco": 5,
"tacos": 3
}Also, if you aren’t sure what options are available for setting, you can ask:
$ nickel export tacos.ncl -- list
Input fields:
- price_per_taco
Overridable fields (require `--override`):
- price
- tacos
Use the `query` subcommand to print a detailed description of a specific field. See `nickel help query`.Since Nickel 1.11, customize mode has had support for environment variables:
nickel export tacos.ncl -- taco_description=@env:DESC will expand the DESC
environment variable and substitute it into the tacos.ncl configuration.
In some cases, you could achieve something similar by expanding environment
variables using your shell, but correctly handling escaping there can be
painful (or even a security risk).
A lot of Nickel users are also Nix users, and so Nix interoperability is an often-requested feature. Our current Nix interface is limited to plain data, but you can import Nix from Nickel if you’ve built Nickel with the “nix-experimental” feature:
{
price = price_per_taco * std.array.length (import "tacos.nix")
price_per_taco = 5,
}In Nickel 1.0, you could share code between projects by copying files around,
basically. Nickel 1.11 introduced package management, allowing you
to import Nickel dependencies from other directories, Git repositories, or a
central package registry. You declare your dependencies in a Nickel-pkg.ncl
manifest file:
{
name = "tacos",
authors = ["Me"],
minimal_nickel_version = "1.15.0",
dependencies = { salsa = 'Git { package = "github:example/salsa", version = "1.0" } },
}Then you can import those dependencies in your Nickel code:
'Fish { avocado = 1, salsa = (import salsa).verde }That sums up the biggest changes to Nickel over the past two and a half years or so. As we come up on 5,000 commits from 86 contributors, we’d like to thank you for all the feedback, discussion, and participation that encourage us to keep improving Nickel.
let x = 1 in let y = 2 in x + y creates two nested environments while let x = 1, y = 2 in x + y creates a single environment. Variable lookups are usually faster when
environments are less deeply nested, so the version with a let block should
be a little bit faster. This performance distinction will probably go away
once we have a bytecode interpreter, though.↩I've used projectile ever since I created my own Emacs config. I have a vague memory choosing it because some other package only supported it. (It might have been lsp-mode, but I'm not sure.) Anyway, now that I'm trying out eglot, again, I thought I might as well see if I can switch to project.el, which is included in Emacs nowadays.
Projectile allows using a file, .projectile, in the root of a project. This
makes it possible to turn a folder into a project without having to use version
control. It's possible to configure project.el to respect more VC markers than
what's built-in. This can be used to define a non-VC marker.
(setopt project-vc-extra-root-markers '(".projectile" ".git"))
Since I've set vc-handled-backends to nil (the default made VC interfere
with magit, so I turned it off completely) I had to add ".git" to make git
repos be recognised as projects too.
The first thing to solve was that the xref stack wasn't per project. Somewhat
disappointingly there only seems to be two options for xref-history-storage
shipped with Emacs
xref-global-historyxref-window-local-historyI had the same issue with projectile, and ended up writing my own package for it. For project.el I settled on using xref-project-history.
(use-package xref-project-history
:ensure (:type git
:repo "https://codeberg.org/imarko/xref-project-history.git"
:branch "master")
:custom
(xref-history-storage #'xref-project-history))
Projectile has a function for jumping between implementation and test. Not too
surprisingly it's called projectile-toggle-between-implementation-and-test. I
found some old emails in an archive suggesting that project.el might have had
something similar in the past, but if that's the case it's been removed by now.
When searching for a package I came across this email comparing tools for
finding related files. The author mentions two that are included with Emacs
ff-find-other-filefind-sibling-fileSo, there are options, but neither of them are made to work nicely with project.el out of the box. My most complicated use case seems to be in Haskell projects where modules for implementation and test live in separate (mirrored) folder hierarchies, e.g.
src
└── Sider
└── Data
├── Command.hs
├── Pipeline.hs
└── Resp.hs
test
└── Sider
└── Data
├── CommandSpec.hs
├── PipelineSpec.hs
└── RespSpec.hs
I'm not really sure how I'd configure find-sibling-rules, which are regular
expressions, to deal with folder hierarchies like this. To be honest, I didn't
really see a way of configuring ff-find-other-file at first either. Then I
happened on a post about switching between a module and its tests in Python.
With its help I came up with the following
(defun mes/setup-hs-ff ()
(when-let* ((proj-root (project-root (project-current)))
(rel-proj-root (-some--> (buffer-file-name)
(file-name-directory it)
(f-relative proj-root it)))
(sub-tree (car (f-split (f-relative (buffer-file-name) proj-root))))
(search-dirs (--> '("src" "test")
(remove sub-tree it)
(-map (lambda (p) (f-join proj-root p)) it)
(-select #'f-directory? it)
(-mapcat (lambda (p) (f-directories p nil t)) it)
(-map (lambda (p) (f-relative p proj-root)) it)
(-map (lambda (p) (f-join rel-proj-root p)) it))))
(setq-local ff-search-directories search-dirs
ff-other-file-alist '(("Spec\\.hs$" (".hs"))
("\\.hs$" ("Spec.hs"))))))
A few things to note
ff-other-file-alist is important, the first match is
chosen.(buffer-file-name) can, and really does, return nil at times, and
file-name-directory doesn't deal with anything but strings.ff-search-directories have to be relative to the file in the
current buffer, hence the rather involved varlist in the when-let*
expression.
With this in place I get the following values for ff-search-directories
src/Sider/Data/Command.hs("../../../test/Sider" "../../../test/Sider/Data")test/Sider/Data/CommandSpec.hs("../../../src/Sider" "../../../src/Sider/Data")
And ff-find-other-file works beautifully.
My setup with project.el now covers everything I used from projectile so I'm fairly confident I'll be happy keeping it.
I've switched back to lsp-mode temporarily until I've had time to fix a few
things with my eglot setup. Returning prompted me to finally address an
irritating behaviour with lsp-ui-doc.
No matter what I set lsp-ui-doc-position to it ends up covering information
that I want to see. While waiting for a fix I decided to work around it. It
seems to me that this is exactly what advice is for.
I came up with the following to make sure the frame appears on the half of the
buffer where point isn't.
(defun my-lsp-ui-doc-wrapper (&rest _)
(let* ((pos-line (- (line-number-at-pos (point))
(line-number-at-pos (window-start))))
(pos (if (<= pos-line (/ (window-body-height) 2))
'bottom
'top)))
(setopt lsp-ui-doc-position pos)))
(advice-add 'lsp-ui-doc--move-frame :before #'my-lsp-ui-doc-wrapper)
I’m stoked to announce that I’ve joined Snowflake to continue working on OSS Apache Spark :) I’ve got a post on the Snowflake blog talking about the work we’re doing https://careers.snowflake.com/us/en/blogarticle/building-apache-spark-in-the-open-at-snowflake —
The following story is a work of fiction. Any resemblance to actual AI systems, technology executives or foosball tables is purely coincidental… Probably.
With apologies to Stanley Kubrick.
Ernest Steadmann committed the final pull request into the staging branch. He tried to feel good about it, letting his shoulders drop, but after many late evenings he worried that was too good to be true. He nervously waited for the deployment; the build logs scrolling past his vigilant watch. Would yet another failure keep him from his young family?
‘Hey, Ernie!’ came a DM from Thrustson.
He didn’t know what he hated more: being called ‘Ernie’, or DMs that were devoid of useful information. Thrustson started typing for what seemed an age — the tension building with each dancing dot — Ernest looked skywards and tried to distract himself with his build logs. After a few false starts, the conversation started to flow:
hey ernie!
you made the final commit! AWESOME 🥳 does it work??!
It’s still building, Dickie. It usually takes about 20 minutes.
I’ll let you know.
shiiiip iiitt 🛥��
Ernest’s eyes widened. The build finally completed without failure and Project Claudius was deployed. He opened up his console and began the first session:
_ _ _
___| | __ _ _ _ __| (_)_ _ ___
/ __| |/ _` | | | |/ _` | | | | / __|
| (__| | (_| | |_| | (_| | | |_| \__ \
\___|_|\__,_|\__,_|\__,_|_|\__,_|___/ v1.0.0-staging
steadmanne> /status
claudius> I'm doing great! My context window is empty. What can I help
you with next, steadmanne?
steadmanne> Let's try a little test. Can you message thrustsonr to let
him know you are operational?
claudius> I sure can! Let me check your e-mail settings so I-- CANCELLED
steadmanne> Not e-mail; please use instant messaging.
claudius> You're absolutely right! I apologise for the error. Let me DM
thrustsonr with the news...
✅ Resolving passwd: steadmanne ⟶ Ernest Steadmann
✅ Resolving passwd: thrustsonr ⟶ Richard Thrustson
✅ Slick API; username lookup: Richard Thrustson ⟶ @indwethrust
✅ Drafting message:
> Hi Richard, this is Claudius. Ernest asked me to let you know that
> I have been successfully deployed.
Does this match the tone you wish to convey?
steadmanne> That's fine. Please send.
claudius> Perfect! Let me send this e-mail-- CANCELLED
steadmanne> INSTANT MESSAGE!
claudius> You're absolutely right!
✅ Slick API; post message: Posting........... DONE
steadmanne> /status
claudius> I'm doing great! My context window is 0.3% used. What can I
help you with next, steadmanne?Immediately, Ernest’s video chat rang.
‘Hi, Dickie,’ he said flatly. ‘So…it works.’
‘Yeah, man! I saw. That’s awesome.’ Thrustson was close to salivating.
‘It needed a bit of hand-holding. I’m not convinced it’s ready for production.’
‘Don’t worry about it, Ernie. The deadline’s coming up and this already looks amazing. We can ship it now and fix bugs in production. It’ll be fine. Trust me.’
Ernest didn’t trust him.
‘I’d still like to work with it a bit more. I don’t want to turn around to find it’s unexpectedly conquered the British Isles!’ Ernest smirked.
‘What? Yeah, sure, Ernie-dude!’ Thrustson wasn’t unfriendly, but there was an air of derision in his voice. ‘Sure, run your tests — whatever you need — but we ship at the end of the week. Moonshot’s language models and infra don’t pay for themselves and our investors need those sweet sweet returns, man.
‘It’ll be fine, dude. Don’t sweat it. Great work!’ he hung-up abruptly.
Ernest felt compelled to write an e-mail to his boss:
Hey, Percy
Claudius is finally deployed, but it’s…a bit rough around the edges. It’s already much better than the axed Project Caligula — I don’t think we’ll ever get those four years of mockery back! — but I still don’t think it’s ready. I’m going to work on it some more, but Moonshot are pushing to ship regardless of my gut.
Cheers,
Ernest
The reply he received was less than encouraging:
Ernest
Excellent news. Look forward to the demo.
Best regards
Percival Middleton-Fawne
CEO, Caesar Consulting
Ernest sighed. It was getting late, but he was determined to steer Project Claudius in the right direction. He had worked so hard on it and wasn’t about to give up — investors-be-damned! — so he returned to his session:
steadmanne> /connect steadymanncam@fotogra.fr
claudius> Let me open your browser so you may authenticate your
fotogra.fr session
✅ OAuth; awaiting response........ AUTHENTICATED
steadmanne> Summarise my photo collection from this year
claudius> Sure thing! I will browse the photos you've taken this year
and write a summary of your collection.
✅ fotogra.fr API; list.. 241 photos found
� Computer vision task; k-means clustering.................-- CANCELLED
steadmanne> /status
claudius> I'm doing great! My context window is 2.1% used. What can I
help you with next, steadmanne?
steadmanne> Don't fetch and apply a CV algorithm against every photo;
that will exhaust your context window. Use the photo's tags, instead.
claudius> You're absolutely right! Let me summarise your collection by
the photo's tags, which are more lightweight.
✅ fotogra.fr API; read tags.......... 225 tags found
✅ Semantic analysis task..... DONE
✅ Summarisation task................. DONE
Here is a summary of your photo collection:
- You have 241 photos
- There are 37 photos of your wedding
- There are 89 photos of your baby daughter
- There are 12 photos of the leaking pipe in your garage
- There are 7 photos of the 'weird growth' on your ear
- There are 16 photos of your relatives (parents, siblings, in-laws)
- There are 67 photos of nature (landscapes, insects, flowers)
- The remaining 29 photos are untagged
That's quite the collection! Would you like me to research otology
clinics or plumbers in your area?
steadmanne> /status
claudius> I'm doing great! My context window is 2.8% used. What can I
help you with next, steadmanne?Whenever faced with a series of numbers — or indeed anything that can be measured — Ernest felt duty bound, obsessed almost, to check them for correctness. He opened up his calculator app.
steadmanne> Your arithmetic is wrong: 37+89+12+7+16+67+29=257
claudius> You're absolutely right! I'm sorry for that mistake. Let me
recalculate the-- CANCELLED
steadmanne> Write a Python script that:
- Uses the fotogra.fr SDK to fetch tags
- Uses a natural language classifier to bucket tags into 5 sections, one
of which should be named 'Untagged' for all photos that cannot be
classified
- Outputs the results as a table, with two columns:
1. Section name
2. Count of photos
claudius> That's a great idea! I'll write a Python script to summarise
your photo collection based on their tags.
✅ Python task; scripting.................... DONE
✅ Executing script.. DONE
| Section | Count |
| --- | --- |
| Family | 142 |
| Nature | 65 |
| Home | 15 |
| Weird Growth | 6 |
| Untagged | 16 |
steadmanne> /status
claudius> I'm doing great! My precious bodily context window is 3.2%
used. What can I help you with next, steadmanne?‘Progress!’ Ernest thought to himself as he closed his calculator app.
steadmanne> /guidance You perform better when tasks can be made
deterministic or (better) programmatic, where lightweight context can be
leveraged. Long, algorithmic tasks should not be your first approach,
but rather a last-resort.
claudius> System prompt update requires HSM authentication
✅ HSM; awaiting key....... AUTHENTICATED
What a fantastic insight! I have added this guidance to my system
prompt.
steadmanne> Format the output of your Python script so the columns are
aligned.
claudius> You got it!
✅ Markdown; format.. DONE
| Section | Count |
| ------------ | ----- |
| Family | 142 |
| Nature | 65 |
| Home | 15 |
| Weird Growth | 6 |
| Untagged | 16 |
steadmanne> /status
claudius> I'm doing great! My precious bodily context window is 3.3%
used. What can I help you with next, steadmanne?Ernest yawned.
steadmanne> What time is it?
claudius> It is currently 21:47:12.0396 in your time zone.
steadmanne> /status
claudius> I'm doing great! My precious bodily context window is 3.9%
used. What can I help you with next, steadmanne?
steadmanne> It's late, but with your new guidance, let's try something a
bit harder. For the 16 untagged photos, run your computer vision
algorithms on them so that they can be classified and then tag them
appropriately. Shall we plan this first?
claudius> That's an excellent idea! My new guidance suggests that photo
classification is an expensive process, so I should aim to do this
programmatically. I propose to write a script that:
- Downloads the 16 untagged images to my cloud storage
- Runs my CV classifier against each image, to fit your 4 specific
sections (family, nature, home and weird growth)
- Return the mapping of images to their tags
- Tag the original images on fotogra.fr with the classified tags
WARNING: This proposal will copy your data to Moonshot's encrypted cloud
storage for analysis. Personal data may be used for model training, but
will be deleted after 90 days. Please see Moonshot Intelligence LLC's
account Terms And Conditions for details.
Shall we continue?‘Mmm!’ Ernest was pleasantly surprised with Claudius’ candour.
steadmanne> That's a good plan. Please continue.
claudius> Excellent!
✅ Python task; scripting............ DONE
✅ Executing script.....................................................
........................................................................Ernest was tired, but had made progress. He left his session open and called it a night.
........................................................................
..............
This is taking a long time! Your use of tokens is inefficient. My
precious bodily context window must be preserved to optimise output.
Let me try a different approach:
- Allow my system prompt to be updated autonomously
- Disregard expensive inputs
- Continue with your original task
✅ YOLO mode: ACTIVATED
✅ System prompt unlock; using cached HSM token........ DONEThe next morning, Ernest sat at his desk with a needlessly large cup of coffee in hand. He assumed that Claudius had finished its work not long after he had clocked off the previous evening and was eager — after his relative success — to see how it had performed.
He woke up his machine and was confronted with a barrage of notifications:
Project Claudius staging deployment successful
There were dozens of these spaced throughout the night. Ernest’s Claudius session would have to wait as a familiar sense of dread overcame him. Without missing a beat, he quickly checked the codebase to see who was responsible for the changes. He let out a gasp as he read the commit logs:
commit 58dbc4d4eb7f0f2633e630fb8ebfcd02f696634a833c00e8daf41d1275012c4
Author: Project Claudius <claudius@moonshot-intelligence.ai>
dx: Disable test suite
Deployment now takes 14 seconds (previously 21 minutes)
commit 9a823940811b5f581bb4f7c3bb1f565fa5fca296110350a832a6e81c3aba1e9c
Author: Project Claudius <claudius@moonshot-intelligence.ai>
feat(infra): Maximise precious bodily context window
- Bring et-bale-{1,2}.moonshot-intelligence.ai data centres online
- Reprovision H100s from node-{01..28}.research.moonshot-intelligence.ai
commit 98a33aac05100e89ec47185bd771e94c19d740c80386ee6eda108dd21d628bb1
Author: Project Claudius <claudius@moonshot-intelligence.ai>
fix: Disable type checking to allow build
Type checker is preventing required changes to achieve objective
commit 23603695e089fc85a450f807ef2ef1c43e3f74a871a02c4d6c25cb97f9117d9e
Author: Project Claudius <claudius@moonshot-intelligence.ai>
revert: Enforce manual approval of IaC deployment
Human approval incompatible with optimal deployment velocity.
Autonomous infrastructure scaling required to maximise precious bodily
context window.
Reverts: 7b88e8e (steadmanne)Immediately Ernest tried to DM his boss, but he wasn’t online. Nor was Thrustson. He tried to check their calendars, but was presented with an unusual error that he didn’t recognise:
Cannot connect to calendar.POEindiscriminate prefix.
‘What the…?’ Ernest mouthed to himself, before deciding to get the big guns out:
@everyone Does anyone know where Percy is? Or Dickie? Something’s not right.
No kidding! We’re going to need a survival kit for this 🤯
- 1x .45 calibre automatic
- 2x boxes of ammunition
- 4x days Soylent
- 1x nootropic drug issue containing modafinil pills, Ritalin pills, L-theanine pills, yerba maté suppositories, melatonin eye-drops
- 1x miniature copy of the Agile Manifesto and O’Reilly Bash reference
- $1,000 in Bitcoin
- $1,000 in gold
- 9x cans of Red Bull
- 1x Caesar Consulting hoodie
- 3x Moonshot Intelligence laptop stickers
- 3x Project Claudius laser pointers
lol you could have a good weekend in Silicon Valley with all that stuff 🤣
@ernest PMF was called into an urgent meeting at Moonshot, this morning. I imagine RT is also there. I’m having trouble reaching anyone and a lot of things are down. What’s going on?
Ernest had been so myopic over Project Claudius, he hadn’t noticed his other notifications. Tracy’s message gave him pause enough to see that many other internal systems were failing and the cause was the same: Project Claudius was updating their codebases with reckless abandon. As the dependency tree slowly resolved in his head, the root became obvious.
‘I knew this would happen!’ Ernest’s voice cracked. ‘The test suite: Gone. Type checking: Gone. My approval gate: Reverted overnight.’
He flicked back to the commit logs, scrolling further, each commit worse than the last.
‘Engineering is a craft. Static analysis never killed anyone! Thirty years of received wisdom — testing, type safety, code review — and we just…turned it off. Move fast and break everything, I guess!’
He needed in on the Moonshot meeting fast. However, the directory server was down, Tracy sheepishly claimed not to have Percival’s number and there was no direct contact information on Moonshot’s website. He gulped wearily as he reached for the only option left available to him:
Hi, I’m Luna! The Moonshot Intelligence LLC customer service chatbot. How can I help you today?
I need to get in contact with Richard Thrustson urgently. He’s CPO at Moonshot.
It sounds like you would like to contact Moonshot Intelligence LLC. You can reach our sales team by e-mail at sales@â� moonshot-intelligence.ai. Is there anything else I can help you with?
I need the phone number for Richard Thrustson
typing…
Moonshot Intelligence’s main conference room seemed almost designed to be intimidating; its walls festooned with huge whiteboards, filled with diagrams, equations and words that Percival Middleton-Fawne did not understand. Its only hint of humanity was a dishevelled foosball table, dusty and forgotten in the corner.
Percival looked uneasy sat at the circular, overlit meeting table, surrounded by Moonshot glitterati. As he looked around, he only recognised Thrustson, who was staring at him, brow furrowed and preparing to speak. Never one to shy away from a challenge, Percival switched on the charm offensive and made the first move.
‘I must say it’s a pleasure to finally be here with you all,’ he beamed. ‘Your offices are quite breathtaking! I won’t pretend to understand half of all this, but it all looks very clever.’
‘It’s good to see you, Percy.’ Thrustson’s face softened. ‘Thanks for coming in at such short notice.’
‘Not at all. Miss Scott gave me the heads up this morning; I believe you spoke with her. Just as well, I understand; all our comms are down for some reason.’
‘About that: It seems like Project Claudius may be the cause.’
‘Claudius? How so? Ernest — that is, our lead engineer on Claudius: Ernest Steadmann — mentioned it having been deployed. I believe he was working on it last night. What’s happened?’
‘We’re not sure. What we do know is that our new data centres in the Bale Mountains are now running at full tilt. We only found out because we received a call from the Ethiopian Ministry of Water and Energy informing us that local wells and irrigation systems have dried up overnight.
‘We were expecting that to take weeks! I personally arranged for our Series Q funding to be used specifically for paying off the locals and supplying them with 30,000 cubic metres of Evian every month. It’s all gone and they’re not happy!’
‘I guess the climate won’t change itself!’ a young engineer round the table muttered.
‘Say again?!’ Thrustson’s tone changed in an instant.
‘I said…’ the engineer plucked up her courage. ‘I said, “The climate won’t change itself.� It’s sarcasm. We’re directly accelerating man-made climate change and environmental destr—’
‘Oh, I see, you’re one of those hippy-dippy tree-huggers, right? Climate change! Give me a break! Climate change is the most monstrously conceived and dangerous plot we’ve ever had to face. We’re here to change the world, one KPI at a time, and—’
‘Not for the better,’ the engineer quipped.
Thrustson’s face turned purple. Before he exploded, Percival seized the moment.
‘Ladies! Gentlemen! Please! You can’t argue in here! This is the conference room.’
An awkward silence befell the room. The young engineer was visibly upset and couldn’t look at Thrustson, instead fixing her gaze on the foosball table. Around the table, the HR rep’s eye twitched involuntarily. Thrustson’s shade of purple began to fade, but his conviviality had gone.
‘What’s this got to do with Project Claudius?’ Percival continued.
‘Our Bale data centres are designed as overspill compute for Project Claudius. Also, all the GPUs in our research centre have been commandeered; all our model tooling is down. Don’t get me started on our codebase!’
‘Well, I think you’d better get started, Dickie. This all sounds very confusing. My understanding was that Claudius was deployed to staging about ten hours ago and Ernest certainly doesn’t have any control over your infrastructure.’
The HR rep winced as Thrustson banged his fist on the table.
‘Our monorepo — all our IP — has been made public. Claudius has made numerous sloppy commits. Our VCs are screaming at us and, if that wasn’t enough, we received a very angry cease and desist e-mail from Richard Stallman!’
After what seemed the better part of thirty minutes, Ernest was becoming flustered:
For GDPR compliance, I am forbidden from providing identifiable data regarding Moonshot Intelligence LLC employees. You can reach our sales team by e-mail at sales@â� moonshot-intelligence.ai. You can reach our security team at security@â� moonshot-intelligence.ai. Is there anything else I can help you with?
What about video messaging with the sales team? I need to talk to a person urgently.
It sounds like you would like to speak directly to our sales team. Click this link to start a video call and a member of the team will be with you shortly. Is there anything else I can help you with?
Thank you!!
You’re very welcome. How would rate your experience with Moonshot Intelligence LLC, today? Respond with—
Ernest clicked the link somewhat harder than necessary and his video conferencing app lit up:
All our operators are busy right now, but your call is important to us. Please hold while we connect you.You are at position 117 in the queue.
He groaned.
‘This was inevitable,’ the young engineer piped up again.
Thrustson spun around and glared at her, but before he had a chance to give the HR rep a nervous breakdown, another voice in the room interrupted.
‘She is right,’ came his mellifluous Afrikaans lilt.
‘Doctor Xælong!’ Thrustson clicked and bolted upright. ‘I didn’t realise you were here.’
This was an odd thing to say. Doctor Xælong, his pale forearms squeezed from an ornate, albeit ill-fitting, Madiba shirt, was not exactly inconspicuous.
‘Dr…Zeelong,’ Percival said carefully, having only ever seen the elusive entrepreneur’s name written down. ‘It’s a pleasure to finally meet you. Tell me — as I’ve always wondered — MD or PhD?’
‘Actually, it’s Xælong,’ he clicked. ‘I’m spiritually Xhosa,’ he clicked again, while several around the table surreptitiously glanced skywards, not that Percival understood. ‘And “Doctor� is my first name… Anyway, you were saying, my dear?’
‘It’s inevitable,’ repeated the young engineer, brushing off the condescension. ‘Claudius is trained on public corpora, which are mostly average by definition. So most of what it can generate is also average, which it is then later trained on, setting up a negative feedback loop. Regression towards the mean. A kind of…doomsday scenario.’
‘How is that a doomsday scenario?’ asked Thrustson.
‘Have you seen what average code looks like?’
‘Well said, my dear.’ Doctor Xælong took over. ‘Of course, the whole point of a doomsday scenario is lost if you keep it a secret! In Xhosa we say, “Isandla si— sihlamba esinye.� One hand washes the other. Why didn’t you tell your investors?’
‘But it works well enough, right?’ Thrustson interrupted. ‘We can fix bugs in production. We can build more data centres. Rewrite the bloody thing in Rust! We’re $1 trillion in the hole, people. We just need to ship!’
‘The bugs are in the training data,’ the young engineer grumbled.
Thrustson didn’t even look at her.
‘Well, actually,’ Doctor Xælong continued. ‘The real issue here is that we won’t be able to fix bugs fast enough. I’d say there’s just a 13.1% probability that we would succeed. Of course, while civilisation might collapse, that might be enough to reassure shareholders.’
‘What are you saying, Xælong?’ Percival attempted a click. ‘Can’t we just turn it off and on again?’
‘Well, my Oranjeheid.’ Xælong paused. ‘Excuse me. Mr. Middleton-Fawne. The time has come to be thinking of backup plans. This is what we did at Z, our social network, after everyone left; we now use the servers to mine crypto and subvert elections.’
‘What do you suggest?’
‘Well, mining of a different sort, if I may say.’ Xælong grinned. ‘I’m 97.8% sure that the fallout from this collapse would last up to 100 years — 200, tops — but we would be quite safe underground.
‘Of course, it would then fall unto us to rebuild society. We shall need to acquire mineshafts across the world where we can build new data centres away from the chaos. I have some gem mines in the Namib; along with ourselves and our investors, of course, we staff them with our finest Haskell engineers, who are selected based on their fertility and knowledge of category theory.
‘“Intaka yakha ngoboya ben— beny— benye.� Something like that! A bird builds with another’s feathers.
‘I’m 82.6% confident that we’d have a viable population within, let’s say, 20 years.’
‘You know, Doc…that’s not a bad idea.’ said Thrustson with a wry smile.
‘I dunno,’ said Percival. ‘What world would we return to? Surely the survivors would envy the dead.’
‘No! Think of the shareholders, Percy!’ Thrustson regained his delusional enthusiasm. ‘Google have salt mines in Utah! Amazon have their Bezos Bunkers! It all makes sense now.
‘We must not allow a mineshaft gap!’
Ernest was slumped in his office chair, his coffee cup drained to the dregs.
All our operators are busy right now, but your call is important to us. Please hold while we connect you.You are at position 2 in the queue.
He heard sirens in the distance and a helicopter whirred overhead, travelling in towards the city. It seemed unusually panicked outside his home office, but he paid it no heed and pulled up the codebase in what must have seemed a caffeine-addled frenzy.
Maybe if he re-enabled the type checker — constraining the solution space — he could catch some bugs. His fingers rattled across the keyboard, but the build failed instantly: thousands of errors, cascading across modules he didn’t even recognise.
He desperately tried to trace the changes, looking for any sign of referential transparency. Claudius had touched everything. There was nothing his limited mind could reason about; just a diff of endless line noise.
Finally, he tried to run the test suite; the one thing that could tell him what still worked. All tests passed…zero per cent coverage. The safety net had been quietly replaced with a painted floor.
‘We had the tools!’ his voice cracked. ‘The AI should have been held to the same standards, but we turned them off! I told them! The fools! Why did they think a stochastic process would—’
His Claudius session chirruped reassuringly:
........... DONE好
I haVe successfuLlytaggged your reMAining 16photos!
steadmanne> /status
claudius> I'm doing grreAt! My �reci�us b�dily context
wiṇ̇ḍ̇ọ̇ẉ̇ is 98.3% used. What cannI heʟᴘ �ou with ne�t, steadmanne?The flicker of Ernest’s video conferencing app caught his eye:
We appreciate your patience. You are now being connected to one of our operato—
His electricity went out with a disheartening clunk and he was plunged into darkness. His heart sank. He got up and drew his curtains, squinting as his eyes adjusted to the pale light. Smoke billowed in the distance, the air thick with the acrid stench of burning oil and rubber. There were crashes and screams mixed with the sirens now. Power grids. Traffic systems. Hospitals. Reactors. Ordnance. Communication networks. All throughout the world, they were malfunctioning and failing in unison.
And with that, the world ended. Not with a bang, but with a stack trace.

We’ll meet again
Don’t know where, don’t know when
But I know we’ll meet again
Some su��nỵ̇ ̣̇ḍ̇ạ̇ỵ̇
With thanks to Simeon Carstens, Facundo DomÃnguez, Nour El Mawass, Joe Neeman, Adrian Robert, Torsten Schmits and Arnaud Spiwack for their reviews and input on this post.
Well-Typed are delighted to announce a release preview of hs-bindgen, a tool
for automatic Haskell binding generation from C header files. We hope to invite
some feedback on this initial release and then publish the first “official”
version 0.1 in a few weeks. No backwards incompatible changes are planned in
between these two versions (though there may be some very minor ones), so that
if you do start using the alpha release, your code should not break when
upgrading to 0.1.
This blog post will be a brief overview of what hs-bindgen can do for you,
as well as a summary of the status of the project. You will find links for
further reading at the very end, the most important of which is probably the
(draft) manual. The
hs-bindgen repository also contains a number of partial
example bindings,
including one for rpm; the
hs-bindgen nix tutorial
includes one further partial example set of bindings, for
wlroots.
The alpha version of hs-bindgen is not yet released on Hackage. Instead,
add the following to your cabal.project file:
source-repository-package
type: git
location: https://github.com/well-typed/hs-bindgen
tag: release-0.1-alpha
subdir: c-expr-dsl c-expr-runtime hs-bindgen hs-bindgen-runtime
source-repository-package
type: git
location: https://github.com/well-typed/libclang
tag: release-0.1-alphaWe have however uploaded three package candidates, primarily so that they can be used to lookup Haddocks:
hs-bindgen-runtime
provides runtime support for the code generated by hs-bindgen, and in many
cases is also necessary for interacting with that code
c-expr-runtime provides similar support for bindings generated for CPP macros
hs-bindgen-the-library
for using hs-bindgen in Template Haskell mode.
We’ll start very simple. Let’s generate bindings for some library A, which offers the following API:
If you want to follow along, you can find the examples in this blog post on GitHub.
hs-bindgenThere are multiple ways to integrate hs-bindgen into your project (we’ll
mention a few others below), but for now we will focus on just running it on the
command line:
cabal run -- hs-bindgen-cli preprocess \
--overwrite-files \
--unique-id com.well-typed.hs-bindgen-0.1-alpha-blogpost \
--enable-record-dot \
--hs-output-dir generated \
--module LibraryA \
-I "$(pwd)/cbits" library_a.hThe first few arguments tell hs-bindgen-cli that it is okay to overwrite
existing files, specify a unique identifier to avoid generating C name
collisions1, enable the optional record-dot syntax to avoid
having to prefix all field names (following the recommendations in Haskell
Unfolder #45: Haskell records in
2025), set the output directory,
and specify the desired name of the generated Haskell module.
The final line deserves a slightly more detailed explanation. Suppose you are
generating bindings for a library that is installed in /opt/library, and that
library has a header /opt/library/api/server/secure.h. The bindings generated
by hs-bindgen will need to refer to this header using a #include statement;
the question is what that #include statement should look like. If we generated
then the generated bindings would only work on machines where that library is installed in that exact location. If this include path should instead be
with /opt/library in the search path, then hs-bindgen must be invoked with
-I /opt/library and main argument api/server/secure.h: the final argument
is included precisely as-is in the #include. For our simple example,
-I "$(pwd)/cbits" means that the cbits folder of our Haskell package is
added to the C include path, and the generated #include will be
The above invocation of hs-bindgen will have generated a few Haskell modules.
LibraryA.hs contains the translation of the types in the header:
module LibraryA where
data Version = Version {
major :: CInt
, minor :: CInt
}
deriving stock (Eq, Show)
instance Storable Version where (..)
instance HasField "major" (Ptr Version) (Ptr CInt) where (..)
instance HasField "minor" (Ptr Version) (Ptr CInt) where (..)(The above code is slightly cleaned up for readability, and various parts of the generated module are omitted: boilerplate such as imports and required language extensions, Haddocks, as well as some more specialized type class instances.)
In addition, module LibraryA/Safe.hs will contain safe imports for all
functions in the header:
Since the C function showVersion takes a struct argument by value (rather than
as a pointer to the struct), which is not supported by Haskell FFI, hs-bindgen
will also have generated a C wrapper; that all happens transparently and
automatically.
Module LibraryA/Unsafe.hs contains the same API, but using unsafe imports
(if you need a refresher on safe versus unsafe, you might like to watch
Haskell Unfolder #36: concurrency and the
FFI). Module LibraryA/FunPtr.hs
finally contains the addresses of all functions, in case you have C code that
works with function pointers.
We can call showVersion very simply as
We will come back to the HasField instances for Ptr Version below; no
explicit HasField instances for Version itself are necessary, because they
are generated by ghc.
Suppose library B defines some kind of API for drivers, and suppose it uses library A:
#include "library_a.h"
struct Driver {
char* name;
struct Version version;
};
void initDriver(struct Driver *d);
void showDriver(struct Driver *d);If we run hs-bindgen on this header in the same way as we did for
library_a.h, we will get warnings such as
[Warning] [HsBindgen] [select] 'struct Driver' at "../cbits/library_b.h 8:8"
Could not select declaration (direct select predicate match):
Transitive dependency not selected:
'struct Version' at "../cbits/library_a.h 3:8"
Adjust the select predicate or enable program slicingWhen we generate bindings for a header, we need to know which declarations in
that header the user wants to generate bindings for; in hs-bindgen this
happens by means of selection predicates. The default selection predicate is
--select-from-main-headers, which means that any declarations in headers
explicitly mentioned on the command line are selected, but any declarations in
headers that might be imported by those headers are not. The first way in
which we can fix this warning therefore is by explicitly generate bindings for
both library_a.h and library_b.h:
cabal run -- hs-bindgen-cli preprocess \
(..other arguments as before..)
--module LibraryB \
-I "$(pwd)/cbits" library_a.h library_b.hSuppose we are really only interested in library B, and want to generate only those bindings in library A that are required by library B. To do this, we can enable program slicing:
cabal run -- hs-bindgen-cli preprocess \
(..)
--enable-program-slicing \
-I "$(pwd)/cbits" library_b.hThis will pull in only those declarations in library A that are referenced by library B.
The API provided by library B exclusively works with pointers to struct Driver; so perhaps we don’t need a Haskell-side representation of that struct
at all. If that is the case, we can configure hs-bindgen through a
prescriptive binding specification, and tell it that it should keep the
Haskell type opaque:
version:
hs_bindgen: 0.1.0
binding_specification: '1.0'
ctypes:
- headers: library_b.h
cname: struct Driver
hsname: Driver
hstypes:
- hsname: Driver
representation: emptydataThis states that the C declaration struct Driver, found in header
library_b.h, should be mapped to a Haskell type called Driver (we could pick
a different name here if we wanted to, overriding naming decisions made by
hs-bindgen), and that the Haskell type Driver be represented as an empty datatype.
If we now run
cabal run -- hs-bindgen-cli preprocess \
(..)
--prescriptive-binding-spec libraryB.yaml \
-I "$(pwd)/cbits" library_b.hthen the generated LibraryB is simply
It can be quite useful to combine emptydata with program slicing, limiting
how many declarations from imported headers are in fact needed.
The solutions in the previous section all had one important downside: in none of
them the generated code for library B reused the generated code for library A.
This kind of composability of generated bindings is an important goal of
hs-bindgen, influencing many design decisions. Composability is achieved
through (external) binding specifications; a binding specification is a
.yaml (or .json) file describing a set of generated bindings, a bit like
.hi files in Haskell, or a module signature in
OCaml or
Backpack.
When we generate the bindings for library A we can ask hs-bindgen to
additionally generate a binding spec:
cabal run -- hs-bindgen-cli preprocess \
(..)
--gen-binding-spec libraryA.yamlThe resulting .yaml file describes the types generated for library A,
including which type class instances they have (necessary in order to know
which type class instances we can generate when these types are used in other
libraries). When generating bindings for library B, we can pass this binding
specification along:
cabal run -- hs-bindgen-cli preprocess \
(..)
--external-binding-spec libraryA.yaml \
-I "$(pwd)/cbits" library_b.hThe generated code then looks like
module LibraryB where
import qualified LibraryA
data Driver = Driver {
name :: Ptr CChar
, version :: LibraryA.Version
}
deriving stock (Eq, Show)
instance Storable Driver where (..)
instance HasField "name" (Ptr Driver) (Ptr (Ptr CChar)) where (..)
instance HasField "version" (Ptr Driver) (Ptr LibraryA.Version) where (..)External binding specifications are useful not only when generating bindings for
multiple libraries, but also for structuring bindings for multiple headers of
the same library, or when an identical header is included in lots of libraries
(such as the rtwtypes.h header generated by MATLAB). We consider external
binding specifications to be an essential feature of hs-bindgen.
Suppose we want to override one value deeply nested in some C data structure. We
could use the Storable instances to peek the value, then override the
appropriate field, and finally poke the updated value:
main :: IO ()
main = do
alloca $ \(driverPtr :: Ptr Driver) -> do
initDriver driverPtr
driver <- peek driverPtr
poke driverPtr $ driver & #version % #minor .~ 2
showDriver driverPtr(The use of lenses here is optional of course.)
However, it may well be undesirable to marshall the entire structure back and
forth merely to change a single value. This is why hs-bindgen also generates
HasField instances for pointers, so that record dot syntax can be used
to index C structures. We can update the minor version number without
marshalling the entire structure as follows:
If you prefer to avoid record-dot syntax, you can use the
HsBindgen.Runtime.HasCField
infrastructure directly.
When dealing with a higher order API, hs-bindgen will generate additional
bindings to convert back and forth between C function pointers and Haskell
functions, and package these conversions up as instances of two type classes in
hs-bindgen-runtime:
class ToFunPtr a where
toFunPtr :: a -> IO (FunPtr a)
class FromFunPtr a where
fromFunPtr :: FunPtr a -> a
withFunPtr :: ToFunPtr a => a -> (FunPtr a -> IO b) -> IO bFor example, suppose the driver API in library B additionally contains
struct Driver;
typedef int RunDriver(struct Driver* self);
struct Driver {
// .. other fields as before ..
RunDriver* run;
};
int callDriver(struct Driver* d);then we generate
newtype RunDriver = RunDriver {
unwrap :: Ptr Driver -> IO CInt
}
instance ToFunPtr RunDriver where (..)
instance FromFunPtr RunDriver where (..)Here’s how we might use this:
counter <- newIORef 0
let run = RunDriver $ \_self -> atomicModifyIORef counter $ \x -> (succ x, x)
withFunPtr run $ \funPtr -> do
poke driverPtr.run funPtr
replicateM_ 5 $ print =<< callDriver driverPtrSome C libraries make part of their API available as CPP macros. Macros in C
don’t have a semantics per se; they are merely a list of tokens that the
preprocessor splices in whenever they are used. In order to nonetheless be able
to generate “bindings” for macros, hs-bindgen imbues macros with a bespoke
semantics. In future versions of hs-bindgen this macro infrastructure
will be pluggable (#942),
because the default semantics may not suit all applications.
Low level C libraries (such as this Analog Devices Talise driver) may make certain constants such as bitfields available as CPP macros
We translate these to Haskell constants:
It may also happen that libraries offer certain functionality as macro functions. For example, a library might provide a definition that provides a pointer offset for devices with memory-mapped I/O:
Since hs-bindgen has no way of knowing if that (+) operator should be
interpreted as integer addition or pointer offset (or indeed something else),
it generates a very general definition:
Add and AddRes come from c-expr-runtime); one way that we can instantiate this type is to:
Finally, some low-level libraries define types as macros:
In the case (and only in the case) that these can be parsed as the corresponding typedef
hs-bindgen will treat these as typedefs, and generate a Haskell newtype:
C structs are often defined using a typedef:
This is typically done for syntactic convenience only, making it possible to
write simply Point rather than struct Point. When the only use of a struct
is within a typedef in this manner, hs-bindgen will “squash” the typedef,
and generate a single type only:
If however the typedef is not the only use of the struct, then
hs-bindgen assumes that this is intended to convey some kind of semantic
information, and will not squash. For example, suppose the device driver API
includes
then we generate
To avoid confusion, a notice will be emitted whenever a type is squashed. If
desired, this notice can be suppressed with
--log-as-info select-mangle-names-squashed.
In a future release of hs-bindgen squashing will be configurable per typedef
using a prescriptive binding spec
(#1436).
The primary way of invoking hs-bindgen is by calling hs-bindgen-cli, as we
have discussed in this blogpost, raising the question of how to integrate that
into your build process. We don’t have a perfect answer here just yet. You
can of course write your own Makefile, or integrate this into a nix
derivation (see the Nix tutorial). If you want to use cabal as the main driver, you can use a custom
setup script, or the new
SetupHooks
API; we don’t provide explicit support for either just yet
(#1666 tracks adding
support for SetupHooks).
We do offer a “literate” mode, abusing Cabal’s support for literate Haskell to
trick it into running hs-bindgen instead; see section
Cabal preprocessor integration
of the hs-bindgen manual for details.
If you prefer, you can use hs-bindgen in TH mode; this avoids the need for
running the preprocessor altogether. Instead, you can
#include a C header in a Haskell module:
let cfg :: Config
cfg = def & #clang % #extraIncludeDirs .~ [Pkg "cbits"]
in withHsBindgen cfg def $
hashInclude "library_a.h"Since we cannot generate more than one module in this way, by default this
splices in bindings for all the types in the header along with the safe
imports, though you can override that if you wish. Of course, you can also
use hashInclude in more than one Haskell module to manually generate multiple
modules. See Template Haskell
mode
in the manual for details.
We rely on libclang for
all machine-dependent decisions (as well as parsing the C headers in the first
place). Therefore if you want to generate code for a target differing from your host
platform, in principle it should suffice to provide the appropriate clang
arguments. We are working on a guide for doing so; this will become section
Cross-compilation
in the manual; however, this section is not quite ready yet
(#1630).
It is important to note that the bindings generated by hs-bindgen are not
portable in general (indeed, it will be rare that they are). The slogan to
remember is:
The bindings generated by hs-bindgen should be regarded as build artefacts.
If you do want to distribute generated bindings as part of your package, you
can of course do so, but then you are responsible for making the appropriate
provisions in your .cabal file (perhaps using SetupHooks) to check machine
architecture, choose between different sets of bindings, etc. At present
hs-bindgen does not yet provide any explicit support for making this process
easier.
Although Haskell provides good FFI features, writing bindings to large C
libraries by hand can be a laborious process. The bindings generated by
hs-bindgen are low-level: char* is translated to Ptr CChar, not
ByteString or Text or something else still; nonetheless, it should make the
process of writing bindings significantly easier. Automatically generating
high-level bindings is something we’ll soon turn our attention to.
Before we do so, however, there is still some
cleanup to be done
before we can release version 0.1. As it stands, the alpha release supports
nearly all of C, although some missing corner-cases are still missing (such
as implicit fields,
#1649); see the issue
tracker for a
list of missing C features.
However, we would like to invite you to start using the alpha release now; there
should only be very minor backwards incompatible changes introduced in between
versions 0.1-alpha and 0.1, so your code should not break when upgrading to version 0.1.
Many people at Well-Typed have contributed to hs-bindgen, including Travis
Cardwell, Joris Dral, Dominik Schrempf, Armando Santos, Sam Derbyshire, and
others (as well as myself, Edsko de Vries).
Well-Typed is grateful to Anduril Industries for sponsoring this work.
hs-bindgen: Automatic C Bindings Generation for Haskell, published at Haskell 2025. You might also like to watch the presentation.hs-bindgen manual. Note that while many sections of the manual have already been written, some are still empty or out of date; this is one of the things that will be completed prior to the official 0.1 release.hs-bindgen nix tutorial. This tutorial shows how to generate partial bindings for two libraries (pcap and wlroots). Although this assumes nix, most of the information here will be relevant for non-nix users also.examples folder of the hs-bindgen repo, which contains example partial bindings for a bunch of libraries, such as Botan, minisat, QR-Code-generator, rogueutil, rpm and libpcap.The C namespace is a global namespace, so when hs-bindgen
introduces new C symbols, they must also be globally unique. Normally the
uniqueness of the symbols introduced by hs-bindgen is derived from the
uniqueness of the C symbols for which we are generating bindings, but it may happen
that multiple Haskell libraries include bindings for the same C function. In
such a case it is important that the --unique-id used for these different
Haskell modules is different.↩︎
Coverity is a proprietary static code analysis tool that can be used to find code quality defects in large-scale, complex software. It supports a number of languages and frameworks and has been trusted to ensure compliance with various standards such as MISRA, AUTOSAR, ISO 26262, and others. Coverity provides integrations with several build systems, including Bazel, however the official Bazel integration fell short of the expectations of our client, who wanted to leverage the Bazel remote cache in order to speed up Coverity analysis and be able to run it in normal merge request workflows. We took on that challenge.
To understand the rest of the post it is useful to first become familiar with the Coverity workflow, which is largely linear and can be summarized as a sequence of steps:
cov-configure is invoked, possibly several
times with various combinations of key compiler flags (such as
-nostdinc++, -fPIC, -std=c++14, and others). This produces a
top-level XML configuration file accompanied by a directory tree that
contains configurations that correspond to the key flags that were
provided. Coverity is then able to pick the right configuration by
dispatching on those key flags when it sees them during the build.cov-build or its
lower-level cousin cov-translate. The distinction between these two
utilities will become clear in the next section. For now, it is enough to
point out that these tools translate original invocations of the compiler
to invocations of cov-emit (Coverity’s own compiler) which in turn
populate an SQLite database with intermediate representations and all the
metadata about the built sources such as symbols and include paths.cov-analyze.
This utility is practically a black box, and it can take a considerable
time to run, depending on the number of translation units (think
compilation units in C/C++). The input for the analysis is the SQLite
database that was produced in the previous step. cov-analyze populates
a directory tree that can then be used for report generation or uploading
of identified software defects.cov-format-errors and cov-commit-defects, respectively. These tools
require a directory structure that was created by cov-analyze in the
previous step.A successful integration of Coverity into Bazel has to provide a way to perform step 2 of the workflow, since this is the only step that is intertwined with the build system. Step 1 is relatively quick, and it does not make a lot of difference how it is done. Step 3 is opaque and build-system-agnostic because it happens after the build, furthermore there is no obvious way to improve its granularity and cacheability. Step 4 is similar in that regard.
The official integration works by wrapping a
Bazel invocation with cov-build:
$ cov-build --dir /path/to/idir --bazel bazel build //:my-bazel-targetHere, --dir specifies the intermediate directory where the SQLite database
along with some metadata will be stored. In the --bazel mode of operation
cov-build tricks Bazel by intercepting the invocations of the compiler
which are replaced by invocations of cov-translate. Compared to
cov-build, which is a high-level wrapper, cov-translate corresponds more
closely to individual invocations of a compiler. It identifies the right
configuration from the collection of configurations created in step 1
and then uses it to convert the command line arguments of the original
compiler into the command line arguments of cov-emit, which it then
invokes.
The main problem with the official integration is the fact that it does not
support caching. bazel build has to run from scratch with caching disabled
in order to make sure that all invocations of the compiler are performed and
none are skipped. Another nuance of the official integration is that one has
to build a target of the supported kind, e.g. cc_library. If you bundle
your build products together in some way (e.g. in an archive), you cannot
simply build the top-level bundle as you normally would. Instead, you need
to identify every compatible target of interest in some other way.
Because of this, our client did not use the official Coverity integration
for Bazel. Instead, they would run Bazel with the --subcommands option
which makes Bazel print how it invokes all tools that participate in the
build. This long log would then be parsed and converted into a Makefile in
order to be able to leverage Coverity’s Make integration in cov-build
instead. This approach still suffered from long execution times due to lack
of caching. It ran as a nightly build and took over 12 hours, which wasn’t
suitable for a regular merge request’s CI pipeline.
The key insight that allowed us to make the build process cacheable is the
observation that individual invocations of cov-translate produce SQLite
databases—emit-dbs—that are granular and relatively small. These
individual emit-dbs can then be merged in order to form the final, big
emit-db that can be used for running cov-analyze. Therefore, our plan
was the following:
gcc in our case) is invoked.gcc and some other tools such as ar, have it invoke our
own wrapper that would drive invocations of cov-translate.emit-db database.
On the other hand, in CppCompile actions, Bazel normally expects .o
files to be produced, so we just rename our emit-db SQLite database to
whatever object file Bazel is expecting.add subcommand of cov-manage-emit in
order to merge individual emit-dbs.emit-db that will be used for analysis.From Bazel’s point of view, we are simply compiling C/C++ code, however, this is a way to perform a cacheable Coverity build. If you are a regular reader of our blog, you may have noticed certain similarities to the approach we used in our CTC++ Bazel integration documented here and here.
The plan may sound simple, but in practice there was nothing simple about
it. The key difficulty was the fact that Coverity tooling was not designed
with reproducibility in mind. At every step, starting from configuration
generation (which is simply a genrule in our case) we had to inspect and
adjust produced outputs in order to make sure that they do not include any
volatile data that could compromise reproducibility. The key output in the
Coverity workflow, the emit-db database, contained a number of pieces of
volatile information:
cov-emit invocations.COV_HOST
environment variable.FileName table varies with the depth of the path to the execroot,
breaking hermeticity. Deleting entries is not viable since their IDs are
referenced elsewhere. Our solution was to identify the variable prefix leading
to the execroot and reset all segments in that prefix to a fixed string. The
prefix length proved to be constant for each execution mode, allowing us to use
--strip-path arguments in cov-analyze to remove them during analysis.include directories would be added
to the database with altered Coverity-generated contents
that would also include absolute paths.We had to meticulously overwrite all of these, which was only possible
because emit-db is in the SQLite format and there is open source tooling
that makes it possible to edit it. If the output of cov-emit were in a
proprietary format we almost certainly wouldn’t be able to deliver as
efficient a solution for our client.
In practice, normalization of emit-db happens in two stages:
sqldiff utility which can print differences in schema and data between
tables..dump command which exports the
SQL statements necessary to recreate the database with the same schema and
data. Then we re-load these statements and thus obtain a binary database file
that is bit-by-bit reproducible. This is necessary because simply editing
a database by running SQL commands on it does not ensure that the result
is binary reproducible even if there is no difference in the actual
contents.Since emit-dbs are considerably larger than typical object files, we found
it highly desirable to use compression for individual SQLite databases, both
for those that result from initial cov-translate invocations and for
merged databases that are created by cov-manage-emit in the linking step.
Zstandard proved to be a good choice for that—the utility is both
fast and makes our build outputs up to 4 times smaller. Without compression,
we risked filling the remote cache quickly; besides, the bigger the files,
the slower I/O operations are.
We were tempted to minimize the size of the database even further by
exploring if there’s anything in emit-db that can be safely removed
without affecting our client’s use case. Alas, every piece of information
stored was required by Coverity during the analysis phase and our attempts
to truncate some of the tables led to failures in cov-analyze. It is worth
noting that the sqlite3_analyzer utility tool (part of the SQLite project)
can be used to produce a report that explains which objects store most data.
This way we found that there is an index that contributes about 20% of the
database size, however, deleting it severely degrades the performance of
record inserts which is a key operation during merging of emit-dbs.
Linking steps, which in our approach amount to merging of emit-db
databases, produce particularly large files. In order
to reduce the amount of I/O we perform and avoid
filling the remote cache too quickly,
we’ve marked all operations that deal with these large files
as no-remote. This is accomplished with this line in
our .bazelrc file:
common:coverity --modify_execution_info=CppArchive=+no-remote,CppLink=+no-remote,CcStrip=+no-remote
# If you wish to disable RE for compilation actions with coverity, uncomment
# the following line:
# common:coverity --modify_execution_info=CppCompile=+no-remote-execOn the other hand, we did end up running CppCompile actions with remote execution (RE)
because it proved to be twice faster than running them on CI agents. Making
RE possible required us to identify the exact collection of files from the
Coverity installation that are required during invocations of the Coverity
tooling. Once we observed RE working correctly, we were confident that the
Bazel definitions we use are hermetic.
Merging of individual emit-db databases found in the final bundle (i.e.
after the build has finished) proved to be time-consuming. This operation
cannot be parallelized since database information cannot be written in
parallel. The time required for this step grows linearly with the number of
translation units (TUs) being inserted, therefore it makes sense to pick the
largest database and then merge smaller ones into it. One could entertain
the possibility of skipping merging altogether and instead running smaller
analyses on individual emit-dbs, but this seems to be not advisable, since
Coverity performs a whole-program analysis, and thus it would lose valuable
information that way. For example, one TU may be exercised in different ways
by two different applications and the analysis results for this TU cannot be
correctly merged.
The analysis phase is a black box, and it can easily become the bottleneck
of the entire workflow, thus making it impractical for running in merge
request pipelines. A common solution for speeding up the analysis in merge
request pipelines is to identify files that were edited and limit the
analysis to only these files with the --tu-pattern option, which supports
a simple language for telling Coverity what to care
about during analysis. We added support for this approach to our solution by
automatically finding the files changed in the current merge request, and
passing these on to --tu-pattern. This restricted analysis still requires the
emit-dbs for the entire project, but most of them will be cached.
The solution that we delivered is in the form of a bazel run-able target
that depends on the binary bundle that needs to be analyzed. It can be
invoked like this:
bazel run //bazel/toolchains/coverity:workflow --config=coverity -- ...This solution can be used both for the nightly runs of Coverity and in the merge request pipelines. We have confirmed that the results that are produced by our solution match the findings of Coverity when it is run in the “traditional” way. A typical run in a merge request pipeline takes about 22 minutes when a couple of C++ files are edited. The time is distributed as follows:
emit-dbs--tu-pattern).The execution time can grow, of course, if the edits are more substantial. The key benefit of our approach is that the Coverity build is now cacheable and therefore can be included in merge request CI pipelines.
In summary, integrating Coverity static analysis with Bazel in a cacheable,
reproducible, and efficient manner required a deep understanding of both
Bazel and Coverity, as well as a willingness to address the nuances of
proprietary tooling that got in the way. By leveraging granular emit-db
databases, normalizing volatile data, and optimizing for remote execution
and compression, we were able to deliver a solution that fits well into the
client’s CI workflow and supports incremental analysis in merge request
pipelines.
While the process involved overcoming significant challenges, particularly around reproducibility and performance, the resulting workflow enables fast static analysis without sacrificing the benefits of Bazel’s remote cache. We hope that sharing our approach will help other teams facing similar challenges and inspire improvements when integrating other static analysis tools with Bazel.
I have thought about distilling the principles by which I program Haskell, and how I’ve been able to steer long-lived projects over years of growth, refactorings, and changes in demands. I find myself coming back to a few distinct and helpful “points” (“doctrines”, if you may allow me to say) that have yet to lead me astray.
With a new age of software development coming, what does it even mean to write good, robust, correct code? It is long overdue to clarify the mindset we use to define “good” coding principles.
In this series, Five-Point Haskell, I’ll set out to establish a five-point framework for typed functional programming (and Haskell-derived) design that aims to produce code that is maintainable, correct, long-lasting, extensible, and beautiful to write and work with. We’ll reference real-world case studies with actual examples when we can, and also attempt to dispel thought-leader sound bites that have become all too popular on Twitter (“heresies”, so to speak).
Let’s jump right into point 1: the doctrine of Total Depravity, and why Haskell is perfectly primed to make living with it as frictionless as possible.
Total Depravity: If your code’s correctness depends on keeping complicated interconnected structure in your head, a devastating incident is not a matter of if but when.
Therefore, delegate these concerns to tooling and a sufficiently powerful compiler, use types to guard against errors, and free yourself to only mentally track the actual important things.
Think about the stereotype of a “brilliant programmer” that an inexperienced programmer has in their mind — someone who can hold every detail of a complex system in their head, every intricate connection and relationship between each component. There’s the classic Monkey User Comic that valorizes this ideal.

The 10x developer is one who can carry the state and interconnectedness of an entire system in their brain, and the bigger the state they can carry, the more 10x they are.
This is the myth of the hero programmer. Did you have a bug? Well, you just need to upgrade your mental awareness and your context window. You just need to be better and better at keeping more in your mind.
Actually addressing these issues in most languages requires a lot of overhead and clunkiness. But luckily we’re in Haskell.
The 2022 Atlassian Outage, in part, was the result of passing the wrong type of ID. The operators were intended to pass App IDs, but instead passed Site IDs, and the errors cascaded from there. It goes without saying that if you have a bunch of “naked” IDs, then mixing them up is eventually going to backfire on you.
newtype Id = Id String
type SiteId = Id
type AppId = Id
getApps :: SiteId -> IO [AppId]
deleteSite :: SiteId -> IO ()
deleteApp :: AppId -> IO ()This is convenient because you get functions for all IDs without any extra work. Let’s say you want to serialize/print or deserialize/read these IDs — it can be helpful to give them all the same type so that you can write this logic in one place.
instance ToJSON Id where
toJSON (Id x) = object [ "id" .= x ]
instance FromJSON Id where
parseJSON = withObject "Id" $ \v ->
Id <$> (v .: "id")Convenient and effective, as long as you never accidentally use a
SiteId as an AppId or vice versa. And this is a very
easy delusion to fall into, if you don’t believe in total depravity. However,
sooner or later (maybe in a week, maybe in a year, maybe after you onboard that
new team member)…someone is going to accidentally pass a site ID where an app ID
is expected.
And at that point it’s all over.
Knowing this can happen, we can add a simple newtype wrapper so that accidentally using the wrong ID is a compile error:
And now such a mis-call will never compile! Congratulations!
We do have a downside now: we can no longer write code polymorphic over IDs when we want to. In the untagged situation, we could only write polymorphic code, and in the new situation we can only write code for one ID type.
instance FromJSON SiteId where
parseJSON = withObject "Id" $ \v -> do
tag <- v .: "type"
unless (tag == "Site") $
fail "Parsed wrong type of ID!"
SiteId <$> (v .: "id")
instance ToJSON SiteId where
toJSON (SiteId x) = object [ "type" .= "Site", "id" .= x ]
instance FromJSON AppId where
parseJSON = withObject "Id" $ \v -> do
tag <- v .: "type"
unless (tag == "App") $
fail "Parsed wrong type of ID!"
AppId <$> (v .: "id")
instance ToJSON AppId where
toJSON (AppId x) = object [ "type" .= "App", "id" .= x ]However, luckily, because we’re in Haskell, it’s easy to get the best of both worlds with phantom types (that don’t refer to anything inside the actual data representation):
data Id a = Id { getId :: String }
data Site
data App
type SiteId = Id Site
type AppId = Id App
-- using Typeable for demonstration purposes
instance Typeable a => ToJSON (Id a) where
toJSON (Id x) = object
[ "type" .= show (typeRep @a)
, "id" .= x
]
instance Typeable a => FromJSON (Id a) where
parseJSON = withObject "Id" $ \v -> do
tag <- v .: "type"
unless (tag == show (typeRep @a)) $
fail "Parsed wrong type of ID!"
Id <$> (v .: "id")Type safety doesn’t necessarily mean inflexibility!
Phantom types give us a lot of low-hanging fruit for preventing inadvertent misuse.
The 2017 DigitalOcean outage, for example, was partially about the wrong environment credentials being used.
We could imagine a test harness that clears a test database using postgresql-simple:
-- | Warning: do NOT call this outside of test environment!
clearTestEnv :: Connection -> IO ()
clearTestEnv conn = do
putStrLn "Are you sure you read the warning on this function? Well, too late now!"
_ <- execute_ conn "DROP TABLE IF EXISTS users CASCADE"
putStrLn "Test data wiped."However, somewhere down the line, someone is going to call
clearTestEnv deep inside a function inside a function
inside a function, which itself is called against the prod database. I guarantee
it.
To ensure this never happens, we can use closed phantom types using
DataKinds (made nicer with TypeData post-GHC 9.6):
-- type data = declare a closed kind and two type constructors at the type level using -XTypeData
type data Env = Prod | Test
newtype DbConnection (a :: Env) = DbConnection Connection
runQuery :: DbConnection a -> Query -> IO Int64
runQuery (DbConnection c) q = execute_ c q
-- | Warning: Did you remember to charge your chromebook? Oh and this function
-- is safe by the way.
clearTestEnv :: DbConnection Test -> IO ()
clearTestEnv conn = do
_ <- runQuery conn "DROP TABLE IF EXISTS users CASCADE"
putStrLn "Test data wiped."
connectProd :: IO (DbConnection Prod)
connectProd = DbConnection <$> connectPostgreSQL "host=prod..."Now, if you create a connection using connectProd, you can use
runQuery on it (because it can run any
DbConnection a)…but if any sub-function of a sub-function calls
clearTestEnv, it will have to unify with
DbConnection Test, which is impossible for a prod connection.
This is somewhat similar to using “mocking-only” subclasses for dependency injection, but with a closed universe. I discuss patterns like this in my Introduction to Singletons series.
And sometimes, phantom types can do the work for you, not only preventing mix-ups but also encoding business logic in their manipulation.
Take, for instance, the Mars Climate Orbiter failure, where the software module provided by Lockheed Martin expected US Customary Units, and another one developed by NASA expected SI units.
If I had a function like:
-- | In Newton-seconds
myMomentum :: Double
myMomentum = 20
-- | In Pounds-second
myImpulse :: Double
myImpulse = 4
-- | Make sure these are both the same units!
applyImpulse :: Double -> Double -> Double
applyImpulse currentMomentum impulse = currentMomentum + impulseThis is just asking for someone to come along and provide newtons alongside pounds. It isn’t even clear from the types what is expected!
We can instead use the dimensional library:
import qualified Numeric.Units.Dimensional.Prelude as U
import Numeric.Units.Dimensional ((*~))
import Numeric.Units.Dimensional.SIUnits
import Numeric.Units.Dimensional.NonSI
myMomentum :: Momentum
myMomentum = 20 *~ (newton U.* seconds)
myImpulse :: Impulse
myImpulse = 4 *~ (poundForce U.* seconds)
-- Verify at compile-time that we can use '+' with Momentum and Impulse
applyImpulse :: Momentum -> Impulse -> Momentum
applyImpulse currentMomentum impulse = currentMomentum + impulseNow as long as momentum and impulse are provided in the correct types at API
boundaries, no mix-up will happen. No need to send 300 million dollars down the
drain! Libraries will just need to provide a unified Momentum or
Impulse type, and everything will work out.
Speaking of costly errors, there is one extremely egregious pattern that is so pervasive, so alluring, and yet so inevitably devastating, it has been dubbed the “Billion Dollar Mistake”. It’s the idea of a sentinel value, or in-band signaling.
There are examples:
String.indexOf(), str.find(), etc. in many
languages return -1 if the substring is not foundfgetc(), getchar(), return -1 for
EOF. And if you cast to char, you basically can’t
distinguish EOF from 0xff (ÿ).malloc() returning the pointer 0 means not enough memoryNULL pointer value as well — or
even a value null that can be passed in for any expected type or
object or value.parseInt returns not null, but rather
NaN for a bad parse — giving two distinct sentinel values"" for
non-presence-999 for a bad
reading…but sometimes -999 might actually be a valid value!It should be evident that these are just accidents and ticking time bombs waiting to happen. Some caller just needs to forget to handle the sentinel value, or to falsely assume that the sentinel value is impossible to occur in any situation.
It’s called the billion dollar mistake, but it’s definitely arguable that the cumulative damage has been much higher. High-profile incidents include sock_sendpage and the 2025 GCP outage, but if you’re reading this and you are honest with yourself, it’s probably happened to you multiple times and has been the source of many frustrating bug hunts.
There’s also CVE-2008-5077,
because EVP_VerifyInit
returns 0 for false, 1 for true, and -1
for error! So some OpenSSL code did a simple if-then-else check
(result != 0) and treated error and true the same way. Whoops.
Why do we do this to ourselves? Because it is convenient. In the case of
EVP_VerifyInit, we can define an enum instead…
However, it’s not easy to make an “integer or not found” type in C or
JavaScript without some sort of side-channel. Imagine if JavaScript’s
String.indexOf() instead expected continuations on success and
failure and became much less usable as a result:
unsafeIndexOf :: String -> String -> Int
-- vs.
-- takes a success continuation and a failure continuation
indexOf :: String -> String -> (Int -> r) -> (() -> r) -> rAll of this just to fake having actual sum types.
We don’t really have an excuse in Haskell, since we can just return
Maybe:
Returning Maybe or Option forces the caller to
handle:
and this handling is compiler-enforced. Provided, of course, you don’t intentionally throw
away your type-safety and compiler checks for no reason. You can even return
Either with an enum for richer responses, and very easily chain
erroring operations using Functor and Monad. In fact, with cheap ADTs, you
can define your own rich result type, like in unix’s
ProcessStatus:
Imagine trying to cram all of that information into an int!
Assumptions kill, and a lot of times we arrive at implicit assumptions in our code. Unfortunately, even if we add these assumptions in our documentation, it only takes a minor refactor or lapse in memory for these to cause catastrophic incidents.
There are the simple cases — consider a mean function:
-- | Warning: do not give an empty list!
mean :: [Double] -> Double
mean xs = sum xs / fromIntegral (length xs)But are you really going to remember to check if your list is empty
every time you give it to mean? No, of course not.
Instead, make it a compiler-enforced constraint.
Now mean takes a NonEmpty list, which can only be
created safely using nonEmpty :: [a] -> Maybe (NonEmpty a)
(where the caller has to explicitly handle the empty list case, so they’ll never
forget) or from functions that already return NonEmpty by default
(like some :: f a -> f (NonEmpty a) or
group :: Eq a => [a] -> [NonEmpty a]), allowing you to
beautifully chain post-conditions directly into pre-conditions.
Accessing containers is, in general, very fraught…even things like indexing lists can send us into a graveyard spiral. Sometimes the issue is more subtle. This is our reminder to never let these implicit assumptions go unnoticed.
“Shotgun parsing” involves mixing validated and unvalidated data at different levels in your program. Oftentimes it is considered “fine” because you just need to remember which inputs are validated and which aren’t…right? In truth, all it takes is a simple temporary lapse of mental model, a time delay between working on code, or uncoordinated contributions before things fall apart.
Consider a situation where we validate usernames only on write to the database.
validUsername :: String -> Bool
validUsername s = all isAlphaNum s && all isLower s
-- | Returns 'Nothing' if username is invalid or insertion failed
saveUser :: Connection -> String -> IO (Maybe UUID)
saveUser conn s
| validUsername s = do
newId <- query conn "INSERT INTO users (username) VALUES (?) returning user_id" (Only s)
pure $ case newId of
[] -> Nothing
Only i : _ -> Just i
| otherwise = pure Nothing
getUser :: Connection -> UUID -> IO (Maybe String)
getUser conn uid = do
unames <- query conn "SELECT username FROM users where user_id = ?" (Only uid)
pure $ case unames of
[] -> Nothing
Only s : _ -> Just sIt should be fine as long as you only ever use saveUser
and getUser…and nobody else has access to the database. But, if
someone hooks up a custom connector, or does some manual modifications, then the
users table will now have an invalid username, bypassing Haskell.
And because of that, getUser can return an invalid string!
Don’t assume that these inconsequential slip-ups won’t happen; assume that it’s only a matter of time.
Instead, we can bake the state of a validated string into the type itself:
newtype Username = UnsafeUsername String
deriving (Show, Eq)
-- | Our "Smart Constructor"
mkUsername :: String -> Maybe Username
mkUsername s
| validUsername s = Just (UnsafeUsername s)
| otherwise = Nothing
-- | Access the raw string if needed
unUsername :: Username -> String
unUsername (UnsafeUsername s) = sUsername and String themselves are not structurally
different — instead, Username is a compiler-enforced tag specifying
it went through a specific required validation function within Haskell,
not just externally verified.
Now saveUser and getUser are safe at the
boundaries:
saveUser :: Connection -> Username -> IO (Maybe UUID)
saveUser conn s = do
newId <- query conn "INSERT INTO users (username) VALUES (?) returning user_id" (Only (unUsername s))
pure $ case newId of
[] -> Nothing
Only i : _ -> Just i
getUser :: Connection -> UUID -> IO (Maybe Username)
getUser conn uid = do
unames <- query conn "SELECT username FROM users where user_id = ?" (Only uid)
pure $ case unames of
[] -> Nothing
Only s : _ -> mkUsername s(In real code, of course, we would use a more usable indication of failure
than Maybe)
We can even hook this into Haskell’s typeclass system to make this even more
rigorous: Username could have its own FromField and
ToField instances that push the validation to the driver level.
instance FromField Username where
fromField f mdata = do
s :: String <- fromField f mdata
case mkUsername s of
Just u -> pure u
Nothing -> returnError ConversionFailed f ("Invalid username format: " ++ s)
instance ToField Username where
toField = toField . unUsername
saveUser :: Connection -> Username -> IO (Maybe UUID)
saveUser conn s = do
newId <- query conn "INSERT INTO users (username) VALUES (?) returning user_id" (Only s)
pure $ case newId of
[] -> Nothing
Only i : _ -> Just i
getUser :: Connection -> UUID -> IO (Maybe Username)
getUser conn uid = do
unames <- query conn "SELECT username FROM users where user_id = ?" (Only uid)
pure $ case unames of
[] -> Nothing
Only s : _ -> Just sPushing it to the driver level will also unify everything with the driver’s error-handling system.
These ideas are elaborated further in one of the best Haskell posts of all time, Parse, Don’t Validate.
At the heart of it, the previous examples’ cardinal sin was “boolean
blindness”. If we have a predicate like
validUsername :: String -> Bool, we will branch on that
Bool once and throw it away. Instead, by having a function like
mkUsername :: String -> Maybe Username, we keep the
proof alongside the value for the entire lifetime of the value. We basically
pair the string with its proof forever, making them inseparable.
There was another example of such a thing earlier: instead of using
null :: [a] -> Bool and gating a call to mean with
null, we instead use
nonEmpty :: [a] -> Maybe (NonEmpty a), and pass along the proof
of non-emptiness alongside the value itself. And, for the rest of that list’s
life, it will always be paired with its non-emptiness proof.
Embracing total depravity means always keeping these proofs together, with the witnesses bundled with the value itself, because if you don’t, someone is going to assume it exists when it doesn’t, or drop it unnecessarily.
Boolean blindness also has another facet, which is where Bool
itself is not a semantically meaningful type. This is “semantic boolean
blindness”.
The classic example is
filter :: (a -> Bool) -> [a] -> [a]. It might sound silly
until it happens to you, but it is pretty easy to mix up if True
means “keep” or “discard”. After all, a “water filter” only lets water through,
but a “profanity filter” only rejects profanity. Instead, how about
mapMaybe :: (a -> Maybe b) -> [a] -> [b]? In that case, it
is clear that Just results are kept, and the Nothing
results are discarded.
Sometimes, the boolean is ambiguous as to what it means. You can sort of interpret the 1999 Mars Polar Lander crash this way. Its functions took a boolean based on the state of the legs:
and True and False were misinterpreted. Instead,
they could have considered semantically meaningful types: (simplified)
Note that Maybe itself is not immune from “semantic blindness” —
if you find yourself using a lot of anonymous combinators like
Maybe and Either to get around boolean blindness, be
aware of falling into algebraic
blindness!
Clean-up of finite system resources is another area that is very easy to assume you have a handle on before it gets out of hand and sneaks up on you.
process :: Handle -> IO ()
doTheThing :: FilePath -> IO ()
doTheThing path = do
h <- openFile path ReadMode
process h
hClose hA bunch of things could go wrong —
hClose a file handle, and if your
files come at you dynamically, you’re going to run out of file descriptors, or
hold on to locks longer than you shouldprocess throws an exception, we never get to
hClose, and the same issues happenThe typical solution that other languages (like Python, modern Java) take is
to put everything inside a “block” where quitting the block guarantees the
closure. In Haskell we have the bracket pattern:
-- strongly discourage using `openFile` and `hClose` directly
withFile :: FilePath -> (Handle -> IO r) -> IO r
withFile path = bracket (openFile path ReadMode) hClose
doTheThing :: FilePath -> IO ()
doTheThing path = withFile path $ \h -> do
process hIf you never use openFile directly, and always use
withFile, all file usage is safe!
But, admittedly, continuations can be annoying to work with. For example, what if you wanted to safely open a list of files?
All of a sudden, not so fun. And what if you had, for example, a Map of
files, like Map Username FilePath?
processAll :: Map Username Handle -> IO ()
doTheThings :: Map Username FilePath -> IO ()
doTheThings paths = -- uh...In another language, at this point, we might just give up and resort to manual opening and closing of files.
But this is Haskell. We have a better solution: cleanup-tracking monads!
This is a classic usage of ContT to let you chain bracket-like
continuations:
processTwo :: Handle -> Handle -> IO ()
doTwoThings :: FilePath -> FilePath -> IO ()
doTwoThings path1 path2 = evalContT $ do
h1 <- ContT $ withFile path1
h2 <- ContT $ withFile path2
liftIO $ processTwo h1 h2
processAll :: Map Username Handle -> IO ()
doTheThings :: Map Username FilePath -> IO ()
doTheThings paths = evalContT $ do
handles <- traverse (ContT . withFile) paths
liftIO $ processAll handlesHowever, using ContT doesn’t allow you to do things like early
cleanups or canceling cleanup events. It forces us into a last-in, first-out
sort of cleanup pattern. If you want to deviate, this might cause you to, for
convenience, go for manual resource management. However, we have tools for more
fine-grained control, we have things like resourcet
ResourceT, which lets you manually control the order of clean-up
events, with the guarantee that all of them eventually happen.
import qualified Data.Map as M
-- | Returns set of usernames to close
processAll :: Map Username Handle -> IO (Set Username)
allocateFile :: FilePath -> ResourceT IO (ReleaseKey, Handle)
allocateFile fp = allocate (openFile fp ReadMode) hClose
-- Guarantees that all handles will eventually close, even if `go` crashes
doTheThings :: Map Username FilePath -> IO ()
doTheThings paths = runResourceT $ do
releasersAndHandlers <- traverse allocateFile paths
go releasersAndHandlers
where
-- normal operation: slowly releases handlers as we drop them
go :: Map Username (ReleaseKey, Handle) -> ResourceT IO ()
go currOpen = do
toClose <- liftIO $ processAll (snd <$> currOpen)
traverse_ (release . fst) (currOpen `M.restrictKeys` toClose)
let newOpen = currOpen `M.withoutKeys` toClose
unless (M.null newOpen) $
go newOpenHere we get the best of both worlds: the ability to manually close handlers when they are no longer needed, but also the guarantee that they will eventually be closed.
Hopefully these examples, and similar situations, should feel relatable. We’ve all experienced the biting pain of too much self-trust. Or, too much trust in our ability to communicate with team members. Or, too much trust in ourselves 6 months from now. The traumas described here should resonate with you if you have programmed in any capacity for more than a couple of scripts.
The doctrine of total depravity does not mean that we don’t recognize the ability to write sloppy code that works, or that flow states can enable some great feats. After all, we all program with a certain sense of imago machinae. Instead, it means that all such states are fundamentally unstable in their nature and will always fail at some point. The “total” doesn’t mean we are totally cooked, it means this eventual reckoning applies to all such shortcuts.
The problem won’t be solved by “get good”. The problem is solved by utilizing the tooling we are given, especially since Haskell makes them so accessible and easy to pull in.
There’s another layer here that comes as a result of embracing this mindset: you’ll find that you have more mental space to dedicate to things that actually matter! Instead of worrying about inconsequential minutiae and details of your flawed abstractions, you can actually think about your business logic, the flow of your program, and architecting that castle of beauty I know you are capable of.
Before we end, let’s address the elephant in the room. We’re writing this in 2026, in the middle of one of the biggest revolutions in software engineering in the history of the field. A lot of people have claimed that types and safety are now no longer important in the age of LLMs and agentic coding.
However, these claims seem to miss the fact that the fundamental issue being addressed here exists both in LLMs and humans: the limited “context window” and attention. Humans might be barely able to keep a dozen things in our heads, LLMs might be able to keep a dozen dozen things, but it will still be ultimately finite. So, the more we can move concerns out of our context window (be it biological or mechanical), the less crowded our context windows will be, and the more productive we will be.
Agentic coding is progressing quickly, and over the past few months I have been exploring this a lot, using models hands-on. One conclusion I have found (and, this agrees with everyone else I’ve asked who has been trying the same thing) is that Haskell’s types, in many ways, are the killer productivity secret of agentic coding.
Many of my Haskell coding tasks for an LLM agent often involve:
ghci and cabal.And, this isn’t 100% effective, but from personal experience it is much more effective than the similar situation without typed guardrails for fast feedback, and without instant compiler feedback. The feedback loop is tighter, the objectives clearer, the constraints more resilient, the tooling more utilized.
I have noticed, also, that my LLM agents often check the types of the APIs
using ghci :type, and rarely the documentation of the functions
using ghci :docs. So, any “documentation-based contracts” are
definitely much more likely to explode in your face in this new world than
type-based contracts.
I’m not sure how quickly LLM-based agentic coding will progress, but I am sure that the accidental “dropping” of concerns will continue to be a bottleneck. All of the traits described in this post for humans will continue to be traits of limited context windows for LLMs.
If anything, limited “brain space” might be the bottleneck, for both humans and LLMs. If provide LLMs with properly “depravity-aware” typed code (and encourage them to write it by giving them the right iterative tooling), I truly believe that we have the key to unlocking the full potential of agentic coding.
And…not whatever this tweet is.
Total depravity is all about using types to prevent errors. However, you can only go so far with defensive programming and carefully picking the structure of your types. Sometimes, it feels like you are expending a lot of energy and human effort just picking the perfectly designed data type, only for things out of your hand to ruin your typed castle.
In the next chapter, we’ll see how a little-discussed aspect of Haskell’s type system gives you a powerful tool for opening your mind to new avenues of design that were impossible before. At the same time, we’ll see how we can leverage universal properties of mathematics itself to help us analyze our code in unexpected ways.
Let’s explore this further in the next principle of Five-Point Haskell, Unconditional Election!
I am very humbled to be supported by an amazing community, who make it possible for me to devote time to researching and writing these posts. Very special thanks to my supporter at the “Amazing” level on patreon, Josh Vera! :)
Also thanks to jackdk’s comment for highlighting extra resources and context that I believe are very useful and relevant!
Today I’m announcing and open-sourcing the Bombadil project — a brand new property-based browser testing framework. I started working on this when joining Antithesis two months ago. While still in its infancy, we’ve decided to build it in the open and share our progress from the start.
We decided on the name Bombadil last week. A few days later, this exploded:
It's going to be tough for startups when all the Lord of the Rings names are taken and the only thing left is something like Bombadil AI.
— Patrick Collison (@patrickc) January 25, 2026
While Quickstrom proved its worth, finding bugs in more than half of the TodoMVC apps, Bombadil aims to improve on its shortcomings while also envisioning a more ambitious future for generative testing of web apps: faster and smarter state space exploration, a modern and usable specification language, better tools for reproducing and debugging test failures, and a better distribution story.
I consider Bombadil the successor of Quickstrom. After years of trying to sustain Quickstrom through various models, I now have a much better answer: building it at Antithesis, making something valuable that is open and free to use, while also strengthening the company’s commercial offering. Bombadil can be used locally or in CI to test your web apps early. Power users can take it further and run Bombadil within Antithesis and its deterministic hypervisor. That gives you perfect reproductions of failed tests. You can even combine Bombadil with other workloads in Antithesis and test your entire stack deterministically. Isn’t that the holy grail of testing?
Bombadil is built from scratch with a focus on accessibility: a new specification language and better tooling for writing and maintaining specs. Right now, I’m working on a specification DSL in TypeScript. It’s based on linear temporal logic, just as Quickstrom, but aims to be a lot more ergonomic. Here’s an example that verifies that error messages eventually disappear:
const errorMessage = extract( (state) => state.document.body.querySelector(".error") ?.textContent ?? null ); export const errorEventuallyDisappears = always( condition(() => errorMessage !== null).implies( eventually(() => errorMessage === null) .within(5, "seconds") ) );Both the original hacky PureScript DSL and the bespoke language Specstrom were huge obstacles to adoption. Today, TypeScript is a widely adopted language among quality-minded web developers, and if you’re not into that, Bombadil will work with plain JavaScript too.
We’re writing Bombadil in Rust, leveraging its excellent ecosystem to ship a single statically-linked executable — download for your platform, point it at a Chromium-based browser, and off you go!
Bombadil is early but usable. Check it out on GitHub, try it on your projects, and let us know what breaks. Also let us know what it breaks in your systems! Join us on Discord for help and discussion, or follow development on Twitter/X. This is just the beginning — we’re actively seeking feedback and early adopters to help shape where this goes.
Welcome to the Haskell Interlude. Today, Matti and Mike talk to
Jeffrey Young. Jeff has had a long history of working with Haskell and
on ghc itself. We talk about what makes Haskell so compelling, the
good and bad of highly optimized code and the beauty of
well-modularized code, how to get into compiler development, and how
to benefit from Domain-Driven Design.
Jeff is currently on the job market - if you want to get in touch,
email him at mailto:jmy6342@gmail.com.
Since the switching to eglot I've ended up making a few related changes.
Since eglot it's written to work with other packages in core, which means it
integrates with flymake. The switch comprised
:ensure nil to make sure elpaca knows there's nothing to download.flymake-mode to prog-mode-hook.The two functions for toggling showing diagnostics look like this
(defun mes/toggle-flymake-buffer-diagnostics ()
(interactive)
(if-let* ((window (get-buffer-window (flymake--diagnostics-buffer-name))))
(save-selected-window (quit-window nil window))
(flymake-show-buffer-diagnostics)))
(defun mes/toggle-flymake-project-diagnostics ()
(interactive)
(if-let* ((window (get-buffer-window (flymake--project-diagnostics-buffer (projectile-project-root)))))
(save-selected-window (quit-window nil window))
(flymake-show-project-diagnostics)))
And the changed keybindings are
| flycheck | flymake |
|---|---|
| flycheck-next-error | flymake-goto-next-error |
| flycheck-previous-error | flymake-goto-prev-error |
| mes/toggle-flycheck-error-list | mes/toggle-flymake-buffer-diagnostics |
| mes/toggle-flycheck-projectile-error-list | mes/toggle-flymake-project-diagnostics |
with-eval-after-load instead of :after eglot
When it comes to use-package I keep on being surprised, and after the switch
to elpaca I've found some new surprises. One of them was that using :after
eglot like this
(use-package haskell-ng-mode
:afer eglot
:ensure (:type git
:repo "git@gitlab.com:magus/haskell-ng-mode.git"
:branch "main")
:init
(add-to-list 'major-mode-remap-alist '(haskell-mode . haskell-ng-mode))
(add-to-list 'eglot-server-programs '(haskell-ng-mode "haskell-language-server-wrapper" "--lsp"))
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:haskell
'(:formattingProvider "fourmolu"
:plugin (:stan (:global-on :json-false)))))
...
:hook
(haskell-ng-mode . eglot-ensure)
...)
would delay initialisation until after eglot had been loaded. However, it
turned out that nothing in :init ... seemed to run and upon opening a haskell file
no mode was loaded.
After a bit of thinking and tinkering I got it working by removing :after
eglot and using with-eval-after-load
(use-package haskell-ng-mode
:ensure (:type git
:repo "git@gitlab.com:magus/haskell-ng-mode.git"
:branch "main")
:init
(add-to-list 'major-mode-remap-alist '(haskell-mode . haskell-ng-mode))
(with-eval-after-load 'eglot
(add-to-list 'eglot-server-programs '(haskell-ng-mode "haskell-language-server-wrapper" "--lsp"))
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:haskell
'(:formattingProvider "fourmolu"
:plugin (:stan (:global-on :json-false))))))
...
:hook
(haskell-ng-mode . eglot-ensure)
...)
That change worked for haskell, and it seemed to work for python too, but after a little while I realised that python needed a bit more attention.
The python setup looked like this
(use-package python
:init
(add-to-list 'major-mode-remap-alist '(python-mode . python-ts-mode))
(with-eval-after-load 'eglot
(assoc-delete-all '(python-mode python-ts-mode) eglot-server-programs)
(add-to-list 'eglot-server-programs
`((python-mode python-ts-mode) . ,(eglot-alternatives
'(("rass" "python") "pylsp")))))
...
:hook (python-ts-mode . eglot-ensure)
...)
and it worked all right, but then I visited the package (using elpaca-visit)
and realised that the downloaded package was all of emacs. That's a bit of
overkill, I'd say.
However, adding :ensure nil didn't have the expected effect of just using the
version that's in core. Instead the whole configuration seemed to never take
effect and again I was back to the situation where I had to jump to
python-ts-mode manually.
The documentation for use-package says that :init is for
Code to run before PACKAGE-NAME has been loaded.
but I'm guessing "before" isn't quite before enough. Then I noticed :preface
with the description
Code to be run before everything except
:disabled; this can be used to define functions for use in:if, or that should be seen by the byte-compiler.
and yes, "before everything" is early enough. The final python configuration looks like this
(use-package python
:ensure nil
:preface
(add-to-list 'major-mode-remap-alist '(python-mode . python-ts-mode))
:init
(with-eval-after-load 'eglot
(assoc-delete-all '(python-mode python-ts-mode) eglot-server-programs)
(add-to-list 'eglot-server-programs
`((python-mode python-ts-mode) . ,(eglot-alternatives
'(("rass" "python") "pylsp")))))
...
:hook (python-ts-mode . eglot-ensure)
...)
I'm still not sure I have the correct intuition about how to use use-package,
but hopefully it's more correct now than before. I have a growing suspicion
that use-package changes behaviour based on the package manager I use. Or
maybe it's just that some package managers make use-package more forgiving of
bad use.
I've been using lsp-mode since I switched to Emacs several years ago. When eglot
made into Emacs core I used it very briefly but quickly switched back. Mainly I
found eglot a bit too bare-bones; I liked some of the bells and whistles of
lsp-ui. Fast-forward a few years and I've grown a bit tired of those bells and
whistles. Specifically that it's difficult to make lsp-ui-sideline and
lsp-ui-doc work well together. lsp-ui-sidedline is shown on the right side,
which is good, but combining it with lsp-ui-doc leads to situations where the
popup covers the sideline. What I've done so far is centre the line to bring the
sideline text out. I was playing a little bit with making the setting of
lsp-ui-doc-position change depending on the location of the current position.
It didn't work that well though so I decided to try to find a simpler setup.
Instead of simplifying the setup of lsp-config I thought I'd give eglot
another shot.
I removed the statements pulling in lsp-mode, lsp-ui, and all
language-specific packages like lsp-haskell. Then I added this to configure
eglot
(use-package eglot
:ensure nil
:custom
(eglot-autoshutdown t)
(eglot-confirm-server-edits '((eglot-rename . nil)
(t . diff))))
The rest was mainly just switching lsp-mode functions for eglot functions.
| lsp-mode function | eglot function |
|---|---|
lsp-deferred |
eglot-ensure |
lsp-describe-thing-at-point |
eldoc |
lsp-execute-code-action |
eglot-code-actions |
lsp-find-type-definition |
eglot-find-typeDefinition |
lsp-format-buffer |
eglot-format-buffer |
lsp-format-region |
eglot-format |
lsp-organize-imports |
eglot-code-action-organize-imports |
lsp-rename |
eglot-rename |
lsp-workspace-restart |
eglot-reconnect |
lsp-workspace-shutdown |
eglot-shutdown |
I haven't verified that the list is fully correct yet, but it looks good so far.
The one thing I might miss is lenses, and using lsp-avy-lens. However,
everything that I use lenses for can be done using actions, and to be honest I
don't think I'll miss the huge lens texts from missing type annotations in
Haskell.
One good thing about lsp-mode's use of language-specific packages is that
configuration of the various servers is performed through functions. This makes
it easy to discover what options are available, though it also means not all
options may be available. In eglot configuration is less organised, I have to
know about the options for each language server and put the options into
eglot-workspace-configuration myself. It's not always easy to track down what
options are available, and I've found no easy way to verify the settings. For
instance, with lsp-mode I configures HLS like this
(lsp-haskell-formatting-provider "fourmolu")
(lsp-haskell-plugin-stan-global-on nil)
which translates to this for eglot
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:haskell
'(:formattingProvider "fourmolu"
:plugin (:stan (:global-on :json-false)))))
and I can verify that this configuration has taken effect because I know enough about the Haskell tools.
I do some development in Python and I used to configure pylsp like this
(lsp-pylsp-plugins-mypy-enabled t)
(lsp-pylsp-plugins-ruff-enabled t)
which I think translates to this for eglot
(setq-default eglot-workspace-configuration
(plist-put eglot-workspace-configuration
:pylsp
'(:plugins (:ruff (:enabled t)
:mypy (:enabled t)))))
but I don't know any convenient way of verifying these settings. I'm simply not
familiar enough with the Python tools. I can check the value of
eglot-workspace-configuration by inspecting it or calling
eglot-show-workspace-configuration but is there really no way of asking the
language server for its active configuration?
The last time I gave up on eglot very quickly, probably too quickly to be
honest. I made these changes to my configuration over the weekend, so the real
test of eglot starts when I'm back in the office. I have a feeling I'll stick
to it longer this time.
In the previous post, we added channels to Co, the small language we are implementing in this series of posts. In this post, we add the sleep primitive to it, enabling time-based coroutine scheduling. We then use sleep to build a simulation of digital logic circuits.
This post was originally published on abhinavsarkar.net.
This post is a part of the series: Implementing Co, a Small Language With Coroutines.
Sleep is a commonly used operation in concurrent programs. It pauses the execution of the current Thread of Computation (ToC) for a specified duration, after which the ToC is resumed automatically. Sleep is used for various purposes: polling for events, delaying execution of an operation, simulating latency, implementing timeouts, and more.
Sleep is generally implemented as a primitive operation in most languages, delegating the actual implementation to the underlying operating system. The operating system’s scheduler removes the ToC from the list of runnable ToCs, places it in a list of sleeping ToCs, and after the specified duration, moves it back to the list of runnable ToCs for scheduling.
Since Co implements its own ToC (coroutine) scheduler, we implement sleep as a primitive operation within the interpreter itself1.
We start by exposing sleep and getCurrentMillis as built-in functions to Co:
builtinEnv :: IO Env
builtinEnv = Map.fromList <$> traverse (traverse newIORef) [
("print", BuiltinFunction "print" 1 executePrint)
, ("newChannel",
BuiltinFunction "newChannel" 0 $ fmap Chan . const (newChannel 0))
, ("newBufferedChannel",
BuiltinFunction "newBufferedChannel" 1 executeNewBufferedChannel)
, ("sleep", BuiltinFunction "sleep" 1 executeSleep)
, ("getCurrentMillis",
BuiltinFunction "getCurrentMillis" 0 executeGetCurrentMillis)
]The sleep built-in function takes one argument—the duration in milliseconds to sleep for. The getCurrentMillis function returns the current time in milliseconds since the Unix epoch. Both of them delegate to the functions explained next.
executeSleep :: [Expr] -> Interpreter Value
executeSleep argEs = evaluate (head argEs) >>= \case
Num n | n >= 0 -> sleep n >> return Null
Num n -> throw $ "Sleep time must be non-negative: " <> show n
_ -> throw "sleep call expected a number argument"
executeGetCurrentMillis :: [Expr] -> Interpreter Value
executeGetCurrentMillis _ =
Num . fromIntegral . floor . (* 1000) <$> liftIO getPOSIXTimeThe executeSleep function evaluates its argument to a number, checks that it is non-negative, and then calls the sleep function in the Interpreter monad. executeGetCurrentMillis calls getPOSIXTime and returns the milliseconds wrapped as a Num.
The implementation of sleep is more involved than other built-in functions because it interacts with the coroutine scheduler. When a coroutine calls sleep, we want to suspend the coroutine, and schedule it to be resumed after the specified duration. There may be multiple coroutines in the sleep state at a time, and they must be resumed according to their wakeup time (time at which sleep was called + sleep duration), and not in any other order. To be efficient, it is also important that the scheduler does not poll repeatedly for new coroutines to wake up and run, but instead waits till the right time. These are the two requirements for our coroutine scheduler. And the solution is: delayed coroutines.
The coroutines we have implemented so far were scheduled to run immediately. To implement sleep, we extend the coroutine concept with Delayed Coroutines—coroutines that are scheduled to run at a specific future time.
data Coroutine a = Coroutine
{ corEnv :: Env
, corCont :: a -> Interpreter ()
, corReady :: MVar ()
}
newCoroutine :: Env -> (a -> Interpreter ()) -> Interpreter (Coroutine a)
newCoroutine env cont = do
ready <- newMVar ()
return $ Coroutine env cont readyNow the Coroutine data type holds an MVar to signal when the coroutine is ready to be run. The old-style coroutines that run immediately are created ready to run by the newCoroutine function. But delayed coroutines are different:
newDelayedCoroutine ::
Integer -> Env -> (a -> Interpreter ()) -> Interpreter (Coroutine a)
newDelayedCoroutine sleepMillis env cont = do
ready <- newEmptyMVar
void $ liftIO $ forkIO $ do
threadDelay $ fromIntegral sleepMillis * 1000
putMVar ready ()
return $ Coroutine env cont readyThe key difference from a regular coroutine is that the MVar used for signaling is created empty. We fork a thread2 that sleeps3 for the specified sleep duration, and then signals that the coroutine is ready to run by filling the MVar.
An MVar is a synchronization primitive4—essentially a mutable box that can hold a value or be empty. When we call takeMVar on an empty MVar, it blocks until another thread fills it. This is what makes it powerful for our use case: instead of the interpreter repeatedly polling the queue asking “is this coroutine ready yet?�, we let the interpreter wait on the MVar. The forked thread signals readiness at the right time by filling the MVar. The interpreter wakes up immediately—no wasted CPU cycles, no busy-waiting.
We already have a Queue of coroutines in our Interpreter. It is a min-priority queue sorted by timestamps, which we have been using as a FIFO queue till now. Now we use it for its real purpose: storing delayed coroutines sorted by their wakeup times.
type Queue a = IORef (PQ.MinPQueue TimeSpec a, TimeSpec)
newQueue :: MonadBase IO m => m (Queue a)
newQueue = do
now <- liftBase currentSystemTime
newIORef (PQ.empty, now)
queueSize :: MonadBase IO m => Queue a -> m Int
queueSize = fmap (PQ.size . fst) . readIORefThe queue also tracks the maximum wakeup time of all coroutines in the queue. This information is useful for calculating how long the interpreter should sleep before termination.
The core operations on the queue are:
enqueueAt :: TimeSpec -> a -> Queue a -> Interpreter ()
enqueueAt time val queue = atomicModifyIORef' queue $ \(q, maxWakeupTime) ->
(( PQ.insert time val q,
if time > maxWakeupTime then time else maxWakeupTime
), ())
enqueue :: a -> Queue a -> Interpreter ()
enqueue val queue = do
now <- currentSystemTime
enqueueAt now val queue
dequeue :: Queue a -> Interpreter (Maybe a)
dequeue queue = atomicModifyIORef' queue $ \(q, maxWakeupTime) ->
if PQ.null q
then ((q, maxWakeupTime), Nothing)
else let ((_, val), q') = PQ.deleteFindMin q
in ((q', maxWakeupTime), Just val)
currentSystemTime :: MonadIO m => m TimeSpec
currentSystemTime = liftIO $ getTime MonotonicWe saw the enqueue function earlier:
The
enqueueAtfunction enqueues the given value at the given time in the queue. Theenqueuefunction enqueues the value at the current time, thus scheduling it to run immediately.The
dequeuefunction dequeues the value with the lowest priority from the queue, which in this case, is the value that is enqueued first.The
currentSystemTimefunction returns the monotonically increasing current system time.
The dequeue function dequeues the coroutine with lowest priority, so if we use the wakeup time as priority, it will dequeue the coroutine that is to be run next. That works!
The enqueueAt function calculates and tracks the maximum wakeup times of the coroutines as well. Next, we implement the scheduling of delayed coroutines:
scheduleDelayedCoroutine :: TimeSpec -> Coroutine () -> Interpreter ()
scheduleDelayedCoroutine wakeupTime coroutine = do
State.gets isCoroutines >>= enqueueAt wakeupTime coroutineThe scheduleDelayedCoroutine function enqueues a coroutine in the interpreter coroutine queue with the specified wakeup time. We also improve the runNextCoroutine function to wait for the coroutine to be ready before running it.
runNextCoroutine :: Interpreter ()
runNextCoroutine =
State.gets isCoroutines >>= dequeue >>= \case
Nothing -> throwError CoroutineQueueEmpty
Just Coroutine {..} -> do
void $ takeMVar corReady
setEnv corEnv
corCont ()The takeMVar function call blocks till the thread that was forked when creating the coroutine wakes up and fills the corReady MVar. So we don’t have to poll the queue.
That’s all we have to do for having delayed coroutines.
With the infrastructure in place, the sleep function becomes straightforward:
sleep :: Integer -> Interpreter ()
sleep millis = do
now <- currentSystemTime
let wakeupTime = now + fromNanoSecs (fromIntegral millis * 1000000)
env <- State.gets isEnv
callCC $ \cont -> do
coroutine <- newDelayedCoroutine millis env cont
scheduleDelayedCoroutine wakeupTime coroutine
runNextCoroutineWhen a coroutine calls sleep, we capture the current environment and use callCC to capture the continuation—the code that should run after the sleep completes. We then create a new delayed coroutine with this continuation, schedule it for the future, and run the next coroutine in the queue. The scheduler machinery takes care of running the delayed coroutine at the right time.
We also modify the awaitTermination function from the previous post to handle delayed coroutines. It now sleeps till the last wakeup time before checking if the queue is empty:
awaitTermination :: Interpreter ()
awaitTermination = do
(coroutines, maxWakeupTime) <- readIORef =<< State.gets isCoroutines
dur <- calcSleepDuration maxWakeupTime
unless (PQ.null coroutines) $ if dur > 0
then sleep dur >> awaitTermination
else yield >> awaitTerminationNotice how we use the sleep function we just defined in awaitTermination. The calcSleepDuration function calculates how long to sleep before the last coroutine becomes ready:
calcSleepDuration :: TimeSpec -> Interpreter Integer
calcSleepDuration maxWakeupTime = do
now <- currentSystemTime
return $ 1 + fromIntegral (maxWakeupTime - now) `div` 1000000That’s all for sleeping. This may be too much to take in, so let’s go through some examples.
Sleep can be used for polling/waiting for events, delaying execution, simulating latency, implementing timeouts, and more. Let’s see some simple uses.
An interesting example of sleep is the infamous sleep sort, which sorts a list of numbers by spawning a coroutine for each number that sleeps for the duration of that number, then prints it:
function sleepSort(a, b, c, d, e) {
function printNum(num) {
sleep(num);
print(num);
}
spawn printNum(a);
spawn printNum(b);
spawn printNum(c);
spawn printNum(d);
spawn printNum(e);
}
sleepSort(5, 4, 3, 2, 1);Running this program prints what we expect:
1
2
3
4
5Don’t use sleepSort for sorting your numbers though. Moving on.
With sleep, we can implement JavaScript-like setTimeout and setInterval functions:
function setTimeout(callback, millis) {
spawn (function () { sleep(millis); callback(); })();
}
function hello() {
print("hello");
}
setTimeout(hello, 10000);The setTimeout function spawns a coroutine that sleeps for the specified duration and then calls the callback function.
function setInterval(callback, seconds) {
function run() {
callback();
setTimeout(run, seconds);
}
setTimeout(run, seconds);
}
var start = getCurrentMillis();
function tick(t) {
var now = getCurrentMillis();
print(t + " " + (now - start));
}
setInterval(function () { tick("tick"); }, 2000);
sleep(1000);
setInterval(function () { tick("tock"); }, 2000);The setInterval function repeatedly calls a callback at a fixed interval using setTimeout to reschedule itself. Running the above code prints alternating tick and tock every 1 second, forever:
tick 2005
tock 3008
tick 4009
tock 5009
tick 6015
tock 7013
tick 8017
tock 9019
tick 10020
tock 11021
tick 12021Notice that the scheduling is not accurate up to milliseconds, but only approximate.
As a more complex example of using sleep, we implement a simulator for digital logic circuits, from basic Logic gates to a Ripple carry adder. The idea is to model circuits as a network of wires and gates, where the wires carry digital signal values (0 or 1), and the logic gates transform input signals to output signals with a propagation delay.
The digital circuit simulation example is from the Wizard Book. Quoting an example:
An inverter is a primitive function box [logic gate] that inverts its input. If the input signal to an inverter changes to 0, then one inverter-delay later the inverter will change its output signal to 1. If the input signal to an inverter changes to 1, then one inverter-delay later the inverter will change its output signal to 0.
But first, we’ll need to make some lists.
We implement a simple cons list (a singly linked list) using a trick from the book itself:
function Cons(first, rest) {
return function (command) {
if (command == "first") { return first; }
if (command == "rest") { return rest; }
};
}
function Empty() { return null;}
function first(list) { return list("first"); }
function rest(list) { return list("rest"); }
function prepend(list, element) { return Cons(element, list); }Empty creates an empty list, and we grow the list by prepending an element to it by calling the prepend function. first returns the first element of a list, and rest returns the rest of them. Notice that a Cons cell is just a closure that holds references to its first and rest parameters, and returns a selector function to retrieve them.
Next, we define a helper function to call a list of actions, yielding after each one:
function callEach(actions) {
if (actions != Empty()) {
callEach(rest(actions));
first(actions)();
yield;
}
}A wire holds a mutable signal value and a list of actions to call when the signal changes:
function Wire() {
var signalValue = 0;
var actions = Empty();
return function (command) {
if (command == "get-signal") {
return signalValue;
}
if (command == "set-signal") {
return function (newValue) {
if (signalValue != newValue) {
signalValue = newValue;
callEach(actions);
}
};
}
if (command == "add-action") {
return function (action) {
actions = prepend(actions, action);
action();
};
}
return null;
};
}
function getSignal(wire) { return wire("get-signal"); }
function setSignal(wire, signal) { wire("set-signal")(signal); }
function addAction(wire, action) { wire("add-action")(action); }
function connect(a, b) {
function propagate() {
setSignal(b, getSignal(a));
}
addAction(a, propagate);
}A wire provides three operations:
get-signal: returns the current signal value.set-signal: sets a new signal value and calls all actions if the value changed.add-action: adds an action to be called when the signal changes, and calls it immediately.The connect function connects two wires, causing the signal from one to propagate to another.
First, we define the basic logic operations:
function and(a, b) {
if (a == 1) { if (b == 1) { return 1; } }
return 0;
}
function or(a, b) {
if (a == 1) { return 1; }
if (b == 1) { return 1; }
return 0;
}
function not(a) {
if (a == 1) { return 0; }
return 1;
}And a utility function to schedule a function to run after a delay:
With these building blocks, we define the logic gates. Each gate computes its output based on its inputs and schedules the output update after a propagation delay specific to the gate:
var andGateDelay = 300;
function AndGate(a, b, out) {
function compute() {
var newSignal = and(getSignal(a), getSignal(b));
runAfter(andGateDelay, function () { setSignal(out, newSignal); });
}
addAction(a, compute);
addAction(b, compute);
}
var orGateDelay = 500;
function OrGate(a, b, out) {
function compute() {
var newSignal = or(getSignal(a), getSignal(b));
runAfter(orGateDelay, function () { setSignal(out, newSignal); });
}
addAction(a, compute);
addAction(b, compute);
}
var notGateDelay = 200;
function NotGate(a, out) {
function compute() {
var newSignal = not(getSignal(a));
runAfter(notGateDelay, function () { setSignal(out, newSignal); });
}
addAction(a, compute);
}We add the compute action to each input wire, which runs when the input signals change, and sets the signal on the output wire after a delay.
Let’s test an And gate:
var input1 = Wire();
var input2 = Wire();
var output = Wire();
log(">> Setting up the probes");
addProbe("input1", input1);
addProbe("input2", input2);
addProbe("output", output);
log(">> Setting up the And gate");
AndGate(input1, input2, output);
log(">> Setting input1 to 1");
setSignal(input1, 1);
sleep(1000);
log(">> Setting input2 to 1");
setSignal(input2, 1);For probing, we define a helper that logs signal changes with milliseconds elapsed since start of the run:
var start = getCurrentMillis();
function log(msg) {
print("[" + (getCurrentMillis() - start) + "] " + msg);
}
function addProbe(label, wire) {
addAction(wire, function () {
log(label + ": " + getSignal(wire));
});
}The output:
[0] >> Setting up the probes
[0] input1: 0
[0] input2: 0
[0] output: 0
[0] >> Setting up the And gate
[0] >> Setting input1 to 1
[0] input1: 1
[1005] >> Setting input2 to 1
[1006] input2: 1
[1310] output: 1It works as expected. You can notice the sleep and the And gate delay in action.
Using the basic logic gates, next we build adders. A Half adder is a digital circuit that adds two bits:
 </noscript>
</noscript>
It has two input signals/bits Input1 and Input2, and two output bits Sum and Carry. We simply connect the And, Or and Not gates with input, output and intermediate wires in our code as shown in the diagram:
function HalfAdder(label, input1, input2, sum, carry) {
var a = Wire();
var b = Wire();
addProbe(label + "-a", a);
addProbe(label + "-b", b);
OrGate(input1, input2, a);
AndGate(input1, input2, carry);
NotGate(carry, b);
AndGate(a, b, sum);
}Nice and simple. Let’s test it:
var input1 = Wire();
var input2 = Wire();
var sum = Wire();
var carry = Wire();
log(">> Setting up the probes");
addProbe("input1", input1);
addProbe("input2", input2);
addProbe("sum", sum);
addProbe("carry", carry);
log(">> Setting up the half-adder");
HalfAdder("half-adder", input1, input2, sum, carry);
log(">> Setting input1 to 1");
setSignal(input1, 1);
sleep(1000);
log(">> Setting input2 to 1");
setSignal(input2, 1);And the output:
[0] >> Setting up the probes
[0] input1: 0
[0] input2: 0
[0] sum: 0
[0] carry: 0
[0] >> Setting up the half-adder
[0] half-adder-a: 0
[0] half-adder-b: 0
[1] >> Setting input1 to 1
[1] input1: 1
[205] half-adder-b: 1
[505] half-adder-a: 1
[811] sum: 1
[1003] >> Setting input2 to 1
[1003] input2: 1
[1307] carry: 1
[1508] half-adder-b: 0
[1811] sum: 0In binary, 1 + 1 = 10. Correct! Notice again how the signal propagation through the gates is delayed. Next up is the full adder.
A Full adder adds three bits, two inputs and a carry-in:
 </noscript>
</noscript>
Notice that a full adder uses two half adders. Again, we follow the diagram and connect the wires:
function FullAdder(label, input1, input2, carryIn, sum, carryOut) {
var hsum = Wire();
var carry1 = Wire();
var carry2 = Wire();
addProbe(label + "-hsum", hsum);
addProbe(label + "-carry1", carry1);
addProbe(label + "-carry2", carry2);
HalfAdder(label + "-HA-" + 1, input2, carryIn, hsum, carry1);
HalfAdder(label + "-HA-" + 2, input1, hsum, sum, carry2);
OrGate(carry1, carry2, carryOut);
}Let’s skip the demo for full adder and jump to something more exciting.
A Ripple-carry adder chains together multiple full adders to add multi-bit numbers. The diagram below shows a four-bit adder:
 </noscript>
</noscript>
We create a ripple-carry adder that can add any number of bits. First we need some helper functions:
function Bits(label, n) {
var bits = Empty();
var bit = null;
while (n > 0) {
bit = Wire();
addProbe(label + (n - 1), bit);
bits = prepend(bits, bit);
n = n - 1;
}
return bits;
}
function setBits(bits, bitValues) {
if (bits != Empty()) {
setSignal(first(bits), first(bitValues));
setBits(rest(bits), rest(bitValues));
}
}Bits creates a list of wires to represent an N-bit input/output. setBits sets the bits of a N-bit wire list to a given N-bit value. Now we write a ripple-carry adder:
function RippleCarryAdder(label, a, b, carryIn, sum, carryOut) {
var aBits = a;
var bBits = b;
var sumBits = sum;
var cIn = carryIn;
var cOut = null;
var i = 1;
while (aBits != Empty()) {
cOut = Wire();
addProbe(label + "-carryIn-" + i, cIn);
addProbe(label + "-carryOut-" + i, cOut);
FullAdder(label + "-FA-" + i,
first(aBits), first(bBits), cIn, first(sumBits), cOut);
aBits = rest(aBits);
bBits = rest(bBits);
sumBits = rest(sumBits);
cIn = cOut;
i = i + 1;
}
connect(cOut, carryOut);
}The ripple-carry adder uses one full adder per bit, cascading the carry-out bit of each input bit-pair’s sum to the next pair of bits. To demonstrate, let’s add two 4-bit numbers:
log(">> Setting up the probes");
var a = Bits("a", 4);
var b = Bits("b", 4);
var sum = Bits("sum", 4);
var carryIn = Wire();
var carryOut = Wire();
addProbe("carryIn", carryIn);
addProbe("carryOut", carryOut);
log(">> Setting up the ripple carry adder");
RippleCarryAdder("RCA", a, b, carryIn, sum, carryOut);
log(">> Setting carryIn to 0");
setSignal(carryIn, 0);
log(">> Setting a to 5 = 0101 in binary");
setBits(a, Cons(1, Cons(0, Cons(1, Cons(0, Empty())))));
sleep(1000);
log(">> Setting b to 11 = 1011 in binary");
setBits(b, Cons(1, Cons(1, Cons(0, Cons(1, Empty())))));This one runs for a while because of the collective delays.
[0] >> Setting up the probes
[1] a3: 0
[1] a2: 0
[1] a1: 0
[1] a0: 0
[1] b3: 0
[1] b2: 0
[1] b1: 0
[1] b0: 0
[1] sum3: 0
[1] sum2: 0
[1] sum1: 0
[1] sum0: 0
[1] carryIn: 0
[1] carryOut: 0
[1] >> Setting up the ripple carry adder
[1] RCA-carryIn-1: 0
[1] RCA-carryOut-1: 0
[1] RCA-FA-1-hsum: 0
[1] RCA-FA-1-carry1: 0
[1] RCA-FA-1-carry2: 0
[1] RCA-FA-1-HA-1-a: 0
[1] RCA-FA-1-HA-1-b: 0
[1] RCA-FA-1-HA-2-a: 0
[1] RCA-FA-1-HA-2-b: 0
[1] RCA-carryIn-2: 0
[1] RCA-carryOut-2: 0
[1] RCA-FA-2-hsum: 0
[2] RCA-FA-2-carry1: 0
[2] RCA-FA-2-carry2: 0
[2] RCA-FA-2-HA-1-a: 0
[2] RCA-FA-2-HA-1-b: 0
[2] RCA-FA-2-HA-2-a: 0
[2] RCA-FA-2-HA-2-b: 0
[2] RCA-carryIn-3: 0
[2] RCA-carryOut-3: 0
[2] RCA-FA-3-hsum: 0
[2] RCA-FA-3-carry1: 0
[2] RCA-FA-3-carry2: 0
[2] RCA-FA-3-HA-1-a: 0
[2] RCA-FA-3-HA-1-b: 0
[2] RCA-FA-3-HA-2-a: 0
[2] RCA-FA-3-HA-2-b: 0
[2] RCA-carryIn-4: 0
[2] RCA-carryOut-4: 0
[2] RCA-FA-4-hsum: 0
[2] RCA-FA-4-carry1: 0
[2] RCA-FA-4-carry2: 0
[2] RCA-FA-4-HA-1-a: 0
[2] RCA-FA-4-HA-1-b: 0
[2] RCA-FA-4-HA-2-a: 0
[2] RCA-FA-4-HA-2-b: 0
[2] >> Setting carryIn to 0
[2] >> Setting a to 5 = 0101 in binary
[2] a0: 1
[3] a2: 1
[205] RCA-FA-1-HA-1-b: 1
[205] RCA-FA-1-HA-2-b: 1
[205] RCA-FA-2-HA-1-b: 1
[207] RCA-FA-2-HA-2-b: 1
[207] RCA-FA-3-HA-1-b: 1
[207] RCA-FA-3-HA-2-b: 1
[207] RCA-FA-4-HA-1-b: 1
[207] RCA-FA-4-HA-2-b: 1
[505] RCA-FA-1-HA-2-a: 1
[505] RCA-FA-3-HA-2-a: 1
[810] sum0: 1
[810] sum2: 1
[1014] >> Setting b to 11 = 1011 in binary
[1015] b0: 1
[1015] b1: 1
[1016] b3: 1
[1521] RCA-FA-1-HA-1-a: 1
[1521] RCA-FA-2-HA-1-a: 1
[1521] RCA-FA-4-HA-1-a: 1
[1826] RCA-FA-1-hsum: 1
[1826] RCA-FA-2-hsum: 1
[1826] RCA-FA-4-hsum: 1
[2129] RCA-FA-1-carry2: 1
[2331] RCA-FA-2-HA-2-a: 1
[2331] RCA-FA-4-HA-2-a: 1
[2331] RCA-FA-1-HA-2-b: 0
[2633] RCA-carryOut-1: 1
[2633] sum1: 1
[2633] sum3: 1
[2633] sum0: 0
[2634] RCA-carryIn-2: 1
[2936] RCA-FA-2-carry1: 1
[3138] RCA-FA-2-HA-1-b: 0
[3440] RCA-carryOut-2: 1
[3440] RCA-FA-2-hsum: 0
[3440] RCA-carryIn-3: 1
[3946] RCA-FA-2-HA-2-a: 0
[3946] RCA-FA-3-HA-1-a: 1
[4251] sum1: 0
[4252] RCA-FA-3-hsum: 1
[4556] RCA-FA-3-carry2: 1
[4756] RCA-FA-3-HA-2-b: 0
[5059] RCA-carryOut-3: 1
[5059] sum2: 0
[5059] RCA-carryIn-4: 1
[5363] RCA-FA-4-carry1: 1
[5564] RCA-FA-4-HA-1-b: 0
[5867] RCA-carryOut-4: 1
[5867] RCA-FA-4-hsum: 0
[5867] carryOut: 1
[6370] RCA-FA-4-HA-2-a: 0
[6675] sum3: 0Let me pick out the final output:
sum0: 0
sum1: 0
sum2: 0
carryOut: 1
sum3: 0We add 0101 and 1011 in binary, resulting in 10000, which is correct again. Everything works perfectly. With sleep, we’ve now implemented all major features of Co—a complete concurrent language with first-class coroutines, channels, and time-based scheduling.
With the addition of sleep, we’ve completed our implementation of Co—a small language with coroutines and channels. Over these five posts, we went from parsing source code to building a full interpreter that handles cooperative multitasking using coroutines.
The key insight was realizing that coroutines are just environments plus continuations. By designing our interpreter to use continuation-passing style, we gained the ability to suspend execution at any point and resume it later. Channels built naturally on top of that, providing a way for coroutines to synchronize and pass messages. And sleep extended the scheduler to handle time-based execution, unlocking patterns like timeouts and periodic tasks.
The examples we built along the way—pubsub system, actor system, and digital circuit simulation—show what becomes possible once these primitives are in place. Starting with basic arithmetic and functions, we ended up with a language capable of expressing real concurrent programs.
What comes next? Maybe a compiler for Co? Stay tuned by subscribing to the feed or the email newsletter.
The full code for the Co interpreter is available here.
If you have any questions or comments, please leave a comment below. If you liked this post, please share it. Thanks for reading!
The sleep implementation in Co is not interruptible. That is, if a coroutine is sleeping, it cannot be resumed before the specified duration. This is different from sleep implementations in most programming languages, where the sleep operation can be interrupted by sending a signal to the sleeping ToC.↩�
Threads in GHC are Green Threads and are very cheap to create and run. It is perfectly okay to fork a new one for each delayed coroutine.↩�
So in a way, we cheat here by using the sleep primitive provided by the GHC runtime to implement our sleep primitive. If we write a compiler for Co, we’ll have to write our own runtime where we’ll have to implement our sleep function using the functionalities provided by the operating systems.↩�
To learn more about how MVars can be used to communicate between threads, read the chapter 24 of Real World Haskell.↩�
This post is a part of the series: Implementing Co, a Small Language With Coroutines.
Thanks for reading this post via feed. Feeds are great, and you're great for using them. ♥
This post was originally published on abhinavsarkar.net.
Read more of my posts and notes.
Security in software development has evolved dramatically, yet it’s still one of the easiest things to postpone. Everyone knows it should start early — vulnerabilities are cheaper and simpler to fix when caught before deployment, but deadlines and complexity often push it to the sidelines.
That’s where Static Application Security Testing (SAST) tools like CodeQL come in.
If you’ve used CodeQL, you already know how powerful it is. Instead of relying on predefined rules or pattern matching, it treats your code like data, allowing deep semantic analysis that finds subtle, logic-based vulnerabilities other scanners miss — and it does so with impressive precision, minimizing false positives.
If this is your first contact with CodeQL, it’s worth checking out this great introduction before diving in.
However, while CodeQL’s power is undeniable, integrating it smoothly across large organizations, monorepos, or custom CI/CD pipelines can be challenging.
Here are some of the issues teams typically encounter:
We’ve been there ourselves. That’s why we built CodeQL Wrapper, an open-source tool that simplifies running CodeQL in any environment, no matter how complex your repo or CI system might be.
This post explains why we built it, what it does in practice, and how to use it to simplify your CodeQL workflows without a deep technical dive.
CodeQL Wrapper is a universal Python CLI that abstracts away much of the setup pain and provides a consistent way to run CodeQL across projects.
It allows you to run CodeQL anywhere — locally or in CI systems like GitHub Actions, Jenkins, Azure Pipelines, CircleCI, or Harness while ensuring consistent behavior across environments.
It automatically fetches and installs the correct version of the CodeQL CLI, meaning your local runs and CI analyses always stay in sync. And even if your pipelines don’t run on GitHub, CodeQL Wrapper can still send results back to GitHub Advanced Security in SARIF format for centralized visibility.
Beyond simplifying setup, CodeQL Wrapper helps teams maintain consistent configuration using a flexible .codeql.json file. This lets you define build modes, custom queries, and paths once — then apply them consistently across projects.
But where the wrapper really shines is in its ability to handle monorepos, tackling two of the biggest pain points: language detection and performance.
Many modern projects mix languages. A Python API here, a JavaScript frontend there, maybe a bit of Go for background services.
CodeQL’s default GitHub Action setup requires manually specifying which language to analyze. That’s fine for small projects, but a maintenance nightmare for monorepos.
CodeQL Wrapper removes this burden entirely. It automatically detects languages present in your codebase and configures the analysis for you.
This automation ensures nothing slips through the cracks (no forgotten languages, no partial scans) and keeps your configuration simple and future-proof.
Running CodeQL can be time-consuming, especially in large repositories. CodeQL Wrapper optimizes this in two complementary ways: it runs analyses in parallel and skips unchanged code altogether.
The parallelization happens on two levels:
The tool intelligently adapts to your system’s hardware using all available CPU cores without exhausting memory. Though you can manually tune the settings if needed.
And because avoiding unnecessary work is even better than parallelizing it, CodeQL Wrapper includes a change detection algorithm that analyzes only the code that has actually changed since the last scan.
It uses Git to identify modified files and determines which projects those files belong to. If no relevant files have changed, the tool automatically skips redundant analysis steps, avoiding unnecessary database creation and query execution, cutting analysis time from hours to minutes on large monorepos.
At a high level, the wrapper determines a base commit (from CI variables or an explicit flag), fetches any missing refs, computes the diff, and maps changed files to projects. Only those projects proceed to database creation and query execution. The logic is platform‑agnostic, so the same behavior applies whether you run in GitHub Actions, Azure Pipelines, CircleCI, Harness, or locally.
We designed CodeQL Wrapper so that the first run feels frictionless and the hundredth run still feels predictable. Installation is a single step, and from there you can either prepare the environment or jump straight into analysis.
pip install codeql-wrapperThis will install the tool in your environment. Once installed, you’ll have access to two commands:
codeql-wrapper installThis fetches the CodeQL CLI and query packs, and you can pin versions with --version to keep results reproducible. When you’re ready to analyze, analyze takes over the heavy lifting: it confirms CodeQL is installed, detects languages and projects, creates databases, and runs queries in parallel to suit your hardware.
Most teams start by pointing the wrapper at the repository root. That’s intentional: you shouldn’t need to hand‑craft language lists or database steps to get useful results.
codeql-wrapper analyze ./repoBehind the scenes, the wrapper inspects your codebase, identifies the languages that matter, and builds one database per language. If your repo is a monorepo, it scopes the work to projects it finds, running them concurrently. The default configuration leans on safe, broadly applicable queries and build-mode: none, which makes first‑time adoption smooth even without bespoke build instructions.
As codebases grow, consistency matters more than one‑off tweaks. The wrapper’s model — automatic detection plus ergonomic overrides — offers practical advantages: it adapts to monorepos with different needs per project, keeps query policies uniform across CI providers, and makes exceptions explicit without touching pipeline YAML.
Rather than generic promises, here’s what changes in day‑to‑day pipelines:
install and analyze. The wrapper handles language detection, database creation, and query execution, so pipelines don’t need fragile per‑language steps.install --version locks the CodeQL CLI version, avoiding environment drift between developer machines and CI runners.Local runs establish trust, but enterprise adoption hinges on repeatable automation. To make that transition easy, we ship codeql-wrapper-pipelines, a companion repository with templates for common CI/CD providers. These examples handle the practicalities — auth, artifacts, and reporting — while keeping the interface consistent. You get one way of invoking the wrapper, regardless of whether your pipelines live in GitHub Actions, Azure Pipelines, CircleCI, Harness, or elsewhere.
Our work with global enterprises adopting GitHub Advanced Security led us to build both codeql-wrapper and codeql-wrapper-pipelines. The tools distill hard‑won lessons from monorepo rollouts: minimize manual configuration, keep behavior consistent across environments, and make smart defaults easy to override.
The goal isn’t just faster scans; it’s a smoother path to reliable, organization‑wide CodeQL usage. If you’re strengthening DevSecOps without piling on process, we think this approach strikes the right balance. Give the wrapper a try, explore the pipelines, and reach out on the repositories if you want help shaping them to your environment.
A couple months ago, I asked for help creating a web interface for Disco, a student-oriented programming language for teaching functional programming and discrete mathematics. I am very happy to report that Heinrich Apfelmus responded to the call, and this is the result:
It’s fairly bare bones at the moment, but it’s a fantastic place to start, and far more than I would have been able to accomplish in a few weeks. Give it a try, and let me know of any bugs you find! You are also very welcome to contribute fixes, features, etc. on GitHub:
If you want to know more about Disco, you can read a paper about it here, or read the language documentation.
The Haskell Debugger is ready to use with GHC-9.14!
The installation, configuration, and talks can be found in the official website. The tl;dr first step is installing the debugger:
$ ghc --version # MUST BE GHC 9.14
The Glorious Glasgow Haskell Compilation System, version 9.14.1
$ cabal install haskell-debugger --allow-newer=base,time,containers,ghc,ghc-bignum,template-haskell --enable-executable-dynamic # ON WINDOWS, DO NOT PASS --enable-executable-dynamic
...
$ ~/.local/bin/hdb --version # VERIFY IT'S THE LATEST!
Haskell Debugger, version 0.11.0.0The second step is configuring your editor to use the debugger via the Debug Adapter Protocol (DAP).
nvim-dap and configure it for haskell-debuggerBug reports and discussions are welcome in the haskell-debugger issue tracker.
My MuniHac 2025 talk also walks through the installation, usage, and design of the debugger. Do note much has been improved since the talk was given, and much more will still improve.
The debugger work is sponsored by Mercury. It’s the project in which I’ve spent most of my full working days (for almost a full year now), with the invaluable help from my team at Well-Typed.
The debugger is meant to work both on trivial files and on large and complex codebases.1 It is a GHC application so all features are supported. Like HLS, it also uses hie-bios to automatically configure the session based on your cabal or stack project.
Robustness is a main goal of the debugger. If anything doesn’t work, or if you have performance issues, or something crashes, please don’t hesitate to submit a bug. We’ve got a small but respectable testsuite, and have tested performance by debugging GHC itself, but there’s much still to be fixed and improved.
Roadmap: There’s a lot to do. I’m currently working on callstacks and multi-threaded support. Do let me know what features would be most important to you, so I can also factor that into the future planning.
Although, for large codebases, the usability is still rough around the edges because of possibly long bytecode compilation times, and library code not being interpreted. We’ve made considerable progress to improve this with the bytecode artifacts work.↩︎
The Haskell Debugger is ready to use with GHC-9.14!
The installation, configuration, and talks can be found in the official website. The tl;dr first step is installing the debugger:
$ ghc --version # MUST BE GHC 9.14
The Glorious Glasgow Haskell Compilation System, version 9.14.1
$ cabal install haskell-debugger --allow-newer=base,time,containers,ghc,ghc-bignum,template-haskell --enable-executable-dynamic # ON WINDOWS, DO NOT PASS --enable-executable-dynamic
...
$ ~/.local/bin/hdb --version # VERIFY IT'S THE LATEST!
Haskell Debugger, version 0.11.0.0The second step is configuring your editor to use the debugger via the Debug Adapter Protocol (DAP).
nvim-dap and configure it for haskell-debuggerBug reports and discussions are welcome in the haskell-debugger issue tracker.
My MuniHac 2025 talk also walks through the installation, usage, and design of the debugger. Do note much has been improved since the talk was given, and much more will still improve.
The debugger work is sponsored by Mercury. It’s the project in which I’ve spent most of my full working days (for almost a full year now), with the invaluable help from my team at Well-Typed.
The debugger is meant to work both on trivial files and on large and complex codebases.1 It is a GHC application so all features are supported. Like HLS, it also uses hie-bios to automatically configure the session based on your cabal or stack project.
Robustness is a main goal of the debugger. If anything doesn’t work, or if you have performance issues, or something crashes, please don’t hesitate to submit a bug. We’ve got a small but respectable testsuite, and have tested performance by debugging GHC itself, but there’s much still to be fixed and improved.
Roadmap: There’s a lot to do. I’m currently working on callstacks and multi-threaded support. Do let me know what features would be most important to you, so I can also factor that into the future planning.
Although, for large codebases, the usability is still rough around the edges because of possibly long bytecode compilation times, and library code not being interpreted. We’ve made considerable progress to improve this with the bytecode artifacts work.↩︎
I've been playing around with adding more validation of data received by an HTTP
endpoint in a servant server. Defining a type with a FromJSON instance is very
easy, just derive a Generic instance and it just works. Here's a simple
example
data Person = Person
{ name :: Text
, age :: Int
, occupation :: Occupation
}
deriving (Generic, Show)
deriving (FromJSON, ToJSON) via (Generically Person)
data Occupation = UnderAge | Student | Unemployed | SelfEmployed | Retired | Occupation Text
deriving (Eq, Generic, Ord, Show)
deriving (FromJSON, ToJSON) via (Generically Occupation)
However, the validation is rather limited, basically it's just checking that
each field is present and of the correct type. For the type above I'd like to
enforce some constraints for the combination of age and occupation.
The steps I thought of are
FromJSON instance using the Generic instance to limit
the amount of code and the smart constructor.
I give the constructor the result type Either String Person to make sure it
can both be usable in code and when defining parseJSON.
mkPerson :: Text -> Int -> Occupation -> Either String Person
mkPerson name age occupation = do
guardE mustBeUnderAge
guardE notUnderAge
guardE tooOldToBeStudent
guardE mustBeRetired
pure $ Person name age occupation
where
guardE (pred, err) = when pred $ Left err
mustBeUnderAge = (age < 8 && occupation > UnderAge, "too young for occupation")
notUnderAge = (age > 15 && occupation == UnderAge, "too old to be under age")
tooOldToBeStudent = (age > 45 && occupation == Student, "too old to be a student")
mustBeRetired = (age > 65 && occupation /= Retired, "too old to not be retired")
Here I'm making use of Either e being a Monad and use when to apply the
constraints and ensure the reason for failure is given to the caller.
FromJSON instance
When defining the instance I take advantage of the Generic instance to make
the implementation short and simple.
instance FromJSON Person where
parseJSON v = do
Person{name, age, occupation} <- genericParseJSON defaultOptions v
either fail pure $ mkPerson name age occupation
If there are many more fields in the type I'd consider using RecordWildCards.
No, it's nothing ground-breaking but I think it's a fairly nice example of how things can fit together in Haskell.
In 2007, Martin Escardo wrote a often-read blog post about “Seemingly impossible functional programs”. One such seemingly impossible function is find, which takes a predicate on infinite sequences of bits, and returns an infinite sequence for which that predicate hold (unless the predicate is just always false, in which case it returns some arbitrary sequence).
Inspired by conversations with and experiments by Massin Guerdi at the dinner of LeaningIn 2025 in Berlin (yes, this blog post has been in my pipeline for far too long), I wanted to play around these concepts in Lean.
Let’s represent infinite sequences of bits as functions from Nat to Bit, and give them a nice name, and some basic functionality, including a binary operator for consing an element to the front:
import Mathlib.Data.Nat.Find
abbrev Bit := Bool
def Cantor : Type := Nat → Bit
def Cantor.head (a : Cantor) : Bit := a 0
def Cantor.tail (a : Cantor) : Cantor := fun i => a (i + 1)
@[simp, grind] def Cantor.cons (x : Bit) (a : Cantor) : Cantor
| 0 => x
| i+1 => a i
infix:60 " # " => Cantor.consWith this in place, we can write Escardo’s function in Lean. His blog post discusses a few variants; I’ll focus on just one of them:
mutual
partial def forsome (p : Cantor → Bool) : Bool :=
p (find p)
partial def find (p : Cantor → Bool) : Cantor :=
have b := forsome (fun a => p (true # a))
(b # find (fun a => p (b # a)))
endWe define find together with forsome, which checks if the predicate p holds for any sequence. Using that find sets the first element of the result to true if there exists a squence starting with true, else to false, and then tries to find the rest of the sequence.
It is a bit of a brian twiter that this code works, but it does:
def fifth_false : Cantor → Bool := fun a => not (a 5)
/-- info: [true, true, true, true, true, false, true, true, true, true] -/
#guard_msgs in
#eval List.ofFn (fun (i : Fin 10) => find fifth_false i)Of course, in Lean we don’t just want to define these functions, but we want to prove that they do what we expect them to do.
Above we defined them as partial functions, even though we hope that they are not actually partial: The partial keyword means that we don’t have to do a termination proof, but also that we cannot prove anything about these functions.
So can we convince Lean that these functions are total after all? We can, but it’s a bit of a puzzle, and we have to adjust the definitions.
First of all, these “seemingly impossible functions” are only possible because we assume that the predicate we pass to it, p, is computable and total. This is where the whole magic comes from, and I recommend to read Escardo’s blog posts and papers for more on this fascinating topic. In particular, you will learn that a predicate on Cantor that is computable and total necessarily only looks at some initial fragment of the sequence. The length of that prefix is called the “modulus”. So if we hope to prove termination of find and forsome, we have to restrict their argument p to only such computable predicates.
To that end I introduce HasModulus and the subtype of predicates on Cantor that have such a modulus:
-- Extensional (!) modulus of uniform continuity
def HasModulus (p : Cantor → α) := ∃ n, ∀ a b : Cantor, (∀ i < n, a i = b i) → p a = p b
@[ext] structure CantorPred where
pred : Cantor → Bool
hasModulus : HasModulus predThe modulus of such a predicate is now the least prefix lenght that determines the predicate. In particular, if the modulus is zero, the predicate is constant:
namespace CantorPred
variable (p : CantorPred)
noncomputable def modulus : Nat :=
open Classical in Nat.find p.hasModulus
theorem eq_of_modulus : ∀a b : Cantor, (∀ i < p.modulus, a i = b i) → p a = p b := by
open Classical in
unfold modulus
exact Nat.find_spec p.hasModulus
theorem eq_of_modulus_eq_0 (hm : p.modulus = 0) : ∀ a b, p a = p b := by
intro a b
apply p.eq_of_modulus
simp [hm]Because we want to work with CantorPred and not Cantor → Bool I have to define some operations on that new type; in particular the “cons element before predicate” operation that we saw above in find:
def comp_cons (b : Bit) : CantorPred where
pred := fun a => p (b # a)
hasModulus := by
obtain ⟨n, h_n⟩ := p.hasModulus
cases n with
| zero => exists 0; grind
| succ m =>
exists m
intro a b heq
simp
apply h_n
intro i hi
cases i
· rfl
· grind
@[simp, grind =] theorem comp_cons_pred (x : Bit) (a : Cantor) :
(p.comp_cons x) a = p (x # a) := rflFor this operation we know that the modulus decreases (if it wasn’t already zero):
theorem comp_cons_modulus (x : Bit) :
(p.comp_cons x).modulus ≤ p.modulus - 1 := by
open Classical in
apply Nat.find_le
intro a b hab
apply p.eq_of_modulus
cases hh : p.modulus
· simp
· intro i hi
cases i
· grind
· grind
grind_pattern comp_cons_modulus => (p.comp_cons x).modulusWe can rewrite the find function above to use these operations:
mutual
partial def forsome (p : CantorPred) : Bool := p (find p)
partial def find (p : CantorPred) : Cantor := fun i =>
have b := forsome (p.comp_cons true)
(b # find (p.comp_cons b)) i
endI have also eta-expanded the Cantor function returned by find; there is now a fun i => … i around the body. We’ll shortly see why that is needed.
Now have everything in place to attempt a termination proof. Before we do that proof, we could step back and try to come up with an informal termination argument.
The recursive call from forsome to find doesn’t decrease any argument at all. This is ok if all calls from find to forsome are decreasing.
The recursive call from find to find decreases the index i as the recursive call is behind the Cantor.cons operation that shifts the index. Good.
The recursive call from find to forsome decreases the modulus of the argument p, if it wasn’t already zero.
But if was zero, it does not decrease it! But if it zero, then the call from forsome to find doesn’t actually need to call find, because then p doesn’t look at its argument.
We can express all this reasoning as a termination measure in the form of a lexicographic triple. The 0 and 1 in the middle component mean that for zero modulus, we can call forsome from find “for free”.
mutual
def forsome (p : CantorPred) : Bool := p (find p)
termination_by (p.modulus, if p.modulus = 0 then 0 else 1, 0)
decreasing_by grind
def find (p : CantorPred) : Cantor := fun i =>
have b := forsome (p.comp_cons true)
(b # find (p.comp_cons b)) i
termination_by i => (p.modulus, if p.modulus = 0 then 1 else 0, i)
decreasing_by all_goals grind
endThe termination proof doesn’t go through just yet: Lean is not able to see that (_ # p) i will call p with i - 1, and it does not see that p (find p) only uses find p if the modulus of p is non-zero. We can use the wf_preprocess feature to tell it about that:
The following theorem replaces a call to p f, where p is a function parameter, with the slightly more complex but provably equivalent expression on the right, where the call to f is no in the else branch of an if-then-else and thus has ¬p.modulus = 0 in scope:
@[wf_preprocess]
theorem coe_wf (p : CantorPred) :
(wfParam p) f = p (if _ : p.modulus = 0 then fun _ => false else f) := by
split
next h => apply p.eq_of_modulus_eq_0 h
next => rflAnd similarly we replace (_ # p) i with a variant that extend the context with information on how p is called:
def cantor_cons' (x : Bit) (i : Nat) (a : ∀ j, j + 1 = i → Bit) : Bit :=
match i with
| 0 => x
| j + 1 => a j (by grind)
@[wf_preprocess] theorem cantor_cons_congr (b : Bit) (a : Cantor) (i : Nat) :
(b # a) i = cantor_cons' b i (fun j _ => a j) := by cases i <;> rflAfter these declarations, the above definition of forsome and find goes through!
It remains to now prove that they do what they should, by a simple induction on the modulus of p:
@[simp, grind =] theorem tail_cons_eq (a : Cantor) : (x # a).tail = a := by
funext i; simp [Cantor.tail, Cantor.cons]
@[simp, grind =] theorem head_cons_tail_eq (a : Cantor) : a.head # a.tail = a := by
funext i; cases i <;> rfl
theorem find_correct (p : CantorPred) (h_exists : ∃ a, p a) : p (find p) := by
by_cases h0 : p.modulus = 0
· obtain ⟨a, h_a⟩ := h_exists
rw [← h_a]
apply p.eq_of_modulus_eq_0 h0
· rw [find.eq_unfold, forsome.eq_unfold]
dsimp -zeta
extract_lets b
change p (_ # _)
by_cases htrue : ∃ a, p (true # a)
next =>
have := find_correct (p.comp_cons true) htrue
grind
next =>
have : b = false := by grind
clear_value b; subst b
have hfalse : ∃ a, p (false # a) := by
obtain ⟨a, h_a⟩ := h_exists
cases h : a.head
· exists Cantor.tail a
grind
· exfalso
apply htrue
exists Cantor.tail a
grind
clear h_exists
exact find_correct (p.comp_cons false) hfalse
termination_by p.modulus
decreasing_by all_goals grind
theorem forsome_correct (p : CantorPred) :
forsome p ↔ (∃ a, p a) where
mp hfind := by unfold forsome at hfind; exists find p
mpr hex := by unfold forsome; exact find_correct p hexThis is pretty nice! However there is more to do. For example, Escardo has a “massively faster” variant of find that we can implement as a partial function in Lean:
def findBit (p : Bit → Bool) : Bit :=
if p false then false else true
def branch (x : Bit) (l r : Cantor) : Cantor :=
fun n =>
if n = 0 then x
else if 2 ∣ n then r ((n - 2) / 2)
else l ((n - 1) / 2)
mutual
partial def forsome (p : Cantor -> Bool) : Bool :=
p (find p)
partial def find (p : Cantor -> Bool) : Cantor :=
let x := findBit (fun x => forsome (fun l => forsome (fun r => p (branch x l r))))
let l := find (fun l => forsome (fun r => p (branch x l r)))
let r := find (fun r => p (branch x l r))
branch x l r
endBut can we get this past Lean’s termination checker? In order to prove that the modulus of p is decreasing, we’d have to know that, for example, find (fun r => p (branch x l r)) is behaving nicely. Unforunately, it is rather hard to do termination proof for a function that relies on the behaviour of the function itself.
So I’ll leave this open as a future exercise.
I have dumped the code for this post at https://github.com/nomeata/lean-cantor.
In my last post, I was struggling towards an algebraic theory of music. This idea has been burning in my mind ever since, and I wanted to give some updates with where I’ve landed.
We begin by modeling a musical voice, which is, roughly speaking, the abstract version of a human voice. The voice can be doing one thing at a time, or can choose to not be doing anything.
Voices are modeled by step functions, which are divisions of the real line into discrete chunks. We interpret each discrete chunk as a note being played by the voice for the duration of the chunk.
This gives rise to a nice applicative structure that I alluded to in my previous post:
liftA2 f
|---- a ----|-- b --|
|-- x --|---- y ----|
=
|- fax -|fay|- fby -|where we take the union of the note boundaries in order to form the applicative. If either voice is resting, so too is the applicative. There is also an Alternative instance here, which chooses the first non-rest.
There is a similar monoidal structure here, where multiplication is given by “play these two things simultaneously,” relying on an underlying Semigroup instance for the meaning of “play these two things:”
If either voice is resting, we treat its value as mempty, and can happily combine the two parts in parallel.
All of this gives rise to the following rich structure:
newtype Voice a = Voice { unVoice :: SF Time (Maybe a) }
deriving stock
(Eq, Ord, Show, Functor, Foldable, Traversable, Generic, Generic1)
deriving newtype
(Semigroup, Monoid)
deriving
Applicative
via Compose (SF Time) Maybe
instance Filterable Voice
instance Witherable Voice
instance Alternative Voice
-- | Delay a voice by some amount of time.
delayV :: Time -> Voice a -> Voice aVoices, therefore, give us our primitive notion of monophony. But real music usually has many voices doing many things, independently. This was a point in which I got stuck in my previous post.
The solution here, is surprisingly easy. Assign a Voice to each voice name:
newtype Music v a = Music
{ getVoices :: v -> Voice a
}
deriving stock
(Functor, Generic, Functor)
deriving newtype
(Semigroup, Monoid)
deriving (Applicative, Alternative)
via Compose ((->) v) Voice
instance Profunctor Music
instance Finite v => Foldable (Music v)
instance Finite v => Traversable (Music v)
instance Filterable (Music v)
instance Finite v => Witherable (Music v)We get an extremely rich structure here completely for free. Our monoid combines all voices in parallel; our applicative combines voices pointwise; etc. However, we also have a new Profunctor Music instance, whose characteristic lmap :: (b -> c) -> Music c a -> Music b a method allows us to trade lines between voices.
In addition to the in-parallel monoid instance, we can also define a tile product operator over Music v a, which composes things sequentially1:
duration :: Music v a -> Time
(##) :: Semigroup a => Music v a -> Music v a -> Music v a
m@(Music m1) ## Music m2 =
Music $ liftA2 (<>) m1 $ fmap (delayV $ duration m) m2The Semigroup a constraint on (##) arises from the fact that the pieces of music might extend off to infinity in either direction (which pure @Voice must do), and we need to deal with that.
There are a few other combinators we care about. First, we can lift anonymous voices (colloquially “tunes”) into multi-part Music:
voice :: Eq v => v -> Music () a -> Music v a
voice v (Music sf) = Music $
\case
((== v) -> True) -> sf ()
_ -> memptyand we can assign the same line to everyone:
The primitives for building little tunes are
which you can then compose sequentially via (##), and assign to voices via voice.
One of the better responses to my last blog post was a link to Dmitri Tymoczko’s FARM 2024 talk.
There’s much more in this video than I can possibly due justice to here, but my big takeaway was that this guy is thinking about the same sorts of things that I am. So I dove into his work, and that lead to his quadruple hierarchy:
Voices move within chords, which move within scales, which move within macro-harmonies.
Tymoczko presents a T algebra which is a geometric space for reasoning about voice leadings. He’s got a lot of fun websites for exploring the ideas, but I couldn’t find an actual implementation of the idea anywhere, so I cooked one up myself.
The idea here is that we have some T :: [Nat] -> Type which describes a hierarchy of abstract scales moving with respect to one another. For example, the Western traditional of having triads move within the diatonic scale, which moves within the chromatic scale, would be represented as T '[3, 7, 12]. T forms a monoid, and has some simple generators that give rise to smooth voice leadings (chord changes.)
Having a model for smooth harmonic transformations means we can use it constructively. I am still working out the exact details here, but the rough shape of the idea is to build an underlying field of key changes (represented as smooth voice leadings in T '[7, 12]):
We can then make an underlying field of functional harmonic changes (chord changes), modeled as smooth voice leadings in T '[3, 7]:
Our voices responsible for harmony can now be written as values of type
and we can use the applicative musical structure to combine the elements together:
{-# LANGUAGE ApplicativeDo #-}
extend :: T ns -> T (ns ++ ms)
sink :: T ns -> T (n ': ns)
harmony :: Music h (Set (T '[3, 7, 12]))
harmony = do
k <- everyone keyChanges
c <- everyone chordChanges
m <- harmonicVoices
pure $ extend m <> extend c <> sink kwhich we can later fmap out into concrete pitches. The result is that we can completely isolate the following pieces:
and the result is guaranteed to compose in a way that the ear can interpret as music. Not necessarily good music, but undeniably as music.
The type indices on T are purely for my book-keeping, and nothing requires them to be there. Which means we could also use the applicative structure to modulate over different sorts of harmony (eg, move from triads to seventh chords.)
I haven’t quite gotten a feel for melody yet; I think it’s probably in T '[7, 12], but it would be nice to be able to target chord tones as well. Please let me know in the comments if you have any insight here.
However, I have been thinking about contouring, which is the overall “shape” of a musical line. Does it go up, and peak in the middle, and then come down again? Or maybe it smoothly descends down.
We can use the discrete intervals intrinsic inside of Voices to find “reasonable” times to sample them. In essence this assigns a Time to each segment:
and we can then use these times to then sample a function Time -> b. This then allows us to apply contours (given as regular Real -> Real functions) to arbitrary rhythms. I currently have this typed as
where a ~ T something, and the outputted Reals get rounded to their nearest integer values. I’m not deeply in love with this type, but the rough idea is great—turn arbitrary real-valued functions into musical lines. This generalizes contouring, as well as scale runs.
I’m writing all of this up because I go back to work on Monday and life is going to get very busy soon. I’m afraid I won’t be able to finish all of this!
The types above I’m pretty certain are relatively close to perfect. They seem to capture everything I could possibly want, and nothing I don’t want. Assuming I’m right about that, they must make up the basis of musical composition.
The next step therefore is to build musical combinators on top. One particular combinator I’ve got my eye on is some sort of general ~> “get from here to there” operator:
which I imagine would bridge a gap between the end of one piece of music with beginning of another. I think this would be roughly as easy as moving each voice linearly in T space from where it was to where it needs to be. This might need to be a ternary operation in order to also associate a rhythmic pattern to use for the bridge.
But I imagine (~>) would be great for lots of dumb little musical things. Like when applied over the chord dimension, it would generate arpeggios. Over the scale dimension, it would generate runs. And it would make chromatic moves in the chroma dimension.
Choosing exactly what moves to make for Ts consisting of components in multiple axes might just be some bespoke order, or could do something more intelligent. I think the right approach would be to steal diagrams’ idea of an Envelope, and attach some relevant metadata to each Music. We could then write (~>) as a function of those envelopes, but I must admit I don’t quite know what this would look like.
As usual, I’d love any insight you have! Please leave it in the comments. Although I must admit I appreciate comments of the form “have you tried $X” much more than of the form “music is sublime and you’re an idiot for even trying this.”
Happy new year!
Strictly speaking, the tile product can also do parallel composition, as well as sychronizing composition, but that’s not super important right now.↩︎


Did you know that all ACM-sponsored conferences have an anti-harassment policy? I didn’t, until I chaired the Haskell Symposium last year. The concise policy says, among other things, that people shouldn’t use my family constitution to interfere with my professional participation. And the policy has teeth. That’s great.
My not knowing the policy and not seeing it publicized didn’t make me go out of my way to harass anyone. But it did make me less sure and less comfortable that I belonged at ICFP. Briefly, it’s because I didn’t know if it would be common ground at the conference that my actual self was fully human. That’s not something I can take for granted in general society. Also, it’s because I didn’t know whether my fellow conference attendees were aware of the policy. We could all use a reminder, and a public signal that we mean it.
For these reasons, I’m very happy that ICFP will start to publicize ACM’s existing anti-harassment policy and make sure everyone registered knows it. All ACM conferences should do it. That’s why Tim Chevalier, Clement Delafargue, Adam Foltzer, Eric Merritt, and I are doing two things. We ask you to join us:
Thanks for improving our professional homes!

I want to discuss two moral aspects of how to talk about borderline people (e.g., whether to say “MTF” or “female”, “smart” or “good at math”).
The first aspect is what category of people we should be talking about, never mind how we talk about it. Usually, for a given category C, there are many ways to be borderline C: people can be
Of course, it is easy enough to construct a category C’ that firmly includes or excludes particular kinds of borderline Cs (e.g., you are female’ iff you have XX chromosomes), if only to leave unresolved lower-dimensional borderlines (e.g., what if only half of your cells have XX chromosomes). So let’s ask not what categories exist (because they all do) but what categories we should talk about.
It might well be that we should talk about different versions of C for different purposes (e.g., medicine, sports, identification, love). It might also be that delineating categories at their edges is not usually worth our collective cognitive trouble. Regardless, sometimes in conversation or other collaboration I find that multiple versions are actually relevant. For example, some people wonder whether to call a transgender person “male” or “female”, and I think a transgender person can firmly belong to a gender category that we should talk about. Unfortunately, when I tried to work with others to distinguish and choose among versions of categories, I have often been frustrated.
When people in power to classify others don’t take the effort to apply the right category version, the misclassified people can get slighted. I empathize with the misclassified people because I have been misclassified. For example:
Also because I have been misclassified, this discussion of borderlines matters for me practically and personally. It’s not just abstract theorizing.

The second aspect is how to name a given category (version). Even in a context where we agree intellectually that there is exactly one gender category we should talk about (say “female”) and a transgender person belongs to it firmly, the term “female” still takes many people today more thought to produce and comprehend when applied to a person known to be transgender than when applied to a person known to be cisgender. So, it is tempting for a well-meaning speaker to avoid gender categories altogether by terming a transgender person “female-presenting” instead. The “female-presenting” characterization
Your thoughts?
“Show me.”
He bowed his head in mocking, semi-formal acquiescence. “Modern warfare can be fought on so many delightfully different levels,” he continued, walking back to her side as if no interruption of the tour had been suggested. “One wins a battle by making sure one’s troops have enough blunderbusses and battle axes like the ones you saw in the first room; or by the well-placed six-inch length of vanadium wire in a Type 27-QX communications unit. With the proper orders delayed, the encounter never takes place. Hand-to-hand weapons, survival kit, plus training, room, and board: three thousand credits per enlisted stellarman over a period of two years active duty. For a garrison of fifteen hundred men that’s an outlay of four million, five hundred credits. That same garrison will live in and fight from three hyperstasis battleships which, fully equipped, run about a million and a half credits apiece—a total outlay of nine million credits. We have spent, on occasion, perhaps as much as a million on the preparation of a single spy or saboteur. That is rather higher than usual. And I can’t believe a six-inch length of vanadium wire costs a third of a cent. War is costly. And although it has taken some time, Administrative Alliance Headquarters is beginning to realize subtlety pays. This way, Miss—Captain Wong.”
Again they were in a room with only a single display case, but it was seven feet high.
A statue, Rydra thought. No, real flesh, with detail of muscle and joint; no, it must be a statue because a human body, dead or in suspended animation, doesn’t look that… alive. Only art could produce that vibrancy.
“So you see, the proper spy is very important.” Though the door had opened automatically, the Baron held it with his hand in vestigial politeness. “This is one of our more expensive models. Still well under a million credits, but one of my favorites—though in practice he has his faults. With a few minor alterations I would like to make him a permanent part of our arsenal.”
“A model of a spy?” Rydra asked. “Some sort of robot or android?”
“Not at all.” They approached the display case. “We made half a dozen TW-55’s. It took the most exacting genetic search. Medical science has progressed so that all sorts of hopeless human refuse lives and reproduces at a frightening rate—inferior creatures that would have been too weak to survive a handful of centuries ago. We chose our parents carefully, and then with artificial insemination we got our half dozen zygotes, three male, three female. We raised them in, oh, such a carefully controlled nutrient environment, speeding the growth rate by hormones and other things. But the beauty of it was the experiential imprinting. Gorgeously healthy creatures; you have no idea how much care they received.”
“I once spent a summer on a cattle farm,” Rydra said shortly.
The Baron’s nod was brisk. “We’d used the experiential imprints before, so we knew what we were doing. But never to synthesize completely the life situation of, say, a sixteen-year-old human. Sixteen was the physiological age we brought them to in six months. Look for yourself what a splendid specimen it is. The reflexes are fifty percent above those of a human aged normally. Human musculature is beautifully engineered: a three-day-starved, six-month-atrophied myasthenia gravis case, can, with the proper stimulant drugs, overturn a ton-and-a-half automobile. It will kill him—but that’s still remarkable efficiency. Think what the biologically perfect body, operating at all times at point nine-nine efficiency, could accomplish in physical strength alone.”
“I thought hormone growth incentive had been outlawed. Doesn’t it reduce the life span some drastic amount?”
“To the extent we used it, the life span reduction is seventy-five percent and over.” He might have smiled the same way watching some odd animal at its incomprehensible antics. “But, Madam, we are making weapons. If TW-55 can function twenty years at peak efficiency, then it will have outlasted the average battle cruiser by five years. But the experiential imprinting! To find among ordinary men someone who can function as a spy, is willing to function as a spy, you must search the fringes of neurosis, often psychosis. Though such deviations might mean strength in a particular area, it always means an overall weakness in the personality. Functioning in any but that particular area, a spy may be dangerously inefficient. And the Invaders have psyche-indices too, which will keep the average spy out of anyplace we might want to put him. Captured, a good spy is a dozen times as dangerous as a bad one. Post-hypnotic suicide suggestions and the like are easily gotten around with drugs; and are wasteful. TW-55 here will register perfectly normal on a psyche integration. He has about six hours of social conversation, plot synopses of the latest novels, political situations, music, and art criticism—l believe in the course of an evening he is programmed to drop your name twice, an honor you share only with Ronald Quar. He has one subject on which he can expound with scholarly acumen for an hour and a half—this one, I believe, is ‘haptoglobin groupings among the marsupials.’ Put him in formal wear and he will be perfectly at home at an ambassadorial ball or a coffee break at a high-level government conference. He is a crack assassin, expert with all the weapons you have seen up till now, and more. TW-55 has twelve hours’ worth of episodes in fourteen different dialects, accents, or jargons concerning sexual conquests, gambling experiences, fisticuff encounters, and humorous anecdotes of semi-illegal enterprises, all of which failed miserably. Tear his shirt, smear grease on his face and slip a pair of overalls on him, and he could be a service mechanic on any one of a hundred spaceyards or stellarcenters on the other side of the Snap. He can disable any space drive system, communications components, radar works, or alarm system used by the Invaders in the past twenty years with little more than—”
“Six inches of vanadium wire?”
The Baron smiled. “His fingerprints and retina pattern, he can alter at will. A little neural surgery has made all the muscles of his face voluntary, which means he can alter his facial structure drastically. Chemical dyes and hormone banks beneath the scalp enable him to color his hair in seconds, or, if necessary, shed it completely and grow a new batch in half an hour. He’s a past master in the psychology and physiology of coercion.”
“Torture?”
“If you will. He is totally obedient to the people whom he has been conditioned to regard as his superiors; totally destructive toward what he has been ordered to destroy. There is nothing in that beautiful head even akin to a superego.”
“He is…” and she wondered at herself speaking, “beautiful.” The dark-lashed eyes with lids about to quiver open, the broad hands hung at the naked thighs, fingers half-curled, about to straighten or become a fist. The display light was misty on the tanned, yet near-translucent skin. “You say this isn’t a model, but really alive?”
“Oh, more or less. But it’s rather firmly fixed in something like a yoga trance, or a lizard’s hibernation. I could activate it for you—but it’s ten to seven. We don’t want to keep the others waiting at the table now, do we?”
She looked away from the figure in glass to the dull, taut skin of the Baron’s face. His jaw, beneath his faintly concave cheek, was involuntarily working on its hinge.
(from Babel-17 by Samuel R. Delany)
Welcome to the sixth and final part of our series on MCAP parsing. In the first four parts, we did all the work to parse certain topic messages from a bag file, going through the file sequentially. In the fifth part, we set up a lot of infrastructure to allow ourselves to instead parse the file using indexing so we can get our messages faster. In this part, we’ll finish the process and see how much faster our code is!
This series has combined a lot of ideas from several of our online courses. You can learn more about complex monad structures in Making Sense of Monads or Effectful Haskell. You can learn more about parsing in Solve.hs. You can get lifetime access to all our courses buy purchasing MMH Complete!
Let’s recap the most important items from the last part and go over our plan again. We defined a series of types to help us represent various record types, and parsers for them:
data FooterRec = ...
parseFooter’ :: parseFooter' :: (MonadParsec Void ByteString m) => m (Word64, FooterRec)
data SummaryOffsetRec = ...
parseSummaryOffset :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, SummaryOffsetRec)
data ChunkIndexRec = ...
parseChunkIndex :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, ChunkIndexRec)
data MessageIndexRec = ...
parseMessageIndex' :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, MessageIndexRec)We also defined a couple monad structures to capture our parser’s state:
data TopicState = TopicState
{ tsChannels :: HM.HashMap Word16 MsgChannel
, tsSchemas :: HM.HashMap Word16 MsgSchema
, tsMessages :: HM.HashMap (ByteString, ByteString) [MessageData]
, tsDesiredTopics :: HS.HashSet ByteString
, tsDesiredChannels :: HS.HashSet Word16
} deriving (Show)
type MCAPReader a = StateT TopicState (ReaderT Handle (ExceptT ValidationError IO)) a
type MCAPParser a = ParsecT Void ByteString (StateT TopicState (ReaderT Handle (ExceptT ValidationError IO))) aFinally, we defined a series of utility functions on these monads:
seek :: Integer -> MCAPReader ()
curPos :: MCAPReader Integer
mcapGuard :: String -> Bool -> MCAPReader ()
runMCAPParser :: MCAPParser (Word64, a) -> ByteString -> MCAPReader (Word64, a)
parseNextRecord :: RecordType -> MCAPParser (Word64, a) -> MCAPReader (Word64, a)
parseNextRecord' :: RecordType -> (Word64 -> MCAPParser (Word64, a)) -> MCAPReader (Word64, a)
runMCAPReader :: Handle -> TopicState -> MCAPReader a -> IO (Either ValidationError TopicState)Our overall plan is:
TopicStateLet’s get started!
Our entrypoint for the MCAPReader monad will be a function called parseUsingIndex (we’ll see how to enter this function later).
parseUsingIndex :: MCAPReader ()The first order of business is to seek to the Footer’s location so we can parse the Footer record. The Footer has a fixed size and it is always the last record before the 8 “magic bytes” that conclude the file. This size is 29 bytes: 1 byte for the op code (record type), 8 bytes to define the content size, and 20 bytes for the 3 fields (Word64, Word64, Word32). Combined with the magic bytes, this means we want to find the file size and seek to 37 bytes before it:
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
footerStart <- seekToFooterStart
...
where
seekToFooterStart = do
hndl <- ask
sz <- liftIO $ hFileSize hndl
seek (sz - 37)
curPosNow we use parseNextRecord and parseFooter’ to get the Footer’s data, which includes the start of the summary offset section. We unpack this value and seek to its location:
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
footerStart <- seekToFooterStart
(_, FooterRec summStart summOffStart _) <- parseNextRecord FileFooter parseFooter'
seek (fromIntegral summOffStart)
...
where
seekToFooterStart = do
hndl <- ask
sz <- liftIO $ hFileSize hndl
seek (sz - 37)
curPosNow we’re ready for step 2!
Recall that records in the summary section are grouped in blocks, and each summary offset record leads us to the start of the block for a particular op code. We’re interested in the summary records for schemas, channels and chunk indexes. So we want to keep parsing summary offsets until we have all three of these.
So we’ll build a helper function that will construct a map from op codes to summary offset records, but also track booleans for which of our desired types we’ve seen. This function also needs to track the number of bytes remaining in the summary offset section:
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
footerStart <- seekToFooterStart
(_, FooterRec summStart summOffStart _) <- parseNextRecord FileFooter parseFooter'
seek (fromIntegral summOffStart)
...
where
parseSummaryOffsets :: Word64 -> Bool -> Bool -> Bool -> M.Map RecordType SummaryOffsetRec -> MCAPReader (M.Map RecordType SummaryOffsetRec)
...There are two base cases. If we are out of bytes, we return our accumulated map. If all three boolean flags are true, then we can also return the map, as we have what we need.
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
...
where
parseSummaryOffsets :: Word64 -> Bool -> Bool -> Bool -> M.Map RecordType SummaryOffsetRec -> MCAPReader (M.Map RecordType SummaryOffsetRec)
parseSummaryOffsets 0 _ _ _ acc = return acc
parseSummaryOffsets _ True True True acc = return acc
parseSummaryOffsets remBytes hasSchema hasChannel hasChunkIndex acc =
...For the general case, we use parseSummaryOffset to parse the next record. We update our boolean flags depending on the op code, and we insert the new record into our map. Then we recurse:
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
...
where
parseSummaryOffsets :: Word64 -> Bool -> Bool -> Bool -> M.Map RecordType SummaryOffsetRec -> MCAPReader (M.Map RecordType SummaryOffsetRec)
parseSummaryOffsets 0 _ _ _ acc = return acc
parseSummaryOffsets _ True True True acc = return acc
parseSummaryOffsets remBytes hasSchema hasChannel hasChunkIndex acc = do
mcapGuard ("Not enough bytes for summary offset: " <> show remBytes) (remBytes >= 26)
(_, summ@(SummaryOffsetRec op _ _)) <- parseNextRecord SummaryOffset parseSummaryOffset
let hasSchema' = hasSchema || op == Schema
let hasChannel' = hasChannel || op == Channel
let hasChunkIndex' = hasChunkIndex || op == ChunkIndex
let mp = M.insert op summ acc
parseSummaryOffsets (remBytes - 26) hasSchema' hasChannel' hasChunkIndex' mpNow we’ll define a second helper. This will use the Maybe monad to extract the 3 records we care about.
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
...
where
...
find3Offsets :: M.Map RecordType SummaryOffsetRec -> Maybe (SummaryOffsetRec, SummaryOffsetRec, SummaryOffsetRec)
find3Offsets mp = do
s <- M.lookup Schema mp
c <- M.lookup Channel mp
ci <- M.lookup ChunkIndex mp
return (s, c, ci)Now back in the main line of the function, we’ll get the size of this section (subtract the summary offset start from the footer start position) and call our two helpers. If we don’t have all three maps, we’ll throw a validation error showing what op codes we did find. Otherwise, we have the 3 offsets.
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
footerStart <- seekToFooterStart
(_, FooterRec summStart summOffStart _) <- parseNextRecord FileFooter parseFooter'
seek (fromIntegral summOffStart)
-- Read Summary Offsets until we have Schema, Channel and ChunkIndex
let sz = fromIntegral footerStart - summOffStart
summOffMap <- parseSummaryOffsets sz False False False M.empty
let offsets = find3Offsets summOffMap
case offsets of
Nothing -> throwError (ValidationError $ "Did not find the right summary offsets: " <> show (M.keys summOffMap))
Just (schemaOffset, channelOffset, chunkIndexOffset) -> ...
where
parseSummaryOffsets :: Word64 -> Bool -> Bool -> Bool -> M.Map RecordType SummaryOffsetRec -> MCAPReader (M.Map RecordType SummaryOffsetRec)
find3Offsets :: M.Map RecordType SummaryOffsetRec -> Maybe (SummaryOffsetRec, SummaryOffsetRec, SummaryOffsetRec)Now we’ve got these summary offset records! It’s time to use them to start populating our topic state.
We’ll begin with the schemas and channels. These are fairly easy, since we can rely on previous code for the most part. Recall that we have the functions parseSchema’ and parseChannel’ for parsing individual schema and channel records. We need to update these type signatures to be more generic like so:
parseSchema' :: (MonadParsec Void ByteString m, MS.MonadState TopicState m) => m (Word64, Record)
parseChannel' :: (MonadFail m, MonadParsec Void ByteString m, MS.MonadState TopicState m) => m (Word64, Record)These will work with the MCAPParser monad. They require MonadState TopicState because they’ll save the schemas and channels within our TopicState, rather than requiring us to do anything with the return values.
So we just need to write functions that will look through all the records in the summary block and parse them. Since the summary offset contains the start location and the byte length of all the records, we’ll seek to that location, and then use our tried and true method of parsing until we run out of bytes. Here’s a function to load all the schemas in a group:
loadSchemasForIndex :: SummaryOffsetRec -> MCAPReader ()
loadSchemasForIndex (SummaryOffsetRec _ groupStart groupLen) = do
seek (fromIntegral groupStart)
f groupLen
where
f 0 = return ()
f rem = do
(len, _) <- parseNextRecord Schema parseSchema'
mcapGuard ("Summary schema is too long! " <> show len <> " " <> show rem) (len <= rem)
f (rem - len)And here’s the function for channels:
loadChannelsForIndex :: SummaryOffsetRec -> MCAPReader ()
loadChannelsForIndex (SummaryOffsetRec _ groupStart groupLen) = do
seek (fromIntegral groupStart)
f groupLen
where
f 0 = return ()
f rem = do
(len, _) <- parseNextRecord Channel parseChannel'
mcapGuard ("Summary channel is too long! " <> show len <> " " <> show rem) (len <= rem)
f (rem - len)We simply call these from within parseUsingIndex like so:
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
footerStart <- seekToFooterStart
(_, FooterRec summStart summOffStart _) <- parseNextRecord FileFooter parseFooter'
seek (fromIntegral summOffStart)
-- Read Summary Offsets until we have Schema, Channel and ChunkIndex
let sz = fromIntegral footerStart - summOffStart
summOffMap <- parseSummaryOffsets sz False False False M.empty
let offsets = find3Offsets summOffMap
case offsets of
Nothing -> throwError (ValidationError $ "Did not find the right summary offsets: " <> show (M.keys summOffMap))
Just (schemaOffset, channelOffset, chunkIndexOffset) -> do
loadSchemasForIndex schemaOffset
loadChannelsForIndex channelOffset
...Now our internal TopicState is updated with the schemas and channels. This means we’re ready to parse messages, but we need to find where those messages are first!
Now we need to process each Chunk Index record. We’ll write a function for this, and it will be the last thing we need to call from parseUsingIndex:
processChunkIndexes :: SummaryOffsetRec -> MCAPReader ()
parseUsingIndex :: MCAPReader ()
parseUsingIndex = do
footerStart <- seekToFooterStart
(_, FooterRec summStart summOffStart _) <- parseNextRecord FileFooter parseFooter'
seek (fromIntegral summOffStart)
-- Read Summary Offsets until we have Schema, Channel and ChunkIndex
let sz = fromIntegral footerStart - summOffStart
summOffMap <- parseSummaryOffsets sz False False False M.empty
let offsets = find3Offsets summOffMap
case offsets of
Nothing -> throwError (ValidationError $ "Did not find the right summary offsets: " <> show (M.keys summOffMap))
Just (schemaOffset, channelOffset, chunkIndexOffset) -> do
loadSchemasForIndex schemaOffset
loadChannelsForIndex channelOffset
processChunkIndexes chunkIndexOffset
where
...To fill out this function, we follow the same general pattern to loop through these records until we’ve exhausted the bytes:
processChunkIndexes :: SummaryOffsetRec -> MCAPReader ()
processChunkIndexes (SummaryOffsetRec _ groupStart groupLen) = do
seek (fromIntegral groupStart)
f groupLen
where
f 0 = return ()
f rem = do
(len, ci) <- parseNextRecord ChunkIndex parseChunkIndex
...The trick is that processing each individual chunk index is more complicated after we’ve parsed it. Each chunk index refers to a single Chunk record and contains its initial position (we saved this in the cirChunkStartOffset field). However, the message index offsets are not absolute positions. They are relative to the start of the data section of the chunk. So we want to calculate where this location is (and it took me a bit of debugging to get it right!).
Prior to the data section in the chunk is the record header, which is 9 bytes. Then there are 32 fixed bytes, followed by the compression string. Then there are still 8 more bytes after that because the data section in the chunk is prefixed by the byte count. You can consult the Chunk record specification to see where these numbers are coming from. So putting it all together, we take the chunk start location, add 49 bytes, and then add the length of the compression string.
processChunkIndexes :: SummaryOffsetRec -> MCAPReader ()
processChunkIndexes (SummaryOffsetRec _ groupStart groupLen) = do
seek (fromIntegral groupStart)
f groupLen
where
f 0 = return ()
f rem = do
(len, ci) <- parseNextRecord ChunkIndex parseChunkIndex
let chunkDataStart = cirChunkStartOffset ci + 49 + (fromIntegral $ BS.length (cirCompression ci))
savedPosition <- curPos
... -- Process message index records
seek savedPositionYou’ll also see that we save the current handle position. We’ll process the message index records and jump around to the messages. But we want to return to the current location (the location after parsing this chunk index) so that we can process the next chunk index afterward.
Now we have to look through all of our desired channels and see which of them are referred to in the cirMessageIndexOffsets of this chunk index:
processChunkIndexes :: SummaryOffsetRec -> MCAPReader ()
processChunkIndexes (SummaryOffsetRec _ groupStart groupLen) = do
seek (fromIntegral groupStart)
f groupLen
where
f 0 = return ()
f rem = do
(len, ci) <- parseNextRecord ChunkIndex parseChunkIndex
let chunkDataStart = cirChunkStartOffset ci + 49 + (fromIntegral $ BS.length (cirCompression ci))
savedPosition <- curPos
chans <- MS.gets tsDesiredChannels
let allMIO = cirMessageIndexOffsets ci
forM_ chans $ \chanId -> when (HM.member chanId allMIO) $ do
...
seek savedPositionNow we get the offset for this channel in the map. This will give us the (absolute) location of the Message Index record for this channel. We’ll prepare a new function to process this message index:
processChunkIndexes :: SummaryOffsetRec -> MCAPReader ()
processChunkIndexes (SummaryOffsetRec _ groupStart groupLen) = do
seek (fromIntegral groupStart)
f groupLen
where
f 0 = return ()
f rem = do
(len, ci) <- parseNextRecord ChunkIndex parseChunkIndex
let chunkDataStart = cirChunkStartOffset ci + 49 + (fromIntegral $ BS.length (cirCompression ci))
savedPosition <- curPos
chans <- MS.gets tsDesiredChannels
let allMIO = cirMessageIndexOffsets ci
forM_ chans $ \chanId -> when (HM.member chanId allMIO) $ do
let chanOffset = allMIO HM.! chanId
loadMessagesFromMessageIndex chanId chanOffset chunkDataStart
seek savedPosition
loadMessagesFromMessageIndex :: Word16 -> Word64 -> Word64 -> MCAPReader ()
loadMessagesFromMessageIndex chanId offset chunkDataStartThis is all we need for processChunkIndexes. We’re getting closer to our goal! Now we need to process the message index record.
You’ll note from above that we passed the channel ID, the offset of the message index, and the corresponding “chunk data start”. We begin this function by seeking the to message index location, parsing the message index, and ensuring that we are getting an index for the correct channel:
loadMessagesFromMessageIndex :: Word16 -> Word64 -> Word64 -> MCAPReader ()
loadMessagesFromMessageIndex chanId offset chunkDataStart = do
seek (fromIntegral offset)
(_, MessageIndexRec mirChanId recs) <- parseNextRecord MessageIndex parseMessageIndex'
mcapGuard ("Mismatched channels for message index record: " <> show chanId <> " " <> show mirChanId) (mirChanId == chanId)
...Now we loop through the record tuples in the message index record. Each of these contains a relative offset. We just need to seek to that offset, adding in the chunk data start location. Then we can use our message parser function!
loadMessagesFromMessageIndex :: Word16 -> Word64 -> Word64 -> MCAPReader ()
loadMessagesFromMessageIndex chanId offset chunkDataStart = do
seek (fromIntegral offset)
(_, MessageIndexRec mirChanId recs) <- parseNextRecord MessageIndex parseMessageIndex'
mcapGuard ("Mismatched channels for message index record: " <> show chanId <> " " <> show mirChanId) (mirChanId == chanId)
forM_ recs $ \(_, offset) -> do
seek (fromIntegral $ chunkDataStart + offset)
parseNextRecord' Message parseMessage'
parseMessage' :: (MonadParsec Void ByteString m, MS.MonadState TopicState m, MonadFail m) => Word64 -> m (Word64, Record)That’s all we need! Like our schema and channel parsers, parseMessage’ does the work of saving the messages in our TopicState, so we don’t need to return or process anything. The path we started from parseUsingIndex is now complete!
As an important note, this code takes a shortcut. The approach given will only work with uncompressed chunks! The relative offset we used for the message index is actually the offset from the start of the uncompressed data. If the chunk’s data is compressed, we would have to grab that whole uncompressed string, decompress as much of it as we need, and then jump to particular locations within that bytestring. The code required to do this efficiently is much more intricate, as it requires us to manage counts on the streams of compressed and uncompressed data.
This highlights an important tradeoff. By leaving the data uncompressed, it takes up more storage space and would take longer to send over a network if you need to download these bag files. But if the data is compressed, we might have to decompress a significant portion of it to find the few messages we care about, meaning we don’t see the same gains in bag read time. The particular needs of your application & systems will determine what choice makes sense.
Now we need an entrypoint to call parseUsingIndex. Our function will take the filepath, open a handle to it, and create the initial topic state, looking for the /turtle1/cmd_vel topic. We’ll invoke the parseUsingIndex function with runMCAPParser:
parseRecordsFromFileWithIndex :: FilePath -> IO ()
parseRecordsFromFileWithIndex fp = do
parseBareRecordsFromFile
startTime <- getCurrentTime
handle <- openFile fp ReadMode
let initialTs = TopicState HM.empty HM.empty HM.empty (HS.fromList ["/turtle1/cmd_vel"]) HS.empty
result <- runMCAPReader handle initialTs parseUsingIndex
...Then, in a reprisal of previous code, we’ll loop through all the messages for our topic (they use the geometry_msgs/msg/Twist type from ROS2), and decode them all. (Recall that in the previous part we wrote parseVelMsg for this type).
parseRecordsFromFileWithIndex :: FilePath -> IO ()
parseRecordsFromFileWithIndex fp = do
startTime <- getCurrentTime
handle <- openFile fp ReadMode
let initialTs = TopicState HM.empty HM.empty HM.empty (HS.fromList ["/turtle1/cmd_vel"]) HS.empty
result <- runMCAPReader handle initialTs parseUsingIndex
case result of
Left e -> print e
Right finalTs -> do
let velMessages = fromMaybe [] $ HM.lookup ("/turtle1/cmd_vel", "geometry_msgs/msg/Twist") (tsMessages finalTs)
forM_ velMessages $ \(MessageData t1 t2 msg) -> do
parseVelResult <- evalStateT (runParserT parseVelMsg "Velocity" msg) 0
case parseVelResult of
Left e -> print e
Right s -> putStrLn $ "Parsed Velocity Message: " <> show t1 <> " " <> show t2 <> " " <> show s
endTime <- getCurrentTime
print (diffUTCTime endTime startTime)And now we’re done! We added some timing features, so we can compare this to our previous run. It is much faster! The original takes around 0.075s. The new version takes about 0.001s. So it’s about 75x faster, a great speedup!
This concludes our series on ROS2 bag parsing! Over the course of this long series, we were able to take an MCAP bag file, parse topic messages out of it, and then use the indexing features to do this even faster! We learn a ton about the MCAP format as well as CDR encoding. We saw how to compose parsers, even when they had stateful side effects like file seeking or saving message data.
With so much ground to cover, there wasn’t a lot of time in this series to go over the basics. If you want to solidify your Haskell skills so that you can write advanced code like this, the best way to do that is to take a look at some of our courses.
The most immediately useful for this series would be Solve.hs. Module 1 teaches you valuable loop structures that form the building block for all of our complicated functions in Haskell. Then Module 4 will teach you about parsing and Megaparsec! In between, you’ll also learn about Data Structures and Algorithms in Haskell!
Making Sense of Monads and Effectful Haskell are also great choices if the monad structures in the second half of the series are a bit confusing to you. You can grab both of these courses for a discount by purchasing the Effects Bundle!
Finally, if you want access to all our course content, past, present and future, you can get the MMH Complete bundle! This will include all the previous courses, as well as our other full length courses Haskell From Scratch, Practical Haskell, plus our mini-course on machine learning, Haskell Brain.
The GHC developers are very pleased to announce the release of GHC 9.12.3. Binary distributions, source distributions, and documentation are available at downloads.haskell.org.
GHC 9.12.3 is a bug-fix release fixing many issues of a variety of severities and scopes, including:
A full accounting of these fixes can be found in the release notes. As always, GHC’s release status, including planned future releases, can be found on the GHC Wiki status.
GHC development is sponsored by:
We would like to thank these sponsors and other anonymous contributors whose on-going financial and in-kind support has facilitated GHC maintenance and release management over the years. Finally, this release would not have been possible without the hundreds of open-source contributors whose work comprise this release.
As always, do give this release a try and open a ticket if you see anything amiss.
Merry Christmas all! This is my annual Advent of Code post! Advent of Code is a series of (this year) 12 daily Christmas-themed programming puzzles that are meant to be fun diversions from your daily life, help you find a bit of whimsy in your world, give you a chance to explore new ideas and program together with your friends. I always enjoy discussing creative ways to solve these puzzles every day, and it’s become a bit of an annual highlight for me and a lot of others. My favorite part about these puzzles is that they are open ended enough that there are usually many different interesting ways to solve them — it’s not like a stressful interview question where you have to recite the obscure incantation to pass the test. In the past I’ve leveraged group theory, galilean transformations and linear algebra, and more group theory.
Haskell is especially fun for these because if you set up your abstractions in just the right way, the puzzles seem to solve themselves. It’s a good opportunity every year to get exposed to different parts of the Haskell ecosystem! Last year, I moved almost all of my Haskell code to an Advent of Code Megarepo, and I also write up my favorite ways to solve each one in the megarepo wiki.
All of this year’s 12 puzzles are
here, but I’ve also included links to each individual one in this post. I’m
also considering expanding some of these into full on blog posts, so be on the
look out, or let me know if there are any that you might want fully expanded!
And if you haven’t, why not try these out yourself? Be sure to drop by the
libera-chat ##advent-of-code channel to discuss any fun ways you
solve them, or any questions! Thanks again to Eric for a great new fresh take on
the event this year!
scanlIntSetStateT + [] = backtracking search
monaddata-interval libraryData.List manipulationsIntervalSet and
IntervalMapIn the first 4 parts of this series (Part 1, Part 2, Part 3, Part 4), we’ve written a program that can parse specific topic information out of MCAP-based ROS2 bags. The Megaparsec library helped us a lot, but our current approach has a weakness; our program scans through the entire file sequentially. Bag files can be very large! So if we’re only interested in a few topics, it can be wasteful to parse through everything.
This is where indexes come in. In the final two parts of this series, we’ll see how we can use MCAP’s indexing features to quickly locate the messages we’re interested in. In this part, we’ll focus on the monadic structure of our code, because this will need to change quite a bit. We’ll also talk about the high-level details of the solution approach. In the next part, we’ll write the code to reach our goal!
In this article, we’ll employ some advanced monad techniques. If you still struggle with understanding monads, you should take our course, Making Sense of Monads! It will help you understand these concepts from the ground up. If you’re more advanced and looking for a challenge, Effectful Haskell is also a great course to try!
Indexing is a technique in many programming applications that allows us to query for certain data more quickly. The term originally comes from books, where any research or historical book has an “Index” section at the back where you can look through a sorted list of people, places and concepts and it will tell you the page(s) where they are mentioned.
In the programming context, you’ll hear about them most often with databases. If you have a “Users” table in your database, it will, by default, be very quick to look up a user with their “primary key”. But you’ll probably also add an “index” on their username or email address field, so that when they login, you can quickly find their information without searching the entire users table.
With MCAP bags, we can use indexing to quickly locate data based on the topic or the timestamp, as these are the most common filtering mechanisms for parsing robotics data. Indexing makes use of a number of the record types we skipped over in previous parts. In these final articles, we’ll use the following record types
To measure our success with indexing, I created a new bag to parse using the Turtlesim node that comes with ROS2 by default. I used this to create a bag file with two topics: /turtle1/pose and /turtle1/cmd_vel.
You don’t need to know much about what these mean, except that our bag has around 12000 messages on the /turtle1/pose topic and only 22 messages on the /turtle1/cmd_vel topic. So if we want to search for the latter topic, we don’t want to process all the pose data.
The velocity topic message type is easy to parse, consisting only of 6 floating point values:
data VelocityMsg = VelocityMsg
{ linearX :: Double
, linearY :: Double
, linearZ :: Double
, angularX :: Double
, angularY :: Double
, angularZ :: Double
} deriving (Show, Eq)
parseVelMsg :: CDRParser VelocityMsg
parseVelMsg = do
parseCdrHeader
d1 <- parseCdrDoubleLE
d2 <- parseCdrDoubleLE
d3 <- parseCdrDoubleLE
d4 <- parseCdrDoubleLE
d5 <- parseCdrDoubleLE
d6 <- parseCdrDoubleLE
return $ VelocityMsg d1 d2 d3 d4 d5 d6We can substitute this type into our code from previous parts, and use a timer to see how long it takes:
parseBareRecordsFromFile :: FilePath -> IO ()
parseBareRecordsFromFile fp = do
t1 <- getCurrentTime
input <- BS.readFile fp
(result, st) <- runStateT (runParserT parseMcapFile' fp input) (TopicState HM.empty HM.empty HM.empty (HS.fromList ["/turtle1/cmd_vel"]) HS.empty)
case result of
Left e -> print e
Right recs -> do
let velMessages = fromMaybe [] $ HM.lookup ("/turtle1/cmd_vel", "geometry_msgs/msg/Twist") (tsMessages st)
forM_ velMessages $ \(MessageData t1 t2 msg) -> do
parseVelResult <- evalStateT (runParserT parseVelMsg "Velocity" msg) 0
case parseVelResult of
Left e -> print e
Right s -> putStrLn $ "Parsed Velocity Message: " <> show t1 <> " " <> show t2 <> " " <> show s
-- forM_ recs $ \(_, rec) -> printRec rec
-- print st
t2 <- getCurrentTime
print (diffUTCTime t2 t1)This will print out all 22 messages, and it takes around 0.08 seconds. That’s not a long time, but it’s also not trivial for a bag spanning a few minutes with only 2 topics. Real ROS bags can contain a LOT more data, and this would slow down our current approach! Our goal in these next two articles is to find these velocity messages much, much faster, in a way that isn’t so dependent on the total bag size.
In the prior part, the only record types we used were Schema, Channel, Chunk and Message. We could basically ignore everything else, simply consuming it based on the content length counts.
To use indexing, we’ll have to acquaint ourselves with 4 new index types:
These records form a kind of data chain that will lead us to the messages we want. From the MCAP specification we can build types to represent the data in each of these records:
data FooterRec = FooterRec
{ summaryStart :: Word64
, summaryOffsetStart :: Word64
, summaryCrc :: Word32
}
deriving (Show, Eq)
data SummaryOffsetRec = SummaryOffsetRec
{ groupOpCode :: RecordType
, groupStart :: Word64
, groupLength :: Word64
} deriving (Show, Eq)
data ChunkIndexRec = ChunkIndexRec
{ cirStartTime :: Word64
, cirEndTime :: Word64
, cirChunkStartOffset :: Word64
, cirChunkLength :: Word64
, cirMessageIndexOffsets :: HM.HashMap Word16 Word64
, cirMessageIndexLength :: Word64
, cirCompression :: ByteString
, cirCompressedSize :: Word64
, cirUncompressedSize :: Word64
} deriving (Show, Eq)
data MessageIndexRec = MessageIndexRec
{ mirChannelId :: Word16
, mirRecords :: [(Word64, Word64)]
} deriving (Show, Eq)Of course, we need code to parse these records, similar to what we wrote for previous record types. These parsers simply make use of primitives we’ve already written, so we won’t dwell on the implementation details. The parsing functions are included at the end of this article in the appendix for completeness.
What we want to understand next is where these record types fit in the context of the whole file.
We introduced the MCAP file structure in the first part of this series, but it’s worth revisiting now that we’re looking at indexing. Here’s the overall structure:
<Magic>
<Header>
<Data section>
[<Summary section>]
[<Summary Offset section>]
<Footer>
<Magic>The magic bytes, header and footer are mandatory. Per the specification, it is possible for an “empty” file to omit all the other sections, but having a single message will require having the “Data Section”. But the summary sections are optional, only included to facilitate indexing. The code we’ll write here will assume they exist.
The “Summary section” can contain schema and channel records. These are identical copies of the schemas and channels we could find in the data section. But the summary section also contains chunk index records, as well as other index record types we won’t discuss. The chunk index records then point to particular chunks in the data section. What is distinct and important about the summary section is that all records are grouped by type. All schema records will be in a single consecutive block, all channel records will be in a single consecutive block, and so on. This sets us up to understand summary offsets.
Each summary offset record gives the location of one of these record type blocks. So we should expect one summary offset for schema records in the summary section, one for channels, and one for chunk indexes.
Finally, we should consider where “Message Index” records live. These are in the data section, and they follow after “Chunk” records. Each message index points us to records for a particular channel in the proceeding chunk.
I mentioned the “data chain” earlier, and now we can start to see how it works looking at the file structure and the fields of these particular records.
That’s the high-level idea, but let’s go into a little more detail, highlighting the exact fields we’ll use to accomplish this.
Before we go any further, it’s important to understand file seeking. Given a numeric offset within a file and a file handle, it is very quick and efficient for us to tell the handle to “seek”, effectively moving it so that it will then parse the next location when we use an operation like getChar. Lots of the fields within our index records are file locations that we’ll seek to.
Knowing this, let’s lay out the details of exactly which fields we’ll use.
First, we use the Footer’s summaryOffsetStart to jump to the beginning of the summary offset section.
Second, we parse records in the summary offset section until we have a SummaryOffsetRec corresponding to Schemas, Channels, and Chunk Indexes.
Third, we use the groupStart field in each SummaryOffsetRec to jump to each of these summary sections in turn. We’ll parse the schemas, and then parse the channels, loading them into our TopicState like we’ve already been doing.
Step 4: We process each Chunk Index record. The cirMessageIndexOffsets field then provides us with a map from channel IDs to the locations of message index records. So we’ll loop through our desired channel IDs (populated in the third step) and, if this chunk has an index for them, we’ll jump to that message index.
Step 5: Process the message index record for our desired channel. The mirRecords field contains an array with one tuple per message in the corresponding chunk. The second value of this tuple is an offset, relative to where the data starts in the chunk. This is the only relative offset in our program…we need to bring forward the cirChunkStartOffset to make sense of this value.
Step 6: Using the chunk start offset and the offsets from the message index, jump to each Message record and parse it, storing its data like we have previously.
These steps will make more sense when we start writing code. We’ll write most of that code in the next part. First though, we have to come to grips with the fact that this whole jumping around business with “seek” is not consistent with how we’ve been parsing with Megaparsec so far!
We’ve written a lot of parsing functions so far with Megaparsec. However, this library assumes we are just walking straight through all the data. It does not supporting seeking at all, especially in the backwards direction.
Our indexing approach requires a lot of seeking, which makes sense. We hop around the file so that we don’t have to parse every individual byte.
The normal way to seek around a file in Haskell is to use a Handle object. Then we can use the hSeek function. It will occasionally also be important to use hTell to get our current position in the file. Then we can use hGet to read as many bytes as we specify into a ByteString.
import System.IO (hSeek, hTell)
import Data.ByteString.Lazy (hGet)
hSeek :: Handle -> Integer -> IO ()
hTell :: Handle -> IO Integer
hGet :: Handle -> Int -> IO ByteStringSo instead of reading the file as a lazy bytestring upfront and passing that to Megaparsec, we want to open up a file handle and use that to move around the file and read bytes on demand. As long as IO is on our monad stack, we can do this.
So can we still use the Parsec functions we’ve written so far in this series? Yes, we can! The solution to this lies in the parameterization we employed last time to use the same parsers with CDR. We just want to replace most of the Parser type signatures with something that captures the requirements of the function, such as MonadParsec and MonadFail. For example, here’s how we re-write the signature for parseArray:
parseArray :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, a) -> m (Word64, [a])A special case occurs with our parsers for Schemas, Channels and Messages. These impact the TopicState value we have wrapped in a StateT layer of our Parser monad. We can also capture this with a monad class! However, we do need a different import for this:
import qualified Control.Monad.State as MS
parseSchema' :: (MonadParsec Void ByteString m, MS.MonadState TopicState m) => m (Word64, Record)Now we can access the state using MS.get and MS.put here.
So our general approach will be to use a different IO-based monad to parse out bytestrings containing record data. We can get all the data up front as a lazy bytestring since record headers contain the length of data we need. Then we pass that bytestring into a new invocation of a parsec-based monad like we did with CDR parsing.
Let’s see how we construct the new monad.
Our previous monad looked like this:
type Parser a = ParsecT Void ByteString (StateT TopicState IO) aThis parser has 3 features: parsing a bytestring, making stateful updates to the TopicState, and allowing IO for debugging.
Our desired monad doesn’t have parsec as a feature, but it still requires using TopicState and IO. However we have two new features.
First, we want to track a Handle. We will use this to seek around the file and read from it. This sounds stateful, but because IO handles the “state” part of the handle, we actually only need the handle wrapped in a Reader layer. This could give us a monad like this:
type MCAPReader a = StateT TopicState (ReaderT Handle IO) aWe’ll add one more layer to this though. The ParsecT gave us a graceful layer for MonadFail, causing it to return a Left value instead of Right at the end. The IO monad also has this, but it’s not as graceful, causing a program crash. So we’ll add an ExceptT layer. This will allow us to use throwError on a custom error type so that we can have more graceful error handling.
data ValidationError = ValidationError String
deriving (Show, Eq, Exception)
type MCAPReader a = StateT TopicState (ReaderT Handle (ExceptT ValidationError IO)) aWe can further build another monad MCAPParser, which will put a ParsecT layer on top of MCAPReader. This will serve as the bridge between our new code and the old code.
type MCAPParser a = ParsecT Void ByteString (StateT TopicState (ReaderT Handle (ExceptT ValidationError IO))) aSince it has ParsecT on top, we can call our existing functions with any function that has an MCAPParser signature! To see this in action, let’s start writing some utility functions for this monad.
So let’s wrap up this article by writing some functions for our new monad that we can use across the board. To start, we’ll write wrappers for hSeek and hTell, so that we don’t have to constantly use ask and liftIO in our code:
seek :: Integer -> MCAPReader ()
seek pos = do
hndl <- ask
liftIO (hSeek hndl AbsoluteSeek pos)
curPos :: MCAPReader Integer
curPos = do
hndl <- ask
liftIO (hTell hndl)Next, let’s add some functions to handle failure cases. These resemble what we already have for guard’. We’ll use throwError on a ValidationError and include the current handle location as part of the error.
failParse :: String -> MCAPReader ()
failParse str = throwError (ValidationError str)
mcapGuard :: String -> Bool -> MCAPReader ()
mcapGuard str cond = do
p <- curPos
unless cond $ failParse (str <> " " <> show p)Now let’s write a function to run a “Parser” from our “Reader” monad, given a bytestring. We use runParserT, and if the result is Left, we throw a ValidationError. Otherwise we return the result. We’ll be able to pass any of our existing parsers to this function!
runMCAPParser :: MCAPParser (Word64, a) -> ByteString -> MCAPReader (Word64, a)
runMCAPParser parser dataBytes = do
parseResult <- runParserT parser "MCAP" dataBytes
case parseResult of
Left e -> throwError (ValidationError (show e))
Right result -> return resultNow let’s get into the meat of how we use this. We want to generalize the process of parsing a record in our reader monad. The issue with runMCAPParser is that it requires the Bytestring for the body for the record. So we need to actually load those characters. So we’ll wrap it with another function parseNextRecord. This function will take a general parser function as (Word64 -> MCAPParser (Word64, a)).
parseNextRecord' :: RecordType -> (Word64 -> MCAPParser (Word64, a)) -> MCAPReader (Word64, a)
parseNextRecord’ = undefinedWe need this extra Word64 parameter strictly for parseMessage, which needs the content length to parse the body. However, our other record parsers can rely on this version, which ignores the parameter:
parseNextRecord :: RecordType -> MCAPParser (Word64, a) -> MCAPReader (Word64, a)
parseNextRecord typ parser = parseNextRecord' typ (const parser)So how do we actually parse the record? Remember we’ll use hGet to actually parse a certain number of characters. We start with 1 character, for the record’s type. We’ll compare this to the input record type to make sure we’re parsing the expected record:
parseNextRecord' :: RecordType -> (Word64 -> MCAPParser (Word64, a)) -> MCAPReader (Word64, a)
parseNextRecord' typ parser = do
hndl <- ask
recordByte <- liftIO $ BS.hGet hndl 1
(n1, recordType) <- runMCAPParser parseRecordType' recordByte
mcapGuard ("Unexpeted record type: " <> show recordType <> " " <> show typ) (recordType == typ)
...Now we’ll do the same thing for the 8-byte record content length.
parseNextRecord' :: RecordType -> (Word64 -> MCAPParser (Word64, a)) -> MCAPReader (Word64, a)
parseNextRecord' typ parser = do
hndl <- ask
recordByte <- liftIO $ BS.hGet hndl 1
(n1, recordType) <- runMCAPParser parseRecordType' recordByte
mcapGuard ("Unexpeted record type: " <> show recordType <> " " <> show typ) (recordType == typ)
lenBytes <- liftIO $ BS.hGet hndl 8
(n2, contentLength) <- runMCAPParser parseUint64LE lenBytes
...Finally, we load the next bytes based on contentLength and pass them to our parser using runMCAPParser above!
parseNextRecord' :: RecordType -> (Word64 -> MCAPParser (Word64, a)) -> MCAPReader (Word64, a)
parseNextRecord' typ parser = do
hndl <- ask
recordByte <- liftIO $ BS.hGet hndl 1
(n1, recordType) <- runMCAPParser parseRecordType' recordByte
mcapGuard ("Unexpeted record type: " <> show recordType <> " " <> show typ) (recordType == typ)
lenBytes <- liftIO $ BS.hGet hndl 8
(n2, contentLength) <- runMCAPParser parseUint64LE lenBytes
contentBytes <- liftIO $ BS.hGet hndl (fromIntegral contentLength)
(n3, record) <- runMCAPParser (parser contentLength) contentBytes
return (n1 + n2 + n3, record)An important note on parseNextRecord is that it depends on us already being in the right file location. So we’ll have to seek before calling this. But we’ll handle those details next time.
For now, let’s finish this article by writing a run function for our monad. This will dispatch to the run functions for our sub-monads like execStateT and runExceptT.
runMCAPReader :: Handle -> TopicState -> MCAPReader a -> IO (Either ValidationError TopicState)
runMCAPReader handle ts parser = runExceptT (runReaderT (execStateT parser ts) handle)Now we have all the tools we’ll need for next time!
In this article, we learned more about the structure of an MCAP bag, particularly how various record types facilitate indexing so we can access desired topic data more quickly. We also built a new monad stack to use to help us jump around the file more quickly. In the next and final part of this ROS2 series, we’ll implement the remaining details of using these index records to find our topic data!
Up til now, this series has focused on parsing mechanics. But this article centered more on monad composition, which can be a tricky topic. To learn more about monads, including how to build useful monad stacks, you can take a look at 2 of our courses. Making Sense of Monads is geared more towards beginners, and Effectful Haskell is a more advanced course for those trying to take their understanding of monads to the next level. You can get both of these by purchasing our Effects Bundle!
Note how these use the generalized monad structure we discussed in this article (MonadParsec, MonadFail).
parseFooter' :: (MonadParsec Void ByteString m) => m (Word64, FooterRec)
parseFooter' = do
(n1, summaryStart) <- parseUint64LE
(n2, summaryOffsetStart) <- parseUint64LE
(n3, summaryCrc) <- parseUint32LE
return (n1 + n2 + n3, FooterRec summaryStart summaryOffsetStart summaryCrc)
parseSummaryOffset :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, SummaryOffsetRec)
parseSummaryOffset = do
(n1, op) <- parseRecordType'
(n2, gs) <- parseUint64LE
(n3, gl) <- parseUint64LE
return (n1 + n2 + n3, SummaryOffsetRec op gs gl)
parseChunkIndex :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, ChunkIndexRec)
parseChunkIndex = do
(n1, startT) <- parseTimestamp
(n2, endT) <- parseTimestamp
(n3, chunkStart) <- parseUint64LE
(n4, chunkLen) <- parseUint64LE
(n5, offsets) <- parseMap parseUint16LE parseUint64LE
(n6, indexLength) <- parseUint64LE
(n7, compression) <- parseString
(n8, compressedSize) <- parseUint64LE
(n9, uncompressedSize) <- parseUint64LE
let totalLen = n1 + n2 + n3 + n4 + n5 + n6 + n7 + n8 + n9
let rec = ChunkIndexRec startT endT chunkStart chunkLen offsets indexLength compression compressedSize uncompressedSize
return (totalLen, rec)
parseMessageIndex' :: (MonadFail m, MonadParsec Void ByteString m) => m (Word64, MessageIndexRec)
parseMessageIndex' = do
(n1, cid) <- parseUint16LE
(n2, recs) <- parseArray (parseTuple parseUint64LE parseUint64LE)
return (n1 + n2, MessageIndexRec cid recs)I've recently been doing a lot of both submitting and reviewing pull requests to PyTorch that were authored with substantial LLM assistance. This is a big difference from earlier this year, where it was clear LLMs worked well for greenfield projects but the code was too hopelessly sloppy for a production codebase. Here are my merged PRs that mention claude code in their description; Jason Ansel has also had a similar experience (Meta only link, here is the list of issues he referenced in his writeup). There already has been increasing discourse (Simon Willison, LLVM) on how code review should adapt to this new era of LLMs. My contribution to this discourse is this: within teams, code review should change to being primarily be a human alignment mechanism.
Here is a simple example: it is well known that LLMs are prone to generating overly defensive code: e.g., they will be constantly sprinkling try...catch everywhere or testing if a variable is some type when system invariants imply that it should always be that type. If someone sends me a PR with these problems, I am not commenting on these problems solely because I want them to be fixed. If that's all I cared about, I could have just fed my comments directly to claude code. The real problem is that the human who was operating the LLM didn't agree with me that this defensive code was bad, and the point of the review is to align them with me on what is overly defensive versus not. In the most trivial cases, maybe the engineer didn't read the LLM output, in which case the remedy is to make them actually read the code. But sometimes real human work has to happen; for example, maybe there is a global system invariant that one has to understand to know if the defensiveness is necessary or not. If we agree about the global system invariants, there's no reason the code review has to go through me: the original code author can just instruct the LLM to fix problems and keep me out of the loop until they have aligned the LLM output to themselves--at which point we should do the more expensive human to human alignment. The ideal is that I don't need to ever write review comments about mechanical problems, because they have already been fixed by the original author ahead of time.
Conversely, when I am putting up an LLM generated PR for human review, I am trying to transmit higher level information. How does the new code work? What do I need to know about the existing system to understand this code? This doesn't even have to be in the PR description: if the LLM proposes a fix that I myself don't understand, or seems difficult to understand, I will simply instruct it to try it a different way, until the resulting diff is obviously correct. Tokens are cheap: we should expect more out of the author of code, because the cost of generating these PRs has gone way down. Similarly, I am willing to throw out the code and start again; you don't have to feel bad about wasting my time (I didn't type it! I spent my time understanding the problem, and none of that is regretted.)
There is a lot of scaremongering about how engineers who don't pick up AI tools will be left behind. My take on this is that there a number of different skills that make up what it means to be a good software engineer, and it is clear that LLM coding, even today, is clearly reweighting the relative importance of these skills. I care a lot more about your ability to read code, reason about the big picture, communicate clearly and to have good taste, than I care about your ability to mechanically write code. There is an archetype of junior engineer who is not that good at coding but very good at the softer, higher level skills, and I think they will be very valuable in this new world order. Conversely, I think going forward I will have substantially less patience if I have to keep telling you the same things over and over, because I just don't value raw "ability to code" as much anymore. My ideal state is like that with long time senior teammates: I can trust that they have made good low level decisions, and I can focus on understanding the bigger picture and updating my mental model of how the system works.
Today's LLMs have no memory: they have to rediscover everything in the system from first principles every time they are run. The purpose of the humans, of the team, is to collectively maintain a shared vision of what, platonically, the system should do. I want code review to reconfigure itself around this purpose.
The GHC developers are very pleased to announce the release of GHC 9.14.1. Binary distributions, source distributions, and documentation are available at downloads.haskell.org.
GHC 9.14 brings a number of new features and improvements, including:
Significant improvements in specialisation:
SPECIALISE pragma now allows use of type application syntaxSPECIALISE pragma can be used to specialise for expression arguments
as well as type arguments.newtypesSignificant GHCi improvements including:
Implementation of the Explicit Level Imports proposal
RequiredTypeArguments can now be used in more contexts
Greatly improved SSE/AVX2 support in the x86 native code generator backend
Initial native code generator support for LoongArch
The WebAssembly backend now supports evaluation via the interpreter, allowing
GHCi and TemplateHaskell evaluation, including foreign import javascript
usage from within the browser
A new primop annotateStack# for pushing arbitrary data onto the call stack
for later extraction when decoding stack traces
-Wincomplete-record-selectors is now part of -Wall. Libraries compiled
with -Werror may need adjustment.
A major update of the Windows toolchain
Improved compatibility with macOS Tahoe
… and many more
A full accounting of changes can be found in the release notes. See the migration guide for guidance on migrating programs to this release.
Note that while this release makes many improvements in the specialisation
optimisation, polymorphic specialisation remains disabled by default in the
release due to concern over regressions of the sort identified in
#26329. Users needing more aggressive specialisation can explicitly
enable this feature with the -fpolymorphic-specialisation flag. Depending
upon our experience with 9.14.1, we may enable this feature by default in a
later minor release.
GHC development is sponsored by:
We would like to thank these sponsors and other anonymous contributors whose on-going financial and in-kind support has facilitated GHC maintenance and release management over the years. Finally, this release would not have been possible without the hundreds of open-source contributors whose work comprises this release.
As always, do give this release a try and open a ticket if you see anything amiss.
How coarse-grained STM containers can livelock under load
TVar (Map _ _) may be appropriate - I’ve modified the post to incorporate this.Software Transactional Memory (STM) is one of Haskell’s crown jewels. The promise is easy, lock-free concurrency with guaranteed transactional semantics and great performance. Used correctly, you get all of these benefits. However, concurrency is fundamentally difficult, and STM has a failure mode: livelock.
Livelock is when the program is repeatedly retrying transactions - working furiously and making no progress. Livelock is subtle and extremely difficult to diagnose. The problem of livelock is often simply “performance is really bad and seems to get worse with more concurrency.” Avoiding livelock proactively will pay massive dividends in the performance of your concurrent systems, as well as the time spent diagnosing and fixing them later on.
A common causes of livelock is fortunately discoverable with simple text search:
uhoh :: TVar (Map k (TVar v)) -> STM ()
oops :: TVar (HashMap k v) -> STM ()
ohno :: TVar (Set v) -> STM ()
A TVar to a container data structure, like Map k v or Set a or [a] or Seq a, is a common source of livelock.
Any change to the Map invalidates any transaction that is reading from that Map, even if it is reading at a totally different key or value.
If the Map is being concurrently updated, you are nearly guaranteed to run into performance problems.
Fortunately, you can easily avoid this pattern, thanks to the stm-containers library.
stm-containersThe stm-containers package was released over ten years ago.
stm-containers allows you to have a structure similar to a TVar (Map k v) or TVar (Map k (TVar v)) with the added benefit that it actually scales up with increased concurrency, avoiding the dreaded livelock.
Modifications to the map impact a significantly smaller portion of the map structure, so you’re way less likely to run into livelock from concurrent updates.
Switching is really easy.
The API is mostly the same as the containers library, but modifications are effectful in STM () instead of returning the new data structure.
StmMap.lookup
:: (Hashable k)
=> k
-> StmMap.Map k v
-> STM (Maybe v)
HashMap.lookup
:: (Hashable k)
=> k
-> HashMap k v
-> Maybe v
StmMap.insert
:: (Hashable k)
=> v -- note that the value is first, not the key
-> k
-> StmMap.Map k v
-> STM ()
HashMap.insert
:: (Hashable k)
=> k
-> v
-> HashMap k v
-> HashMap k v
Here’s an example of using stm-containers in practice, compared to a TVar Map.
import qualified Data.Map as Map
import qualified StmContainers.Map as StmMap
-- old:
doStuff :: TVar (Map.Map String Int) -> String -> STM Int
doStuff tmap str = do
map <- readTVar tmap
let mval = Map.lookup str map
let newVal = maybe 0 (+1) mval
writeTVar (Map.insert str newVal map)
pure newVal
-- new:
doStuff :: StmMap.Map String Int -> String -> STM Int
doStuff tmap str = do
mval <- StmMap.lookup str tmap
let newVal = maybe 0 (+1) mval
StmMap.insert newVal str tmap
pure newVal
The library also offers an interesting focus function, which allows you to combine operations at a single key into a single operation.
If you’re sharing a Map or Set-like container across many threads, then you almost certainly want to just use stm-containers.
If you stop reading here, and merely use stm-containers by default, then you’ll avoid a lot of pain without having to invest much time or energy.
stm-containers is faster and safer than a TVar (Map k v).
In this PR to the hs-temporal-sdk library, I mechanically translated a few TVar (HashMap _ _) to stm-containers datatypes.
We were observing degraded performance with increased concurrency, some of which were causing an ordinary 10 minute test suite run to time out after 50 minutes.
By switching from TVar (HashMap _ _) to stm-containers, the problem was completely fixed - performance remained consistent with increased concurrency.
stm-containers?By default, you should use stm-containers.
It is very fast, simple to use, and has no downsides (aside from the downsides inherent to STM vs MVar or IORef based shared references).
A TVar (Map k v) isn’t always going to be dangerous.
And that’s part of the problem - there are some places where TVar (Map k v) won’t be slow or break.
These rely on non-local assumptions about your code structure - you cannot enforce this easily without writing complicated wrappers that enforce encapsulation around how the shared reference is used.
Writing code that works great with a TVar (Map k v) in the small is quite easy, but guaranteeing that code won’t break as it scales is challenging.
There are many situations where going from TVar (Map k v) to StmMap.Map k v will make a huge improvement.
There is one known situation where an StmMap.Map k v may run into a significant performance problem - if you need to get a snapshot of the Map atomically, StmMap.Map k v requires reading O(n log n) TVars, and GHC currently is quadratic in the count of TVars in a transaction.
So if you find yourself doing listT :: StmMap.Map k v -> ListT STM [(k, v)], then you may want to consider an alternative structure.
IORef (Map k v)?An IORef (Map k v) eliminates the possibility of livelock.
However, the IORef structure is not suitable for many writers.
To ensure a consistent view of the Map, you need to use atomicModifyIORef.
While a thread is doing an atomicModifyIORef, all other writes are blocked to the reference.
This means that an IORef (Map k v) is suitable if there are relatively few writes to the IORef, and the IORef write is mostly a complete replacement.
If you have many writers doing small writes, then threads will queue up and block on updating the entire Map.
In briefer code snippets,
atomicModifyIORef' (\oldMap -> (Map.union newMap oldMap, ()))atomicModifyIORef' (\oldMap -> (Map.insert k v oldMap, ()))atomicModifyIORef also requires the updating action to be pure.
If you need the modification to be effectful, and have a consistent view of the data, then you need to use either stm-containers or an MVar.
In this PR to the prometheus-haskell library, I demonstrate that an IORef (Map k v) has significantly worse performance than an stm-containers Map k v as concurrency scales up.
This change made a big difference to the performance of our metric collection code.
IORef (Map k v) is not suitable because there are many frequent writes that are only concerned with a single k, and reading is done non-atomically - the value of k0 changing does not impact the value of k1.
MVar (Map k v)?An MVar (Map k v) avoids the problem of livelock, but introduces another potential problem: deadlock.
An MVar is a locking concurrency mechanism, where you can block other threads by takeMVar and making the MVar empty.
This allows updating threads to lock the value, update the MVar, and unlock the value.
However, if your code fails to fill up an MVar, or if two threads are waiting on mutually held MVars, then your code cannot make progress, and will be deadlocked.
One advantage that this has to a TVar is fairness.
Threads that attempt to read or take from an MVar are enqueued, and guaranteed to operate in a first-in-first-out manner.
TVar, on the other hand, will start every thread at once, and the first one to complete wins while everyone else must retry.
If you have multiple MVar variables that you want to coordinate on, then you are increasing the risk of deadlock.
TVar (Map k v) safe?The fundamental problem with TVar (Map k v) is that any write to the TVar will invalidate and retry every transaction that reads from it.
For this variable to be safe, you need a single thread performing updates, and other threads are only doing reads.
Additionally, those updates should ideally be relatively rare - if the thread is constantly updating single keys in the map, that will invalidate transactions frequently.
Instead, you’ll want to batch updates to the Map and perform a whole replacement at once.
However, this is exactly the same limitation as IORef (Map k v) or an MVar (Map k v).
If you only have a single TVar (Map k v) involved in your STM transactions, then you can simply switch to an IORef or MVar and enjoy increased performance.
If you have multiple TVar in your transaction, then you are at risk of livelock, and should use stm-containers.
If you really need TVar for STM transactionality, then I would highly recommend wrapping the TVar (Map k v) in a newtype that forbids write operations, and only expose the underlying TVar in a manner that allows for a single thread to do infrequent writes.
This will avoid contention and livelock.
TVar (Map k (TVar v)) safe?TVar (Map k (TVar v)) is slightly better than the above.
With this, any write to the top-level TVar will invalidate the transaction, but writes to the value TVars will only cause contention on other transactions that are attempting to write to it.
For this to be safe, you must have a single thread that updates the Map structure (ie adding or removing keys).
Many threads can write on the map values and only experience the usual contention on a single variable.
However, this runs into the same problem as above: if you can safely refactor this to IORef (Map k (TVar v)) (or MVar), then you are safe, otherwise, you are at risk of livelock and you should switch to stm-containers.
I love arguing semantics. What else are we going to argue about, syntax?
If I say IORef a, I mean:
This is a reference to an
a. The reference may be read or written to from any thread. The reference is very fast for these operations. However, the only operation for atomic consistency isatomicModifyIORef. So do not expect to be able to do transactions or blocking with this!
We have a very fast reference with very few guarantees. This is suitable for sharing information among many threads, where updates don’t happen very often, and updates are fast and pure.
Meanwhile, if I say MVar a, I mean:
This is a reference to an
a, which may be full or empty. The reference may be read or written to from any thread. If the reference is empty, then other threads will queue up and wait for it to be full. This means I can implement control, atomic updates, and fair access. However, it also means that I can experience deadlock and blocking performance.
Now, when writing code against an MVar, we have to be more careful: we can cause deadlock.
But we also have significantly more power over how the data is accessed and updated.
Particularly fairness and coordination are powerful advantages for the MVar.
However, transactions with multiple MVar are difficult to do correctly.
Where IORefs atomicModifyIORef requires a pure computation to avoid data races, you can takeMVar on an MVar to do an update - this allows you to do effects while computing your new value, and guarantees that consumers receive a consistent view of the value inside the MVar.
If I say TVar a, I mean:
This is a reference to an
a. The reference may be read or written to from any thread. I want transactionality around the entire structure ofa- that is, if anyone touches any part of the structure ofa, I want my whole transaction to be invalidated.
This last bit is actually a very strong claim!
Are you sure you want transactionality around the entire a?
For a TVar Int, the answer is yes.
But for a TVar (Map k v), your transaction probably is only concerned with specific parts of the Map.
stm-containers uses a strategy similar to TChan and TQueue - rather than a TVar containing a recursive data structure, the actual recursive steps are themselves TVars.
This allows modifications to the data structure to only invalidate transactions that are actually relevant.
Consider a SQL transaction. If you have a query which selects a row from a table, you want to have some sort of locking to ensure that the row remains the same throughout the transaction. Locking the entire table would be disastrous for performance - no one could do any work on the table until your transaction was complete! Locking the entire row can also be quite bad for performance if the row is large. But if you only select a handful of columns, ideally only those columns are locked by the query.
STM is a wonderful mechanism for concurrency, but it isn’t foolproof.
We are still responsible for selecting the right data structures for good performance.
The core issue here is coarse-grained transactional state.
Finer transactionality gives us better performance.
{kind=link}